
I haven’t published a post about probability for far too long. Several are queued, so perhaps this will be the start of a deluge.
Anyway, with my advisor at Technion, I’m still working on some problems concerning Gaussian random walk subject to some conditioning which is complicated, but in practice (we hope) only mildly different to conditioning the walk to stay positive. Our conditioning at step n depends on some external randomness, but also on the future trajectory of the walk (related to the embedding of the walk in a 2D DGFF), thus ruining the possibility of applying the Markov property in any proof without significant preliminary work.
It seemed worth writing briefly about some of these results in a slightly simpler setting. The goal is to assemble many of the ingredients required to prove a local limit for Gaussian random walk conditioned to stay positive, in a sense which will be clarified towards the end. This is not the best way to go about getting scaling limits (as discussed briefly here, and for which see references [Ig74] and [Bo76]), and it’s probably not the best way to get local limits in the simplest setting, but it’s the method we are currently working to generalise, and follows the outline of [B-JD05], but in much less technical detail.
Probabilities via the reflection principle
We start with Brownian motion. The reflection principle, as described briefly in this post from the depths of history, is a classical technique for studying the maximum of Brownian motion. Roughly speaking, we exploit the fact that 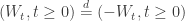
Let 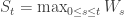

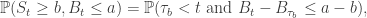
which, by SMP at

This obviously assumed 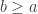


Or, in other words, 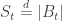
While we can’t derive such nice equalities in distribution, the reflection principle is robust enough to treat more complicated settings, such as Brownian bridge.
We might want to ask about the maximum of a standard Brownian bridge, but we can be more general, and ask about the maximum of a Brownian bridge with drift (let’s say general bridge here). It’s important to remember that a general Brownian bridge has the same distribution as a linear transformation of a standard Brownian bridge. Everything is Gaussian, after all. So asking whether the maximum of a general Brownian bridge is less than a particular value is equivalent to asking whether a standard Brownian bridge lies below a fixed line. Wherever possible, we make such a transformation at the start and perform the simplest version of the required calculation.
So, suppose we have a bridge B from (0,0) to (t,a), and we want to study ![\max_{s\in[0,t]} B_s](https://s0.wp.com/latex.php?latex=%5Cmax_%7Bs%5Cin%5B0%2Ct%5D%7D+B_s&bg=ffffff&fg=333333&s=0&c=20201002)
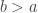


![\mathbb{P}(\tau_b\le t, W_t\in[a,a+\mathrm{d}x]) = \mathbb{P}(W_t\in [2b-a-\mathrm{d}x,2b-a]) = \frac{\mathrm{d}x}{\sqrt{2\pi t}}e^{-(2b-a)^2/2t},](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28%5Ctau_b%5Cle+t%2C+W_t%5Cin%5Ba%2Ca%2B%5Cmathrm%7Bd%7Dx%5D%29+%3D+%5Cmathbb%7BP%7D%28W_t%5Cin+%5B2b-a-%5Cmathrm%7Bd%7Dx%2C2b-a%5D%29+%3D+%5Cfrac%7B%5Cmathrm%7Bd%7Dx%7D%7B%5Csqrt%7B2%5Cpi+t%7D%7De%5E%7B-%282b-a%29%5E2%2F2t%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and
![\mathbb{P}(W_t\in[a,a+\mathrm{d}x])=\frac{\mathrm{d}x}{\sqrt{2\pi t}}e^{-a^2/2t}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28W_t%5Cin%5Ba%2Ca%2B%5Cmathrm%7Bd%7Dx%5D%29%3D%5Cfrac%7B%5Cmathrm%7Bd%7Dx%7D%7B%5Csqrt%7B2%5Cpi+t%7D%7De%5E%7B-a%5E2%2F2t%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
So
![\mathbb{P}(\max_{s\in[0,t]}B_t\ge b) = \exp\left(\frac{-(2b-a)^2 + a^2}{2t}\right).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28%5Cmax_%7Bs%5Cin%5B0%2Ct%5D%7DB_t%5Cge+b%29+%3D+%5Cexp%5Cleft%28%5Cfrac%7B-%282b-a%29%5E2+%2B+a%5E2%7D%7B2t%7D%5Cright%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Random walk conditioned to stay positive
Our main concern is conditioning to stay above zero. Let 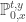
![\mathbb{P}_{0,x}^{t,y}(B_s\ge 0,\,s\in[0,t])=1-\exp\left( \frac{-(x+y)^2 + (x-y)^2}{2t} \right)= 1-\exp\left(-\frac{2xy}{t}\right).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D_%7B0%2Cx%7D%5E%7Bt%2Cy%7D%28B_s%5Cge+0%2C%5C%2Cs%5Cin%5B0%2Ct%5D%29%3D1-%5Cexp%5Cleft%28+%5Cfrac%7B-%28x%2By%29%5E2+%2B+%28x-y%29%5E2%7D%7B2t%7D+%5Cright%29%3D+1-%5Cexp%5Cleft%28-%5Cfrac%7B2xy%7D%7Bt%7D%5Cright%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Then, if 
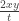
Extend the notation so 
![\mathbb{P}_{0,x}(B_s\ge 0,\, s\in[0,t] ) = \frac{x}{t}\mathbb{E}[B_t\vee 0] = \sqrt{\frac{2}{\pi}} \frac{x}{\sqrt{t}}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D_%7B0%2Cx%7D%28B_s%5Cge+0%2C%5C%2C+s%5Cin%5B0%2Ct%5D+%29+%3D+%5Cfrac%7Bx%7D%7Bt%7D%5Cmathbb%7BE%7D%5BB_t%5Cvee+0%5D+%3D+%5Csqrt%7B%5Cfrac%7B2%7D%7B%5Cpi%7D%7D+%5Cfrac%7Bx%7D%7B%5Csqrt%7Bt%7D%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
(It might appear that we have integrated the approximation (*) over parts of the range where it is not a valid approximation, but the density of 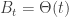
We now want to extend this to random walks. Some remarks:
- We used the Gaussian property of Brownian motion fairly heavily throughout this derivation. In general random walks are not Gaussian, though we can make life easier by focusing on this case.
