A long time ago, I wrote quite a few a things about uniform trees. That is, a uniform choice from the  unrooted trees with vertex set [n]. This enumeration, normally called Cayley’s formula, has several elegant arguments, including the classical Prufer bijection. But making a uniform choice from a large set is awkward, and so we seek more probabilistic methods to sample such a tree, which might also give insight into the structure of a ‘typical’ uniform tree.
unrooted trees with vertex set [n]. This enumeration, normally called Cayley’s formula, has several elegant arguments, including the classical Prufer bijection. But making a uniform choice from a large set is awkward, and so we seek more probabilistic methods to sample such a tree, which might also give insight into the structure of a ‘typical’ uniform tree.
In another historic post, I talked about the Aldous-Broder algorithm. Here’s a quick summary. We run a random walk on the complete graph 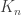 started from a uniformly-chosen vertex. Every time we arrive at a vertex we haven’t visited before, we record the edge just traversed. Eventually we have visited all n vertices, so have recorded n-1 edges. It’s easy enough to convince yourself that these n-1 edges form a tree (how could there be a cycle?) and a bit more complicated to decide that the distribution of this tree is uniform.
started from a uniformly-chosen vertex. Every time we arrive at a vertex we haven’t visited before, we record the edge just traversed. Eventually we have visited all n vertices, so have recorded n-1 edges. It’s easy enough to convince yourself that these n-1 edges form a tree (how could there be a cycle?) and a bit more complicated to decide that the distribution of this tree is uniform.
It’s worth noting that this algorithm works to construct a uniform spanning tree on any connected base graph.
This post is about a few alternative constructions and interpretations of the uniform random tree. The first construction uses a Galton-Watson process. We take a Galton-Watson process where the offspring distribution is Poisson(1), and condition that the total population size is n. The resulting random tree has a root but no labels, however if we assign labels in [n] uniformly at random, the resulting rooted tree has the uniform distribution among rooted trees on [n].
Proof
This is all about moving from ordered trees to non-ordered trees. That is, when setting up a Galton-Watson tree, we distinguish between the following two trees, drawn extremely roughly in Paint:

That is, it matters which of the first-generation vertices have three children. Anyway, for such a (rooted) ordered tree T with n vertices, the probability that the Galton-Watson process ends up equal to T is

where  is the number of children of a vertex
is the number of children of a vertex  . Then, since
. Then, since 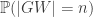 is a function of n, we find
is a function of n, we find
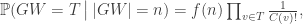
where f(n) is a function of n alone (ie depends on T only through its size n).
But given an unordered rooted tree t, labelled by [n], there are  ordered trees associated to t in the natural way. Furthermore, if we take the Poisson Galton-Watson tree conditioned to have total population size n, and label uniformly at random with [n], we obtain any one of these ordered trees with probability
ordered trees associated to t in the natural way. Furthermore, if we take the Poisson Galton-Watson tree conditioned to have total population size n, and label uniformly at random with [n], we obtain any one of these ordered trees with probability  . So the probability that we have t after we forget about the ordering is
. So the probability that we have t after we forget about the ordering is  , which is a function of n alone, and so the distribution is uniform among the set of rooted unordered trees labelled by [n], exactly as required.
, which is a function of n alone, and so the distribution is uniform among the set of rooted unordered trees labelled by [n], exactly as required.
Heuristic for Poisson offspring distribution
In this proof, the fact that 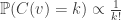 exactly balances the number of orderings of the k children explains why Poisson(1) works out. Indeed, you can see in the proof that Poisson(c) works equally well, though when
exactly balances the number of orderings of the k children explains why Poisson(1) works out. Indeed, you can see in the proof that Poisson(c) works equally well, though when  , the event we are conditioning on (namely that the total population size is n) has probability decaying exponentially in n, whereas for c=1, the branching process is critical, and the probability decays polynomially.
, the event we are conditioning on (namely that the total population size is n) has probability decaying exponentially in n, whereas for c=1, the branching process is critical, and the probability decays polynomially.
We can provide independent motivation though, from the Aldous-Broder construction. Both the conditioned Galton-Watson construction and the A-B algorithm supply the tree with a root, so we’ll keep that, and look at the distribution of the degree of the root as constructed by A-B. Let  be the vertices [n], ordered by their discovery during the construction. Then
be the vertices [n], ordered by their discovery during the construction. Then  is definitely connected by an edge to
is definitely connected by an edge to 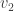 , but thereafter it follows by an elementary check that the probability is connected to
, but thereafter it follows by an elementary check that the probability is connected to 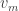 is
is  , independently across all m. In other words, the distribution of the degree of in the tree as constructed by A-B is
, independently across all m. In other words, the distribution of the degree of in the tree as constructed by A-B is
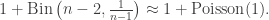
Now, in the Galton-Watson process, conditioning the tree to have fixed, large size changes the offspring distribution of the root. Conveniently though, in a limiting sense it’s the same change as conditioning the tree to have size at least n. Since these events are monotone in n, it’s possible to take a limit of the conditioning events, and interpret the result as the Galton-Watson tree conditioned to survive. It’s a beautiful result that this interpretation can be formalised as a local limit. The limiting spine decomposition consists of an infinite spine, where the offspring distribution is a size-biased version of the original offspring distribution (and so in particular, always has at least one child) and where non-spine vertices have the original distribution.
In particular, the number of the offspring of the root is size-biased, and it is well-known and not hard to check that size-biasing Poisson(c) gives 1+Poisson(c) ! So in fact we have, in an appropriate limiting sense in both objects, a match between the degree distribution of the root in the uniform tree, and in the conditioned Galton-Watson tree.
This isn’t supposed to justify why a conditioned Galton-Watson tree is relevant a priori (especially the unconditional independence of degrees), but it does explain why Poisson offspring distributions are relevant.
Construction via G(N,p) and the random cluster model
The main reason uniform trees were important to my thesis was their appearance in the Erdos-Renyi random graph G(N,p). The probability that vertices {1, …, n} form a tree component in G(N,p) with some particular structure is

