
The relationship between the different modes of convergence of random variables is one of the more important topics in any introduction to probability theory. For some reason, many of the textbooks leave the proofs as exercises, so it seems worthwhile to present a sketched but comprehensive summary.
Almost sure convergence: 

Convergence in Probability: 
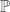
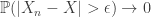

Convergence in Distribution: 


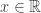

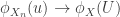

Note: In contrast to the other conditions for convergence, convergence in distribution (also known as weak convergence) doesn’t require the RVs to be defined on the same probability space. This thought can be useful when constructing counterexamples.



Uniform Integrability: Informally, a set of RVs is UI if the integrals over small sets tend to zero uniformly. Formally: 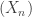
![\sup_{n,A\in\mathcal{F}}\{\mathbb{E}[|X_n|1(A)]|\mathbb{P}(A)\leq \delta\}\rightarrow 0](https://s0.wp.com/latex.php?latex=%5Csup_%7Bn%2CA%5Cin%5Cmathcal%7BF%7D%7D%5C%7B%5Cmathbb%7BE%7D%5B%7CX_n%7C1%28A%29%5D%7C%5Cmathbb%7BP%7D%28A%29%5Cleq+%5Cdelta%5C%7D%5Crightarrow+0&bg=ffffff&fg=333333&s=0&c=20201002)

Note: In particular, a single RV, and a collection of independent RVs are UI. If X~U[0,1] and 
THEOREM 1: Almost-sure convergence implies convergence in probability.
THEOREM 2: Convergence in probability means exists a subsequence on which there is almost sure convergence.
THEOREM 3: Convergence in probability implies convergence in distribution.
THEOREM 4: Convergence in 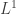
THEOREM 5: Convergence in 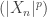
Remark 1: The converse is false. This isn’t hugely surprising if you allow the 
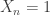
Proof 1:

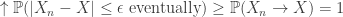
Proof 2: There exists an increasing sequence 
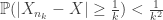
Remark 3: The converse is obviously false. Eg, take i.i.d. 
Proof 3: By bounded convergence, almost sure convergence implies convergence in distribution (by the conditions on f). Given convergence in probability, have convergence almost surely on a subsequence of any subsequence. If we didn’t have convergence in distribution, there would be a subsequence for which the appropriate expectation expression was bounded away from 0. By the two remarks, this can’t be the case.
Remark 4: Convergence in 
Proof 4: 
Remark 5: The example given in the definition of UI, is a counterexample to the converse of Theorem 4. Essentially, uniform integrability is precisely what you need to make Theorem 5 hold.
Proof 5: WLOG assume p=1. 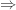
![\mathbb{E}[|X_n|1(A)]\leq \mathbb{E}|X_n-X|+\mathbb{E}[|X|1(A)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%7CX_n%7C1%28A%29%5D%5Cleq+%5Cmathbb%7BE%7D%7CX_n-X%7C%2B%5Cmathbb%7BE%7D%5B%7CX%7C1%28A%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

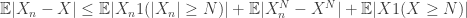


Pingback: Distribution function and weak convergence | Blog about Statistics.
Pingback: Convergence in probability, convergence almost surely and the continuous mapping theorem | Blog about Statistics.
Pingback: 100k Views | Eventually Almost Everywhere