- We also used the continuity property of Brownian motion when we applied the reflection principle. For a general random walk, it’s hopeless to consider the hitting times of individual values. We have to consider instead the hitting times of regions
, and so on. One can still apply SMP and a reflection principle, but this gives bounds rather than equalities. (The exception is simple random walk, for which other more combinatorial methods may be available anyway.)
- On the flip side, if we are interested in Brownian motion/bridge staying positive, we can’t start it from zero, as then the probability of this event is zero, by Blumenthal’s 0-1 law. By contrast, we can certainly ask about random walk staying positive when started from zero without taking a limit.
A useful technique will be the viewpoint of random walk as the values taken by Brownian motion at a sequence of stopping times. This Skorohod embedding is slightly less obvious when considering a general random walk bridge inside a general Brownian bridge, but is achievable. We want to study quantities like
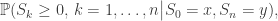
where for simplicity let’s just take 

What’s the probability that the Brownian bridge goes below zero, but the embedded RW with n steps does not?
If the Brownian bridge conditioned to go below zero spends time 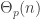
Several technical estimates are required to make this analysis rigorous. The conclusion is that there exists a function 
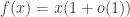
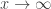
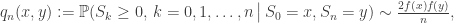

As earlier, the second is obtained from the first by integrating over suitable y. This function 
Limits for the conditioned random walk
In the previous post on this topic, we addressed scaling limits in space and time for conditioned random walks. But we don’t have to look at the classical Donsker scaling to see the effects of conditioning to stay positive. In our setting, we are interested in studying the distribution of 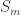
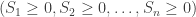

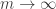
(At a more general level, it is meaningful to describe the random walk conditioned on staying positive forever. Although this would a priori require conditioning on an event of probability zero, it can be handled formally as an example of an h-transform.)
As explained in that previous post, the scaling invariance of the Bessel process 
However, we can use the previous estimate to start a direct calculation.

Here, we used the Markov property at time m to split the event that 
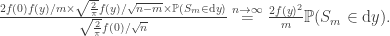
This final probability emphasises that as 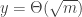


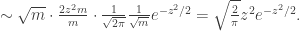
This is precisely the entrance law of the 3-dimensional Bessel process, usually denoted 
Final remarks
The order of taking limits is truly crucial. We can also obtain a distributional scaling limit at time n under conditioning to stay non-negative up to time n. But then this is the size-biased normal distribution 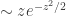
The asymptotics for
References
[Bo76] – Bolthausen – On a functional central limit theorem for random walks conditioned to stay positive
[B-JD05] – Bryn-Jones, Doney – A functional limit theorem for random walk conditioned to stay non-negative
[CHL17] – Cortines, Hartung, Louidor – The structure of extreme level sets in branching Brownian motion
[Ig74] – Iglehart – Functional central limit theorems for random walks conditioned to stay positive
[Pi75] – Pitman – One-dimensional Brownian motion and the three-dimensional Bessel process
 be a random walk with IID increments, with distribution X. Take
be a random walk with IID increments, with distribution X. Take  to be the expectation of these increments, and we’ll assume that the variance
to be the expectation of these increments, and we’ll assume that the variance  is finite, though at times we may need to enforce slightly stronger regularity conditions.
is finite, though at times we may need to enforce slightly stronger regularity conditions. for n=0,1,…,N, particularly for large N. For ease of notation we write
for n=0,1,…,N, particularly for large N. For ease of notation we write 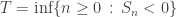 for the hitting time of the negative half-plane. Thus we are interested in
for the hitting time of the negative half-plane. Thus we are interested in  conditioned on T>N, or T=N, mindful that these might not be the same. We will also discuss briefly to what extent we can condition on
conditioned on T>N, or T=N, mindful that these might not be the same. We will also discuss briefly to what extent we can condition on  .
. until step N by the question of
until step N by the question of  (which, naturally, has drift
(which, naturally, has drift  ) conditioned to stay non-negative until step N, by a direct coupling.
) conditioned to stay non-negative until step N, by a direct coupling.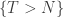
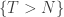 , obviously the resulting distribution (of the process) is a mixture of the distributions we obtain by conditioning on each of
, obviously the resulting distribution (of the process) is a mixture of the distributions we obtain by conditioning on each of  . Shortly, we’ll condition on
. Shortly, we’ll condition on  itself, but first it’s worth establishing how to relate the two options. That is, conditional on
itself, but first it’s worth establishing how to relate the two options. That is, conditional on  , this event always has positive probability, since
, this event always has positive probability, since  . So as
. So as 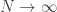 , the distribution of the process conditional on
, the distribution of the process conditional on 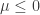 , everything is encapsulated in the tail of the probabilities
, everything is encapsulated in the tail of the probabilities  , and these tails are qualitatively different in the cases
, and these tails are qualitatively different in the cases 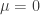 and
and  .
.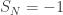 is a large deviations event in the sense of
is a large deviations event in the sense of 
 in fact concentrates T on N+o(N). Whereas by contrast, when
in fact concentrates T on N+o(N). Whereas by contrast, when  .
.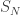 , conditional on {T>N}. It’s a related problem because the event {T>N} depends only on the process up to time N, and so given the value of
, conditional on {T>N}. It’s a related problem because the event {T>N} depends only on the process up to time N, and so given the value of  when
when  , though the limiting distribution depends on the increment distribution in a sense that is best described through Laplace transforms. If we start a RW with negative drift from height O(1), then it hits zero in time O(1), so in fact this shows that conditonal on
, though the limiting distribution depends on the increment distribution in a sense that is best described through Laplace transforms. If we start a RW with negative drift from height O(1), then it hits zero in time O(1), so in fact this shows that conditonal on  , as shown earlier by Iglehart [Ig1]. Again, thinking about the central limit theorem, this fits the asymptotic description of T conditioned on T>N.
, as shown earlier by Iglehart [Ig1]. Again, thinking about the central limit theorem, this fits the asymptotic description of T conditioned on T>N.
![\left[\frac{1}{\sqrt{N}}S(\lfloor Nt\rfloor ) ,t\in[0,1] \right] \Rightarrow W^+(t),](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7B1%7D%7B%5Csqrt%7BN%7D%7DS%28%5Clfloor+Nt%5Crfloor+%29+%2Ct%5Cin%5B0%2C1%5D+%5Cright%5D+%5CRightarrow+W%5E%2B%28t%29%2C&bg=ffffff&fg=333333&s=0&c=20201002) (*)
(*)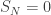 . Skorohod’s proof for Brownian bridge [Sk] approximates the event
. Skorohod’s proof for Brownian bridge [Sk] approximates the event  by
by ![\{S_N\in[-\epsilon \sqrt{N},+\epsilon \sqrt{N}]\}](https://s0.wp.com/latex.php?latex=%5C%7BS_N%5Cin%5B-%5Cepsilon+%5Csqrt%7BN%7D%2C%2B%5Cepsilon+%5Csqrt%7BN%7D%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) , since the probability of this event is bounded away from zero. Similarly, but with more technicalities, a proof of convergence conditional on T=N can approximate by
, since the probability of this event is bounded away from zero. Similarly, but with more technicalities, a proof of convergence conditional on T=N can approximate by ![\{S_m\ge 0, m\in[\delta N,(1-\delta)N], S_N\in [-\epsilon \sqrt{N},+\epsilon\sqrt{N}]\}](https://s0.wp.com/latex.php?latex=%5C%7BS_m%5Cge+0%2C+m%5Cin%5B%5Cdelta+N%2C%281-%5Cdelta%29N%5D%2C+S_N%5Cin+%5B-%5Cepsilon+%5Csqrt%7BN%7D%2C%2B%5Cepsilon%5Csqrt%7BN%7D%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The technicalities here emerge since T, the first return time to zero, is not continuous as a function of continuous functions. (Imagine a sequence of processes
. The technicalities here emerge since T, the first return time to zero, is not continuous as a function of continuous functions. (Imagine a sequence of processes  for which
for which 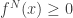 on [0,1] and
on [0,1] and  .)
.) , the same result (*) holds, although a different proof is in general necessary. See [BD] and references for details. However, this is particularly clear in the case where the increments are Gaussian. In this setting, we don’t actually need to take a scaling limit. The distribution of Gaussian *random walk bridge* doesn’t depend on the mean of the increments. This is related to the fact that a linear transformation of a Gaussian is Gaussian, and can be seen by examining the joint density function directly.
, the same result (*) holds, although a different proof is in general necessary. See [BD] and references for details. However, this is particularly clear in the case where the increments are Gaussian. In this setting, we don’t actually need to take a scaling limit. The distribution of Gaussian *random walk bridge* doesn’t depend on the mean of the increments. This is related to the fact that a linear transformation of a Gaussian is Gaussian, and can be seen by examining the joint density function directly. occurs with positive probability, so it is well-defined to condition on it. When
occurs with positive probability, so it is well-defined to condition on it. When  , where
, where  is small. This is approximately given by
is small. This is approximately given by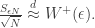
 and consider the RHS. If instead of the Brownian excursion
and consider the RHS. If instead of the Brownian excursion ![\mathrm{d}W^+(t) = \left[\frac{1}{W^+(t)} - \frac{W^+(t)}{1-t}\right] \mathrm{d}t + \mathrm{d}B(t),\quad t\in(0,1)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bd%7DW%5E%2B%28t%29+%3D+%5Cleft%5B%5Cfrac%7B1%7D%7BW%5E%2B%28t%29%7D+-+%5Cfrac%7BW%5E%2B%28t%29%7D%7B1-t%7D%5Cright%5D+%5Cmathrm%7Bd%7Dt+%2B+%5Cmathrm%7Bd%7DB%28t%29%2C%5Cquad+t%5Cin%280%2C1%29&bg=ffffff&fg=333333&s=0&c=20201002) (**)
(**)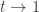 .
. as
as 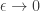 , and we can say that
, and we can say that 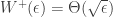 .
.
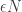 ‘, to conclude that there is a well-defined scaling limit for the RW conditioned to stay positive forever. But we came up with this estimate by taking
‘, to conclude that there is a well-defined scaling limit for the RW conditioned to stay positive forever. But we came up with this estimate by taking 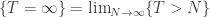 is a monotone limit, and so further tools are available. In particular, if we know that the trajectories of the random walk satisfy the FKG property, then we can define this limit directly. It feels intuitively clear that random walks should satisfy the
is a monotone limit, and so further tools are available. In particular, if we know that the trajectories of the random walk satisfy the FKG property, then we can define this limit directly. It feels intuitively clear that random walks should satisfy the 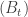 , and a stopping time T. Then, so long as T satisfies one of the regularity conditions under which the
, and a stopping time T. Then, so long as T satisfies one of the regularity conditions under which the ![\mathbb{E}[B_T]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB_T%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002) . (See
. (See  is a martingale,
is a martingale, ![\mathbb{E}[B_T^2]=\mathbb{E}[T]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB_T%5E2%5D%3D%5Cmathbb%7BE%7D%5BT%5D&bg=ffffff&fg=333333&s=0&c=20201002) , so if the latter is finite, so is the former.
, so if the latter is finite, so is the former. such that the increments
such that the increments  are IID with the same distribution as T. Then
are IID with the same distribution as T. Then  is a centered random walk. By taking T to be the hitting time of
is a centered random walk. By taking T to be the hitting time of  , it is easy to see that we can embed simple random walk in a Brownian motion using this approach.
, it is easy to see that we can embed simple random walk in a Brownian motion using this approach.
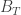 for some integrable stopping time T.
for some integrable stopping time T. , the hitting time of (random value) X. But recall that unfortunately
, the hitting time of (random value) X. But recall that unfortunately 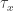 has infinite expectation for all non-zero x, so this doesn’t fit the conditions required to use OST.
has infinite expectation for all non-zero x, so this doesn’t fit the conditions required to use OST. , the first hitting time of
, the first hitting time of  is integrable. Then we choose one of these positive-negative pairs according to the projection of the distribution of X onto the pairings, and let T be the hitting time of this pair of values. The probability of hitting b conditional on hitting {a,b} is easy to compute (it’s
is integrable. Then we choose one of these positive-negative pairs according to the projection of the distribution of X onto the pairings, and let T be the hitting time of this pair of values. The probability of hitting b conditional on hitting {a,b} is easy to compute (it’s 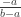 ) so we need to have chosen our pairs so that the ‘probability’ of hitting b (ie the density) comes out right. In particular, this method has to start from continuous distributions X, and treat atoms in the distribution of X separately.
) so we need to have chosen our pairs so that the ‘probability’ of hitting b (ie the density) comes out right. In particular, this method has to start from continuous distributions X, and treat atoms in the distribution of X separately. ) is particularly clear, as then the pairs should be
) is particularly clear, as then the pairs should be  .
.
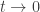 (which is independent of hitting times). But of course, unfortunately
(which is independent of hitting times). But of course, unfortunately 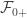 has a
has a ![a_+:= \mathbb{E}[X \,|\, X>0], \quad a_- := \mathbb{E}[X\,|\, X<0],](https://s0.wp.com/latex.php?latex=a_%2B%3A%3D+%5Cmathbb%7BE%7D%5BX+%5C%2C%7C%5C%2C+X%3E0%5D%2C+%5Cquad+a_-+%3A%3D+%5Cmathbb%7BE%7D%5BX%5C%2C%7C%5C%2C+X%3C0%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) (*)
(*) . We need to check that
. We need to check that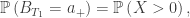
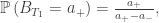
![\mathbb{E}[X]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002) , using the law of total expectation:
, using the law of total expectation:![0=\mathbb{E}[X]=\mathbb{E}[X\,|\, X>0] \mathbb{P}(X>0) + \mathbb{E}[X\,|\,X<0]\mathbb{P}(X<0) = a_+ \mathbb{P}(X>0) + a_- \left(1-\mathbb{P}(X>0) \right),](https://s0.wp.com/latex.php?latex=0%3D%5Cmathbb%7BE%7D%5BX%5D%3D%5Cmathbb%7BE%7D%5BX%5C%2C%7C%5C%2C+X%3E0%5D+%5Cmathbb%7BP%7D%28X%3E0%29+%2B+%5Cmathbb%7BE%7D%5BX%5C%2C%7C%5C%2CX%3C0%5D%5Cmathbb%7BP%7D%28X%3C0%29+%3D+a_%2B+%5Cmathbb%7BP%7D%28X%3E0%29+%2B+a_-+%5Cleft%281-%5Cmathbb%7BP%7D%28X%3E0%29+%5Cright%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)

![a_{++}=\mathbb{E}[X \,|\, X>a_+],\quad a_{+-}=\mathbb{E}[X\,|\, 0<X<a_+],](https://s0.wp.com/latex.php?latex=a_%7B%2B%2B%7D%3D%5Cmathbb%7BE%7D%5BX+%5C%2C%7C%5C%2C+X%3Ea_%2B%5D%2C%5Cquad+a_%7B%2B-%7D%3D%5Cmathbb%7BE%7D%5BX%5C%2C%7C%5C%2C+0%3CX%3Ca_%2B%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 . So then, conditional on
. So then, conditional on  , we take
, we take
 . By an identical argument to the one we have just deployed, we have
. By an identical argument to the one we have just deployed, we have ![\mathbb{E}\left[B_{T_2} \,|\,\mathcal{F}_{T_1} \right] = B_{T_1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BB_%7BT_2%7D+%5C%2C%7C%5C%2C%5Cmathcal%7BF%7D_%7BT_1%7D+%5Cright%5D+%3D+B_%7BT_1%7D&bg=ffffff&fg=333333&s=0&c=20201002) almost surely. So, although the
almost surely. So, although the  notation now starts to get very unwieldy, it’s clear we can keep going in this way to get a sequence of stopping times
notation now starts to get very unwieldy, it’s clear we can keep going in this way to get a sequence of stopping times 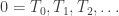 where
where  determines which of the
determines which of the  regions of the real line any limit
regions of the real line any limit  should lie in.
should lie in. is almost surely finite, but once we have this, it is clear that
is almost surely finite, but once we have this, it is clear that  almost surely, and
almost surely, and  in the Skorohod embedding and its expectation (recall
in the Skorohod embedding and its expectation (recall ![\mathbb{E}[T_k]=k](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BT_k%5D%3Dk&bg=ffffff&fg=333333&s=0&c=20201002) ) is
) is  . So, constructing the random walk
. So, constructing the random walk  from the Brownian motion via Skorohod embedding leads to
from the Brownian motion via Skorohod embedding leads to
 . Strassen (1966) shows that the true scale of the maximum
. Strassen (1966) shows that the true scale of the maximum
 and
and 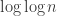 as one would expect.
as one would expect.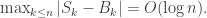
![\left[\max_{k\le n} \left |S_k-B_k\right| - C\log n\right] \vee 0](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cmax_%7Bk%5Cle+n%7D+%5Cleft+%7CS_k-B_k%5Cright%7C+-+C%5Clog+n%5Cright%5D+%5Cvee+0&bg=ffffff&fg=333333&s=0&c=20201002)
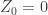 , and then condition on
, and then condition on  , thinking of this as a demand that the process has returned to zero at the future time. In some applications, this is the ideal intuition, but in others, it is more useful to think of the random walk bridge
, thinking of this as a demand that the process has returned to zero at the future time. In some applications, this is the ideal intuition, but in others, it is more useful to think of the random walk bridge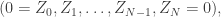
![(B^{\mathrm{br}}_t, t\in[0,1])](https://s0.wp.com/latex.php?latex=%28B%5E%7B%5Cmathrm%7Bbr%7D%7D_t%2C+t%5Cin%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)
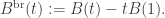 (*)
(*)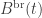 for each
for each ![t\in[0,1]](https://s0.wp.com/latex.php?latex=t%5Cin%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and with a bit more work, one can calculate the joint distribution of
, and with a bit more work, one can calculate the joint distribution of 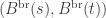 . In particular, the joint distribution is multivariate Gaussian, and so everything depends on the covariance ‘matrix’ (which here is indexed by [0,1]).
. In particular, the joint distribution is multivariate Gaussian, and so everything depends on the covariance ‘matrix’ (which here is indexed by [0,1]).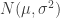 …] More concretely, if a RW has Gaussian increments, then the path
…] More concretely, if a RW has Gaussian increments, then the path 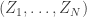 is a multivariate normal, or a Gaussian process with finite index set. In particular, covariances define the distribution. It remains a Gaussian process after conditioning on
is a multivariate normal, or a Gaussian process with finite index set. In particular, covariances define the distribution. It remains a Gaussian process after conditioning on  (or a subset of it) is helpful, for which a scaling limit might be a random surface rather than Brownian motion.
(or a subset of it) is helpful, for which a scaling limit might be a random surface rather than Brownian motion.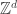 , it’s harder to define any such random object on the entire lattice immediately, so we start with compact connected subsets, with zero boundary conditions, as in the one-dimensional case of random walk bridge. Formally, let D be a finite subset of
, it’s harder to define any such random object on the entire lattice immediately, so we start with compact connected subsets, with zero boundary conditions, as in the one-dimensional case of random walk bridge. Formally, let D be a finite subset of 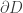 those elements of
those elements of 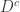 which are adjacent to an element of D, and let
which are adjacent to an element of D, and let  .
. , with probability density proportional to
, with probability density proportional to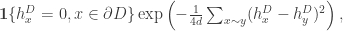 (1)
(1)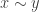 if that x,y are adjacent in
if that x,y are adjacent in  . We won’t at any stage worry much about the partition function which normalises this pdf. Note also that
. We won’t at any stage worry much about the partition function which normalises this pdf. Note also that 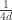 is just a convenient choice of constant, which corresponds to one of the canonical choices for the discrete Laplacian. Adjusting this constant is the same as uniformly rescaling the values taken by the field.
is just a convenient choice of constant, which corresponds to one of the canonical choices for the discrete Laplacian. Adjusting this constant is the same as uniformly rescaling the values taken by the field.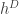 are fixed everywhere except one vertex
are fixed everywhere except one vertex 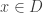 , then the conditional distribution of
, then the conditional distribution of 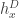 is Gaussian. Later, or in subsequent posts, we will heavily develop this idea. Alternatively, we could if we really wanted describe the model in terms of independent Gaussians describing the ‘increment’ along each edge in D (which we should direct), subject to a very large number of conditions, namely that the sum of increments along any directed cycle is zero. This latter description might be more useful if you wanted to define a DGFF on a more sparse graph, but won’t be useful in what follows.
is Gaussian. Later, or in subsequent posts, we will heavily develop this idea. Alternatively, we could if we really wanted describe the model in terms of independent Gaussians describing the ‘increment’ along each edge in D (which we should direct), subject to a very large number of conditions, namely that the sum of increments along any directed cycle is zero. This latter description might be more useful if you wanted to define a DGFF on a more sparse graph, but won’t be useful in what follows.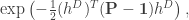
 is the transition matrix of SRW on D. In particular, this means that the free field is Gaussian, and we can extract the covariances via
is the transition matrix of SRW on D. In particular, this means that the free field is Gaussian, and we can extract the covariances via![\mathrm{Cov}(h^D_x,h^D_y) = \left[ (\mathbf{1}-\mathbf{P})^{-1}\right]_{x,y}](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28h%5ED_x%2Ch%5ED_y%29+%3D+%5Cleft%5B+%28%5Cmathbf%7B1%7D-%5Cmathbf%7BP%7D%29%5E%7B-1%7D%5Cright%5D_%7Bx%2Cy%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![= \left[\sum_{n\ge 0} \mathbf{P}^n\right]_{x,y} = \sum_{n\ge 0} \mathbb{P}_x\left[X_n=y,\tau_{\partial D}>n\right],](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5B%5Csum_%7Bn%5Cge+0%7D+%5Cmathbf%7BP%7D%5En%5Cright%5D_%7Bx%2Cy%7D+%3D+%5Csum_%7Bn%5Cge+0%7D+%5Cmathbb%7BP%7D_x%5Cleft%5BX_n%3Dy%2C%5Ctau_%7B%5Cpartial+D%7D%3En%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
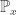 ,
, 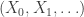 is simple random walk started from x.
is simple random walk started from x. .
. , the square box of width N has some scaling limit as
, the square box of width N has some scaling limit as ![x,y\in [0,1]^2](https://s0.wp.com/latex.php?latex=x%2Cy%5Cin+%5B0%2C1%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) , (and taking integer parts component-wise), well-known asymptotics for SRW in a large square lattice (more on this soon hopefully) assert that
, (and taking integer parts component-wise), well-known asymptotics for SRW in a large square lattice (more on this soon hopefully) assert that (2)
(2)![[0,1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) , with the consequence that a) more care is needed over its abstract definition; b) the DGFF in 2D on a large square is an interesting object, since it does exist in this sense.
, with the consequence that a) more care is needed over its abstract definition; b) the DGFF in 2D on a large square is an interesting object, since it does exist in this sense.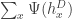 term, then for suitable choice of function
term, then for suitable choice of function 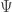 , this is interpreted as a model where the particles have mass. The physical interpretation of these more general Gibbs measures is discussed widely, and I’m not very comfortable with it all at the moment, but aim to come back to it later, when hopefully I will be more comfortable.
, this is interpreted as a model where the particles have mass. The physical interpretation of these more general Gibbs measures is discussed widely, and I’m not very comfortable with it all at the moment, but aim to come back to it later, when hopefully I will be more comfortable. . There’s also the opposite ordering to consider, where the block of size x lies clockwise from the other. The total probability of this merge
. There’s also the opposite ordering to consider, where the block of size x lies clockwise from the other. The total probability of this merge  is therefore proportional to (x+y+2).
is therefore proportional to (x+y+2). , for some
, for some 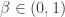 .
. , and there are
, and there are 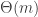 blocks with high probability. Relatively straightforward calculations in extreme value theory suggest that the largest block is likely to have size on the order of
blocks with high probability. Relatively straightforward calculations in extreme value theory suggest that the largest block is likely to have size on the order of  in this setting.
in this setting. , a necessary condition is that at least
, a necessary condition is that at least 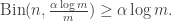
 , this event corresponds approximately to
, this event corresponds approximately to
 . But there are
. But there are  possible places for such a block to start, so whether we can apply a union bound usefully or not depends on whether the power of m is strictly less than -1.
possible places for such a block to start, so whether we can apply a union bound usefully or not depends on whether the power of m is strictly less than -1.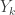 be the number of cars which arrive at place k. So the sum of the
be the number of cars which arrive at place k. So the sum of the 
 , if l is much larger than this, the rescaled empirical process is essentially deterministic, so we won’t see any macroscopic excursions above the minimum.
, if l is much larger than this, the rescaled empirical process is essentially deterministic, so we won’t see any macroscopic excursions above the minimum. , where the rescaled empirical process looks like a slanted Brownian bridge, that is Brownian motion conditioned to pass through $(1,-\frac{\ell}{\sqrt{m})$. There isn’t an obvious fix to the question of where to start the process, but it turns out that the correct way is now adding a Brownian excursion onto the deterministic linear function with gradient
, where the rescaled empirical process looks like a slanted Brownian bridge, that is Brownian motion conditioned to pass through $(1,-\frac{\ell}{\sqrt{m})$. There isn’t an obvious fix to the question of where to start the process, but it turns out that the correct way is now adding a Brownian excursion onto the deterministic linear function with gradient  . It’s now reasonable that the excursions above the minimum should macroscopic.
. It’s now reasonable that the excursions above the minimum should macroscopic. moving through the critical window
moving through the critical window  . Finally, a direction to Bertoin’s recent paper [1] for the model with an additional destructive property. Analogous to the forest fire, blocks of cars are removed at a rate proportional to their size (as a result, naturally, of ‘Molotov cocktails’…). Similar effects of self-organised criticality are seen when the rate of bombs is scaled appropriately.
. Finally, a direction to Bertoin’s recent paper [1] for the model with an additional destructive property. Analogous to the forest fire, blocks of cars are removed at a rate proportional to their size (as a result, naturally, of ‘Molotov cocktails’…). Similar effects of self-organised criticality are seen when the rate of bombs is scaled appropriately.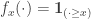 for each
for each ![x\in[0,T]](https://s0.wp.com/latex.php?latex=x%5Cin%5B0%2CT%5D&bg=ffffff&fg=333333&s=0&c=20201002) , then
, then 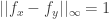 whenever
whenever 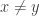 . In particular, we have an uncountable collection of disjoint open sets given by the balls
. In particular, we have an uncountable collection of disjoint open sets given by the balls  , and so the space is not countable. Similarly,
, and so the space is not countable. Similarly,  is not separable. A counterexample might be given by considering functions which take the values {0,1} on the integers. Thus we have a map from
is not separable. A counterexample might be given by considering functions which take the values {0,1} on the integers. Thus we have a map from  , where the uniform distance between any two distinct image points is at least one, hence the open balls of radius 1/2 around each image point give the same contradiction as before. However, the Stone-Weierstrass theorem shows that C[0,T] is separable, as we can approximate any such function uniformly well by a polynomial, and thus uniformly well by a polynomial with rational coefficients.
, where the uniform distance between any two distinct image points is at least one, hence the open balls of radius 1/2 around each image point give the same contradiction as before. However, the Stone-Weierstrass theorem shows that C[0,T] is separable, as we can approximate any such function uniformly well by a polynomial, and thus uniformly well by a polynomial with rational coefficients.![C[0,T]\rightarrow \mathbb{R}](https://s0.wp.com/latex.php?latex=C%5B0%2CT%5D%5Crightarrow+%5Cmathbb%7BR%7D&bg=ffffff&fg=333333&s=0&c=20201002) given by
given by 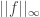 is continuous, and hence uniform boundedness is certainly a required condition for compactness in C[0,T]. Arzela-Ascoli states that uniform boundedness plus equicontinuity is sufficient for a set of such functions to be compact. Equicontinuity should be thought of as uniform continuity that is uniform among all the functions in the set, rather than just within the argument of an individual particular function.
is continuous, and hence uniform boundedness is certainly a required condition for compactness in C[0,T]. Arzela-Ascoli states that uniform boundedness plus equicontinuity is sufficient for a set of such functions to be compact. Equicontinuity should be thought of as uniform continuity that is uniform among all the functions in the set, rather than just within the argument of an individual particular function.
 with
with 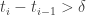 . Note that as
. Note that as 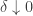 , we can, if we want, place the
, we can, if we want, place the  so that large jumps of the function f take place over the boundaries between adjacent parts of the mesh. In particular, for a given cadlag function, it can be shown fairly easily that
so that large jumps of the function f take place over the boundaries between adjacent parts of the mesh. In particular, for a given cadlag function, it can be shown fairly easily that  as
as  . Then, unsurprisingly, in a similar fashion to the Arzela-Ascoli theorem, it follows that a set of functions
. Then, unsurprisingly, in a similar fashion to the Arzela-Ascoli theorem, it follows that a set of functions ![A\subset D[0,T]](https://s0.wp.com/latex.php?latex=A%5Csubset+D%5B0%2CT%5D&bg=ffffff&fg=333333&s=0&c=20201002) is relatively compact if it is uniformly bounded, and
is relatively compact if it is uniformly bounded, and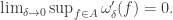
 uniformly across all functions. This would obviously not work, as then the functions
uniformly across all functions. This would obviously not work, as then the functions  for any sequence
for any sequence 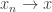 would not be compact, but they clearly converge in Skorohod space!
would not be compact, but they clearly converge in Skorohod space!
 on D[0,T], the sequence is tight precisely if for any
on D[0,T], the sequence is tight precisely if for any  and some N such that for any n>N, both
and some N such that for any n>N, both

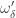 by
by  , the standard modulus of continuity, then we have the additional that any weak limit lies in C[0,T].
, the standard modulus of continuity, then we have the additional that any weak limit lies in C[0,T].
 does not depend on the value of
does not depend on the value of 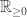 . So as BM is the fundamental real-valued continuous-time Markov process, we should ask how we might adjust it so that it stays non-negative. In particular, we want to clarify uniqueness, or at least be sure we have found all the sensible ways to make this adjustment, and also to consider how Donsker’s Theorem might work in this setting.
. So as BM is the fundamental real-valued continuous-time Markov process, we should ask how we might adjust it so that it stays non-negative. In particular, we want to clarify uniqueness, or at least be sure we have found all the sensible ways to make this adjustment, and also to consider how Donsker’s Theorem might work in this setting.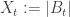 . This is very natural and very convenient for analysis, but there are some problems. Firstly, this has the property that it looks like Brownian motion everywhere except 0 only because BM is space-homogeneous but also symmetric, in the sense that
. This is very natural and very convenient for analysis, but there are some problems. Firstly, this has the property that it looks like Brownian motion everywhere except 0 only because BM is space-homogeneous but also symmetric, in the sense that 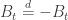 . This will be untrue for essentially any other process, so as a general method for how to keep stochastic processes positive, this will be useless. My second objection is a bit more subtle. If we consider this as an SDE, we get
. This will be untrue for essentially any other process, so as a general method for how to keep stochastic processes positive, this will be useless. My second objection is a bit more subtle. If we consider this as an SDE, we get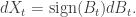
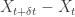 to depend on
to depend on 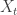 and on
and on 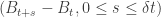 , but not on
, but not on 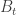 itself, as that means we have to keep track of extra information while constructing X.
itself, as that means we have to keep track of extra information while constructing X.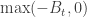 , but this sum would then spend macroscopic intervals of time at 0, and these intervals would have the Raleigh distribution (for Brownian excursions) rather than the exponential distribution, hence the process given by the sum would not be memoryless and Markov.
, but this sum would then spend macroscopic intervals of time at 0, and these intervals would have the Raleigh distribution (for Brownian excursions) rather than the exponential distribution, hence the process given by the sum would not be memoryless and Markov.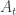 , and then it makes sense to talk about the minimal increasing process that has the desired property. A moment’s thought suggests that
, and then it makes sense to talk about the minimal increasing process that has the desired property. A moment’s thought suggests that 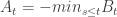 satisfies this. So we have the decomposition
satisfies this. So we have the decomposition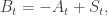
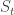 is the height of B above its running minimum. So S is an ideal alternative definition of reflecting BM. In particular, when B is away from its minimum,
is the height of B above its running minimum. So S is an ideal alternative definition of reflecting BM. In particular, when B is away from its minimum,  , so this has the property that it evolves exactly as the driving Brownian motion.
, so this has the property that it evolves exactly as the driving Brownian motion.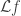 giving the infinitissimal drift of
giving the infinitissimal drift of 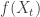 . In the case of Brownian motion, the generator
. In the case of Brownian motion, the generator 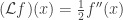 for bounded smooth functions f. This is equivalent to saying that
for bounded smooth functions f. This is equivalent to saying that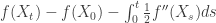 (*)
(*)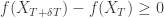 , hence the expression (*) is a submartingale. So if we restrict attention to functions with f'(0)=0, the generator remains the same. Indeed, by patching together all such intervals, it can be argued that even if f'(0) is not zero,
, hence the expression (*) is a submartingale. So if we restrict attention to functions with f'(0)=0, the generator remains the same. Indeed, by patching together all such intervals, it can be argued that even if f'(0) is not zero,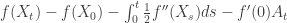
 , we have:
, we have: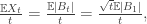
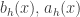 are the rescaled drift and square-drift from x. We assume that we don’t see macroscopic jumps in the limit. For the case of simple random walk reflected at 0, it doesn’t matter exactly how we construct the joint limit in h and x, as the drift is uniform on x>0, but in general this does matter. I don’t want to discuss sticky BM right now, so it’s probably easiest to be vague and say that the discrete Markov processes converge to reflected BM so long they don’t spend more time than expected near 0 in the limit, as the title ‘sticky’ might suggest.
are the rescaled drift and square-drift from x. We assume that we don’t see macroscopic jumps in the limit. For the case of simple random walk reflected at 0, it doesn’t matter exactly how we construct the joint limit in h and x, as the drift is uniform on x>0, but in general this does matter. I don’t want to discuss sticky BM right now, so it’s probably easiest to be vague and say that the discrete Markov processes converge to reflected BM so long they don’t spend more time than expected near 0 in the limit, as the title ‘sticky’ might suggest.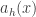 is too small, in which case the process looks almost deterministic near 0, or if the drift doesn’t increase fast enough. And indeed, this leads to two conditions. The first is straightforward, if
is too small, in which case the process looks almost deterministic near 0, or if the drift doesn’t increase fast enough. And indeed, this leads to two conditions. The first is straightforward, if 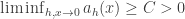 , then we have convergence to reflected BM. Alternatively, the only danger can arise down those subsequences where
, then we have convergence to reflected BM. Alternatively, the only danger can arise down those subsequences where  , so if we have that
, so if we have that  whenever
whenever  , then this convergence also holds.
, then this convergence also holds.



 . But instead of investigating LD behaviour for the sample mean, we investigate LD behaviour for the whole set of RVs. There is a bijection between sequences and the partial sums process, so we investigate the partial sums process, rescaled appropriately. For the moment this is a sequence not a function or path (continuous or otherwise), but in the limit it will be, and furthermore it won’t make too much difference whether we interpolate linearly or step-wise.
. But instead of investigating LD behaviour for the sample mean, we investigate LD behaviour for the whole set of RVs. There is a bijection between sequences and the partial sums process, so we investigate the partial sums process, rescaled appropriately. For the moment this is a sequence not a function or path (continuous or otherwise), but in the limit it will be, and furthermore it won’t make too much difference whether we interpolate linearly or step-wise.![Z_n(t):=\tfrac{1}{n}\sum_{i=1}^{[nt]}X_i,\quad t\in[0,1],](https://s0.wp.com/latex.php?latex=Z_n%28t%29%3A%3D%5Ctfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7B%5Bnt%5D%7DX_i%2C%5Cquad+t%5Cin%5B0%2C1%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
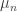 supported on
supported on ![L_\infty([0,1])](https://s0.wp.com/latex.php?latex=L_%5Cinfty%28%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) . Note that the expected behaviour is a straight line from (0,0) to (1,
. Note that the expected behaviour is a straight line from (0,0) to (1,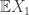 ). In fact we can say more than that. By Donsker’s theorem we have a functional version of a central limit theorem, which says that deviations from this expected behaviour are given by suitably scaled Brownian motion:
). In fact we can say more than that. By Donsker’s theorem we have a functional version of a central limit theorem, which says that deviations from this expected behaviour are given by suitably scaled Brownian motion:![\sqrt{n}\left(\frac{Z_n(t)-t\mathbb{E}X}{\sqrt{\text{Var}(X_1)}}\right)\quad\stackrel{d}{\rightarrow}\quad B(t),\quad t\in[0,1].](https://s0.wp.com/latex.php?latex=%5Csqrt%7Bn%7D%5Cleft%28%5Cfrac%7BZ_n%28t%29-t%5Cmathbb%7BE%7DX%7D%7B%5Csqrt%7B%5Ctext%7BVar%7D%28X_1%29%7D%7D%5Cright%29%5Cquad%5Cstackrel%7Bd%7D%7B%5Crightarrow%7D%5Cquad+B%28t%29%2C%5Cquad+t%5Cin%5B0%2C1%5D.&bg=ffffff&fg=333333&s=0&c=20201002)



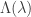 is the logarithmic moment generating function of X_1 as before, with
is the logarithmic moment generating function of X_1 as before, with  the Fenchel-Legendre transform. Then the key result is:
the Fenchel-Legendre transform. Then the key result is:
 for which
for which  is at least in principle finite. (Obviously, if
is at least in principle finite. (Obviously, if 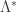 is not finite everywhere, then extra restrictions of
is not finite everywhere, then extra restrictions of 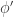 are required.)
are required.)
 , then this says that:
, then this says that:

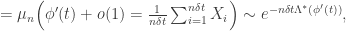
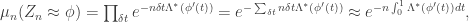
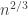 , as in the critical window for the E-R process.
, as in the critical window for the E-R process. . There are various neat proofs, many of which consider a mild generalisation which gives us a more natural framework for using induction. This might be a suitable subject for a subsequent post.
. There are various neat proofs, many of which consider a mild generalisation which gives us a more natural framework for using induction. This might be a suitable subject for a subsequent post.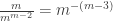 . By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge.
. By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge.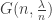 , in the super-critical phase
, in the super-critical phase 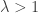 . With high probability (that is, with probability tending to 1 as n grows), we have a so-called giant component, with O(n) vertices.
. With high probability (that is, with probability tending to 1 as n grows), we have a so-called giant component, with O(n) vertices. . The number of neighbours of each of these which we haven’t already considered is then
. The number of neighbours of each of these which we haven’t already considered is then 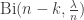 , conditional on k, the number of vertices we have already discounted. After any finite number of steps, k=o(n), and so it is fairly reasonable to approximate this just by
, conditional on k, the number of vertices we have already discounted. After any finite number of steps, k=o(n), and so it is fairly reasonable to approximate this just by  . Furthermore, as n grows, this distribution converges to
. Furthermore, as n grows, this distribution converges to  , and so it is natural to expect that the probability that the fixed vertex lies in a giant component is equal to the survival probability
, and so it is natural to expect that the probability that the fixed vertex lies in a giant component is equal to the survival probability 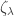 (that is, the probability that it is infinite) of a branching process with
(that is, the probability that it is infinite) of a branching process with  , because we require
, because we require  for the survival probability to be non-zero. Obviously, all of this needs to be made precise and rigorous, and this is treated in sections 4.3 and 4.4 of the notes.
for the survival probability to be non-zero. Obviously, all of this needs to be made precise and rigorous, and this is treated in sections 4.3 and 4.4 of the notes.
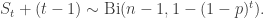
 is number of vertices we have explored or seen, ie are connected to a vertex we have explored. Suppose the remaining vertices are called unseen, and we began the exploration at vertex 1. Then any vertex with label in {2,…,n} is unseen if it successively avoids being in the neighbourhood of v(1), v(2), … v(t). This happens with probability
is number of vertices we have explored or seen, ie are connected to a vertex we have explored. Suppose the remaining vertices are called unseen, and we began the exploration at vertex 1. Then any vertex with label in {2,…,n} is unseen if it successively avoids being in the neighbourhood of v(1), v(2), … v(t). This happens with probability  , and so the probability of being an explored or seen vertex is the complement of this.
, and so the probability of being an explored or seen vertex is the complement of this.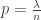 with
with  .
. .
.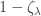 . We have:
. We have:
 . In fact we also have a central limit theorem for S_t, which enables us to deduce that
. In fact we also have a central limit theorem for S_t, which enables us to deduce that  with high probability, as well as in expectation, which is precisely what is required to prove that the giant component of
with high probability, as well as in expectation, which is precisely what is required to prove that the giant component of 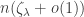 .
.