Here, the first two terms give the probability that the graph structure on {1, …, n} is correct, and the the final term gives the probability of the (independent) event that these vertices are not connected to anything else in the graph. In particular, this has no dependence on the tree structure chosen on [n] (for example, whether it should be a path or a star – both examples of trees). So the conditional distribution is uniform among all trees.
If we work in some limiting regime, where  (for example if n is fixed and
(for example if n is fixed and  ), then we can get away asymptotically with less strong conditioning. Suppose we condition instead just that [n] form a component. Now, there are more ways to form a connected graph with one cycle on [n] than there are trees on [n], but the former all require an extra edge, and so the probability that a given one such tree-with-extra-edge appears as the restriction to [n] in G(N,p) is asymptotically negligible compared to the probability that the restriction to [n] of G(N,p) is a tree. Naturally, the local limit of components in G(N,c/N) is a Poisson(c) Galton-Watson branching process, and so this is all consistent with the original construction.
), then we can get away asymptotically with less strong conditioning. Suppose we condition instead just that [n] form a component. Now, there are more ways to form a connected graph with one cycle on [n] than there are trees on [n], but the former all require an extra edge, and so the probability that a given one such tree-with-extra-edge appears as the restriction to [n] in G(N,p) is asymptotically negligible compared to the probability that the restriction to [n] of G(N,p) is a tree. Naturally, the local limit of components in G(N,c/N) is a Poisson(c) Galton-Watson branching process, and so this is all consistent with the original construction.
One slightly unsatisfying aspect to this construction is that we have to embed the tree of size [n] within a much larger graph on [N] to see uniform trees. We can’t choose a scaling p=p(n) such that G(n,p) itself concentrates on trees. To guarantee connectivity with high probability, we need to take  , but by this threshold, the graph has (many) cycles with high probability.
, but by this threshold, the graph has (many) cycles with high probability.
At this PIMS summer school in Vancouver, one of the courses is focusing on lattice spin models, including the random cluster model, which we now briefly define. We start with some underlying graph G. From a physical motivation, we might take G to be 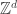 or some finite subset of it, or a d-ary tree, or the complete graph
or some finite subset of it, or a d-ary tree, or the complete graph 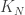 . As in classical bond percolation (note G(N,p) is bond percolation on ), a random subset of the edges of G are included, or declared open. The probability of a given configuration w, with e open edges is proportional to
. As in classical bond percolation (note G(N,p) is bond percolation on ), a random subset of the edges of G are included, or declared open. The probability of a given configuration w, with e open edges is proportional to
 (*)
(*)
where the edge-weight 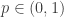 as usual, and cluster weight
as usual, and cluster weight  , and
, and  counts the number of connected components in configuration w. When q=1, we recover classical bond percolation (including G(N,p) ), while for q>1, this cluster-reweighting favours having more components, and q<1 favours fewer components. Note that in the case
counts the number of connected components in configuration w. When q=1, we recover classical bond percolation (including G(N,p) ), while for q>1, this cluster-reweighting favours having more components, and q<1 favours fewer components. Note that in the case  , the normalising constant (or partition function) of (*) is generally intractable to calculate explicitly.
, the normalising constant (or partition function) of (*) is generally intractable to calculate explicitly.
As in the Erdos-Renyi graph, consider fixing the underlying graph G, and taking 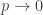 , but also taking
, but also taking  . So the resulting graph asymptotically ‘wants to have as few edges as possible, but really wants to have as few components as possible’. In particular, 1) all spanning trees of G are equally likely; 2) any configuration with more than one component has asymptotically negligible probability relative to any tree; 3) any graph with a cycle has #components + #edges greater than that of a tree, and so is asymptotically negligible probability relative to any tree.
. So the resulting graph asymptotically ‘wants to have as few edges as possible, but really wants to have as few components as possible’. In particular, 1) all spanning trees of G are equally likely; 2) any configuration with more than one component has asymptotically negligible probability relative to any tree; 3) any graph with a cycle has #components + #edges greater than that of a tree, and so is asymptotically negligible probability relative to any tree.
In other words, the limit of the distribution is the uniform spanning tree of G, and so this (like Aldous-Broder) is a substantial generalisation, which constructs the uniform random tree in the special case where  .
.

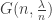



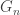
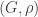


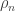

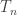


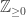
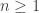
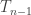


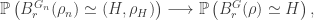


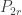

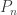

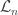

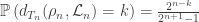




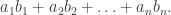
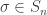 ,
,
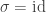 .
.
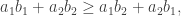

 is a transposition. For example, we might consider 12435. When we write out the result we want:
is a transposition. For example, we might consider 12435. When we write out the result we want:
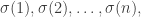

 is less than or equal to the product sum corresponding to
is less than or equal to the product sum corresponding to 
 .
.![n^{n-2}\left[\binom{n}{2}-(n-1)\right]=n^{n-2}\binom{n-1}{2}.](https://s0.wp.com/latex.php?latex=n%5E%7Bn-2%7D%5Cleft%5B%5Cbinom%7Bn%7D%7B2%7D-%28n-1%29%5Cright%5D%3Dn%5E%7Bn-2%7D%5Cbinom%7Bn-1%7D%7B2%7D.&bg=ffffff&fg=333333&s=0&c=20201002)

 is the number of partitions of [n] with k blocks. Remember that the blocks in a partition are necessarily unordered. This makes sense in this setting as the cyclic permutation chosen from the (k-1)! possibilities specifies the order on the cycle.
is the number of partitions of [n] with k blocks. Remember that the blocks in a partition are necessarily unordered. This makes sense in this setting as the cyclic permutation chosen from the (k-1)! possibilities specifies the order on the cycle.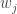 arrangements of any block of size j, and there are
arrangements of any block of size j, and there are 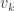 ways to arrange the blocks, if there are k of them. Note that we assume
ways to arrange the blocks, if there are k of them. Note that we assume  , and
, and  . Pitman denotes these sequences by
. Pitman denotes these sequences by  . Then the (n,k)th partial Bell polynomial,
. Then the (n,k)th partial Bell polynomial, 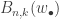 gives the number of divisions into k blocks:
gives the number of divisions into k blocks:
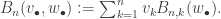
 give the number of permutations of [n] with k cycles. Since we don’t want to impose any combinatorial structure on the set of cycles, we don’t need to consider
give the number of permutations of [n] with k cycles. Since we don’t want to impose any combinatorial structure on the set of cycles, we don’t need to consider  , and the number of ways to make a j-cycle from a j-block is
, and the number of ways to make a j-cycle from a j-block is  , so
, so  . Similarly, the Stirling numbers of the second kind
. Similarly, the Stirling numbers of the second kind 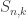 give the number of permutations of [n] into k blocks. Almost by definition,
give the number of permutations of [n] into k blocks. Almost by definition,  , where $1^\bullet$ is defined to be the sequence containing all 1s.
, where $1^\bullet$ is defined to be the sequence containing all 1s. , it is clear why there are
, it is clear why there are  ordered partitions encoding this structure. This multinomial coefficient can be written as a product of factorials of $n_i$s over i, and so we can write:
ordered partitions encoding this structure. This multinomial coefficient can be written as a product of factorials of $n_i$s over i, and so we can write:
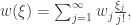
![B_{n,k}(w_\bullet)=n![\xi^n]\frac{w(\xi)^k}{k!},\quad B_n(v_\bullet,w_\bullet)=n![\xi^n]v(w(\xi)).](https://s0.wp.com/latex.php?latex=B_%7Bn%2Ck%7D%28w_%5Cbullet%29%3Dn%21%5B%5Cxi%5En%5D%5Cfrac%7Bw%28%5Cxi%29%5Ek%7D%7Bk%21%7D%2C%5Cquad+B_n%28v_%5Cbullet%2Cw_%5Cbullet%29%3Dn%21%5B%5Cxi%5En%5Dv%28w%28%5Cxi%29%29.&bg=ffffff&fg=333333&s=0&c=20201002)
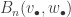 counts the number of partitions of [n] subject to some extra structure. If we choose uniformly from this set, we get a distribution on this combinatorial object, for which the Bell polynomial provides the normalising constant. If we then ignore the extra structure, the sequences
counts the number of partitions of [n] subject to some extra structure. If we choose uniformly from this set, we get a distribution on this combinatorial object, for which the Bell polynomial provides the normalising constant. If we then ignore the extra structure, the sequences 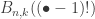 and there is certainly no simple form for this, so the possibility of doing a technical limiting argument seems slim.
and there is certainly no simple form for this, so the possibility of doing a technical limiting argument seems slim.
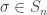 and a colouring of [n] with k colours such that the orbits of
and a colouring of [n] with k colours such that the orbits of ![a\in[n]](https://s0.wp.com/latex.php?latex=a%5Cin%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , we construct
, we construct  by
by  ,
,  and for all other x,
and for all other x, 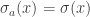 . We give n+1 the same colour as a. This gives us n possibilities. Alternatively, we can map (n+1) to itself and give it any colour we want. This gives us x possibilities. A slightly more careful argument shows that this is indeed a 1-to-(x+n) map, which is exactly what we require.
. We give n+1 the same colour as a. This gives us n possibilities. Alternatively, we can map (n+1) to itself and give it any colour we want. This gives us x possibilities. A slightly more careful argument shows that this is indeed a 1-to-(x+n) map, which is exactly what we require.


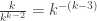 . But a star can only be formed by successively adding single vertices to an existing star. That is, we cannot join a 3-tree and a 4-tree with a edge to get a 7-star. So it is certainly not immediately clear that once we’ve incorporated the cycle deletion mechanism, the resulting trees will be uniform once we condition on their size.
. But a star can only be formed by successively adding single vertices to an existing star. That is, we cannot join a 3-tree and a 4-tree with a edge to get a 7-star. So it is certainly not immediately clear that once we’ve incorporated the cycle deletion mechanism, the resulting trees will be uniform once we condition on their size.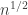 . Here’s a quick but very informal argument that did genuinely originate on the back of a napkin. I’m using the LERW definition. Let’s start at vertex x and perform LERW, and record how long the resultant path is as time t advances. This is a Markov chain: call the path length at time t
. Here’s a quick but very informal argument that did genuinely originate on the back of a napkin. I’m using the LERW definition. Let’s start at vertex x and perform LERW, and record how long the resultant path is as time t advances. This is a Markov chain: call the path length at time t 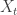 .
.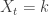 , with probability
, with probability 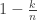 we get
we get  , and for each j in {0,…,k-1}, with probability 1/n we have
, and for each j in {0,…,k-1}, with probability 1/n we have 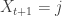 , as this corresponds to hitting a vertex we have already visited. So
, as this corresponds to hitting a vertex we have already visited. So![\mathbb{E}\Big[X_{t+1}|X_t=k\Big]=\frac{nk-k^2/2}{n}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5CBig%5BX_%7Bt%2B1%7D%7CX_t%3Dk%5CBig%5D%3D%5Cfrac%7Bnk-k%5E2%2F2%7D%7Bn%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
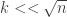 and negative for
and negative for  , so we would expect
, so we would expect  to be the correct scaling if we wanted to find an equilibrium distribution. And the expected hitting time of vertex y is n, by a geometric distribution argument, so in fact we would expect this Markov chain to be well into the equilibrium window with the
to be the correct scaling if we wanted to find an equilibrium distribution. And the expected hitting time of vertex y is n, by a geometric distribution argument, so in fact we would expect this Markov chain to be well into the equilibrium window with the 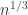 . I found this initially surprising, so tried a small example to see if that shed any light on the situation.
. I found this initially surprising, so tried a small example to see if that shed any light on the situation. in this cycle. If any of
in this cycle. If any of  then we can replace e_i with e to get a spanning tree with smaller weight, a contradiction of the claim that we started with an MST. So by distinctness of weights, we conclude that
then we can replace e_i with e to get a spanning tree with smaller weight, a contradiction of the claim that we started with an MST. So by distinctness of weights, we conclude that  for all i.
for all i.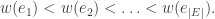
 . This now answers our original question about how the random weight MST depends in distribution on the underlying edge weight distribution. So long as with probability one the weights are distinct (which holds if the distribution is continuous), then the distribution of the resulting spanning tree is constant.
. This now answers our original question about how the random weight MST depends in distribution on the underlying edge weight distribution. So long as with probability one the weights are distinct (which holds if the distribution is continuous), then the distribution of the resulting spanning tree is constant.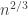 , as in the critical window for the E-R process.
, as in the critical window for the E-R process.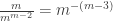 . By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge.
. By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge.