We study a procedure for generating a random sequence of permutations of [N]. We start with the identity permutation, and then in each step, we choose two elements uniformly at random, and swap them. We obtain a sequence of permutations, where each term is obtained from the previous one by multiplying by a uniformly-chosen transposition.
Some more formality and some technical remarks:
- This is a Markov chain, and as often with Markov chains, it would be better it was aperiodic. As described, the cycle will alternate between odd and even permutations. So we allow the two elements chosen to be the same. This laziness slows down the chain by a factor N-1/N, but removes periodicity. We will work over timescales where this adjustment makes no practical difference.
- Let
 be the sequence of transpositions. We could define the sequence of permutations by
be the sequence of transpositions. We could define the sequence of permutations by  . I find it slightly more helpful to think of swapping the elements in places i and j, rather the elements i and j themselves, and so I’ll use this language, for which
. I find it slightly more helpful to think of swapping the elements in places i and j, rather the elements i and j themselves, and so I’ll use this language, for which  is the appropriate description. Of course, transpositions and the identity are self-inverse permutations, so it makes no difference to anything we might discuss.
is the appropriate description. Of course, transpositions and the identity are self-inverse permutations, so it makes no difference to anything we might discuss.
- You can view this as lazy random walk on the Cayley graph of
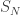 generated by the set of transpositions. That is, the vertices of the graph are elements of , and two are connected by an edge if one can be obtained from the other by multiplying by a transposition. Note this relation is symmetric. Hence random transposition random walk.
generated by the set of transpositions. That is, the vertices of the graph are elements of , and two are connected by an edge if one can be obtained from the other by multiplying by a transposition. Note this relation is symmetric. Hence random transposition random walk.
- Almost everything under discussion would work in continuous time too.
At a very general level, this sort of model is interesting because sometimes the only practical way to introduce ‘global randomness’ is repeatedly to apply ‘local randomness’. This is not the case for permutations – it is not hard to sample uniformly from . But it is a tractable model in which to study relevant questions about the generating randomness on a complicated set through iterated local operations.
Since it is a Markov chain with a straightforward invariant distribution, we can ask about the mixing time. That is, the correct scaling for the number of moves before the random permutation is close in distribution (say in the sense of total variation distance) to the equilibrium distribution. See this series of posts for an odd collection of background material on the topic. Diaconis and Shahshahani [DS81] give an analytic argument for mixing around  transpositions. Indeed they include a constant because it is a sharp cutoff, where the total variation distance drops from approximately 1 to approximately 0 in O(N) steps.
transpositions. Indeed they include a constant because it is a sharp cutoff, where the total variation distance drops from approximately 1 to approximately 0 in O(N) steps.
Comparison with Erdos-Renyi random graph process
In the previous result, one might observe that  is also the threshold number of edges to guarantee connectivity of the Erdos-Renyi random graph G(N,m) with high probability. [ER59] Indeed, there is also a sharp transition around this threshold in this setting too.
is also the threshold number of edges to guarantee connectivity of the Erdos-Renyi random graph G(N,m) with high probability. [ER59] Indeed, there is also a sharp transition around this threshold in this setting too.
We explore this link further. We can construct a sequence of random graphs simultaneously with the random transposition random walk. When we multiply by transposition (i j), we add edge ij in the graph. Laziness of RTRW and the possibility of multiple edges mean this definition isn’t literally the same as the conventional definition of a discrete-time Erdos-Renyi random graph process, but again this is not a problem for any of the effects we seek to study.
The similarity between the constructions is clear. But what about the differences? For the RTRW, we need to track more information than the random graph. That is, we need to know what order the transpositions were added, rather than merely which edges were added. However, the trade-off is that a permutation is a simpler object than a graph in the following sense. A permutation can be a described as a union of disjoint cycles. In an exchangeable setting, all the information about a random permutation is encoded in the lengths of the these cycles. Whereas in a graph, geometry is important. It’s an elegant property of the Erdos-Renyi process that we can forget about the geometry and treat it as a process on component sizes (indeed, a multiplicative coalescent process), but there are other questions we might need to ask for which we do have to study the graph structure itself.
Within this analogy, unfortunately the word cycle means different things in the two different settings. In a permutation, a cycle is a directed orbit, while in a graph it has the usual definition. I’m going to write graph-cycle whenever relevant to avoid confusion.
A first observation is that, under this equivalence, the cycles of the permutation form a finer partition than the components of the graph. This is obvious. If we split the vertices into sets A and B, and there are no edges between them, then nothing in set A will ever get moved out of set A by a transposition. (Note that the slickness of this analogy is the advantage of viewing a transposition as swapping the elements in places i and j.)
However, we might then ask under what circumstances is a cycle of the permutation the same as a component of the graph (rather than a strict subset of it). A first answer is the following:
Lemma: [Den59] The permutation formed by a product of transpositions corresponding in any order to a tree in the graph has a single cycle.
We can treat this as a standalone problem and argue in the following predictable fashion. (Indeed, I was tempted to set this as a problem during selection for the UK team for IMO 2017 – it’s perfectly suitable in this context I think.) The first transposition corresponds to some edge say ab, and removing this edge divides the vertices into components  . Since no further transposition swaps between places in A and places in B, the final permutation maps a into B and b into A, and otherwise preserves A and B.
. Since no further transposition swaps between places in A and places in B, the final permutation maps a into B and b into A, and otherwise preserves A and B.
This argument extends to later transpositions too. Now, suppose there are multiple cycles. Colour one of them. So during the process, the coloured labels move around. At some point, we must swap a coloured label with an uncoloured label. Consider this edge, between places a and b as before, and indeed the same conclusion holds. WLOG we move the coloured label from a to b. But then at the end of the process (ie in the permutation) there are more coloured labels in B than initially. But the number of coloured labels should be the same, because they just cycle around in the final permutation.
We can learn a bit more by trying thinking about the action on cycles (in the permutation) of adding a transposition. In the following pair of diagrams, the black arrows represent the original permutation (note it’s not helpful to think of the directed edges as having anything to do with transpositions now), the dashed line represents a new transposition, and the new arrows describe the new permutation which results from this product.
It’s clear from this that adding a transposition between places corresponding to different cycles causes the cycles to merge, while adding a transposition between places already in the same cycle causes the cycle to split into two cycles. Furthermore the sizes of the two cycles formed is related to the distance in the cycle between the places defining the transposition.
This allows us to prove the lemma by adding the edges of the tree one-at-a-time and using induction. The inductive claim is that cycles of the permutation exactly correspond to components of the partially-built tree. Assuming this claim guarantees that the next step is definitely a merge, not a split (otherwise the edge corresponding to the next step would have to form a cycle). If all N-1 steps are merges, then the number of cycles is reduced by one on each step, and so the final permutation must be a single cycle.
Uniform split-merge
This gives another framework for thinking about the RTRW itself, entirely in terms of cycle lengths as a partition of [N]. That is, given a partition, we choose a pair of parts in a size-biased way. If they are different, we merge them; and if it is the same part, with size k, we split them into two parts, with sizes chosen uniformly from { (1,k-1), (2,k-2), … (k-1,1) }.
What’s nice about this is that it’s easy to generalise to real-valued partitions, eg of [0,1]. Given a partition of [0,1], we sample two IID U[0,1] random variables  . If these correspond to different parts, we replace these parts by a single part with size given by the sum. If these correspond to the same part, with size
. If these correspond to different parts, we replace these parts by a single part with size given by the sum. If these correspond to the same part, with size  , we split this part into two parts with sizes
, we split this part into two parts with sizes  and
and  . This is equivalent in a distributional sense to sampling another U[0,1] variable U and replacing with
. This is equivalent in a distributional sense to sampling another U[0,1] variable U and replacing with  . We probably want our partition to live in
. We probably want our partition to live in 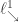 , so we might have to reorder the parts afterwards too.
, so we might have to reorder the parts afterwards too.
These uniform split-merge dynamics have a (unique) stationary distribution, the canonical Poisson-Dirichlet random partition, hereafter PD(0,1). This was first shown in [DMZZ04], and then in a framework more relevant to this post by Schramm [Sch08].
Conveniently, PD(0,1) is also the scaling limit of the cycle lengths in a uniform random permutation (scaled by N). The best way to see this is to start with the observation that the length of the cycle containing 1 in a permutation chosen uniformly from has the uniform distribution on {1,…,N}. This matches up well with the uniform stick-breaking construction of PD(0,1), though other arguments are available too. Excellent background on Poisson-Dirichlet distributions and this construction and equivalence can be found in Chapter 3 of Pitman’s comprehensive St. Flour notes [CSP]. Also see this post, and the links within, with the caveat that my understanding of the topic was somewhat shaky then (as presently, for now).
However, Schramm says slightly more than this. As the Erdos-Renyi graph passes criticality, there is a well-defined (and whp unique) giant component including 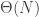 vertices. It’s not clear that the corresponding permutation should have giant cycles. Indeed, whp the giant component has surplus edges, so the process of cycle lengths will have undergone
vertices. It’s not clear that the corresponding permutation should have giant cycles. Indeed, whp the giant component has surplus edges, so the process of cycle lengths will have undergone  splits. Schramm shows that most of the labels within the giant component are contained in giant cycles in the permutation. Furthermore, the distribution of cycle lengths within the giant component, rescaled by the size of the giant component, converges in distribution to PD(0,1) at any supercritical time
splits. Schramm shows that most of the labels within the giant component are contained in giant cycles in the permutation. Furthermore, the distribution of cycle lengths within the giant component, rescaled by the size of the giant component, converges in distribution to PD(0,1) at any supercritical time 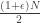
This is definitely surprising, since we already know that the whole permutation doesn’t look close to uniform until time . Essentially, even though the size of the giant component is non-constant (ie it’s gaining vertices), the uniform split-merge process is happening to the cycles within it at rate N. So heuristically, at the level of the largest cycles, at any supercritical time we have a non-trivial partition, so at any slightly later time (eg  and ), mixing will have comfortably occurred, and so the distribution is close to PD(0,1).
and ), mixing will have comfortably occurred, and so the distribution is close to PD(0,1).
This is explained very clearly in the introduction of [Ber10], in which the approach is extended to a random walk on driven by a uniform choice from any conjugacy class.
So this really does tell us how the global uniform randomness emerges. As the random graph process passes criticality, we have a positive mass of labels in a collection of giant cycles which are effectively a continuous-space uniform split-merge model near equilibrium (and thus with PD(0,1) marginals). The remaining cycles are small, corresponding to small trees which make up the remaining (subcritical by duality) components of the ER graph. These cycles slowly get absorbed into the giant cycles, but on a sufficiently slow timescale relevant to the split-merge dynamics that we do not need to think of a separate split-merge-with-immigration model. Total variation distance on permutations does feel the final few fixed points (corresponding to isolated vertices in the graph), hence the sharp cutoff corresponding to sharp transition in the number of isolated vertices.
References
[Ber10] – N. Berestycki – Emergence of giant cycles and slowdown transition in random transpositions and k-cycles. [arXiv version]
[CSP] – Pitman – Combinatorial stochastic processes. [pdf available]
[Den59] – Denes – the representation of a permutation as a product of a minimal number of transpositions, and its connection with the theory of graphs
[DS81] – Diaconis, Shahshahani – Generating a random permutation with random transpositions
[DMZZ04] – Diaconis, Mayer-Wolf, Zeitouni, Zerner – The Poisson-Dirichlet distribution is the unique invariant distribution for uniform split-merge transformations [link]
[ER59] – Erdos, Renyi – On random graphs I.
[Sch08] – Schramm – Compositions of random transpositions [book link]

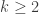


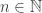
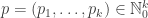



vertices have type i.
(for
) is present, independently, with probability
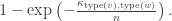
have type 1,
have type 2, etc etc. This makes no difference except in terms of the notation we have to use if we want to use exchangeability arguments later.
on [k], and assigns the types of the vertices of [n] in an IID fashion according to
. The exponential form has a more natural interpretation if we ever need to turn the IRGs into a process. Additionally, it avoids the requirement to treat small values of n (for which, a priori,
might be greater than 1) separately.


![\pi=(\pi_1,\ldots,\pi_k)\in[0,1]^k](https://s0.wp.com/latex.php?latex=%5Cpi%3D%28%5Cpi_1%2C%5Cldots%2C%5Cpi_k%29%5Cin%5B0%2C1%5D%5Ek&bg=ffffff&fg=333333&s=0&c=20201002)
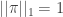

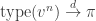

, the number of type j neighbours of
.
.
![p_j\left[1-\exp\left(-\frac{\kappa_{i,j}}{n}\right)\right]\approx \frac{p_j\cdot \kappa_{i,j}}{n} \approx \kappa_{i,j}\pi_j](https://s0.wp.com/latex.php?latex=p_j%5Cleft%5B1-%5Cexp%5Cleft%28-%5Cfrac%7B%5Ckappa_%7Bi%2Cj%7D%7D%7Bn%7D%5Cright%29%5Cright%5D%5Capprox+%5Cfrac%7Bp_j%5Ccdot+%5Ckappa_%7Bi%2Cj%7D%7D%7Bn%7D+%5Capprox+%5Ckappa_%7Bi%2Cj%7D%5Cpi_j&bg=ffffff&fg=333333&s=0&c=20201002)
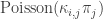
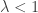 and the supercritical regime
and the supercritical regime 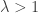 concerning the size of the largest component
concerning the size of the largest component  .
.
 converges locally weakly in probability to the Galton-Watson tree with
converges locally weakly in probability to the Galton-Watson tree with  offspring distribution, as we’ve used informally earlier in the course.
offspring distribution, as we’ve used informally earlier in the course. . At a heuristic level, we imagine that all vertices whose local neighbourhood is ‘infinite’ are in fact part of the same giant component, which should occupy
. At a heuristic level, we imagine that all vertices whose local neighbourhood is ‘infinite’ are in fact part of the same giant component, which should occupy 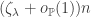 vertices. In its most basic form, the result is
vertices. In its most basic form, the result is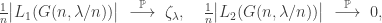 (*)
(*) , then each time we add a new edge (such an argument is often called ‘sprinkling‘), the probability that these two components are joined is
, then each time we add a new edge (such an argument is often called ‘sprinkling‘), the probability that these two components are joined is 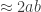 , and so if we add lots of edges (which happens as we move from edge probability
, and so if we add lots of edges (which happens as we move from edge probability  ) then with high probability these two components get joined.
) then with high probability these two components get joined. and
and 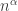 ) and then show that all larger components are the same by a joint exploration process or a technical sprinkling argument. Cf the books of Bollobas and of Janson, Luczak, Rucinski. See also
) and then show that all larger components are the same by a joint exploration process or a technical sprinkling argument. Cf the books of Bollobas and of Janson, Luczak, Rucinski. See also  ,
, with high probability as
with high probability as 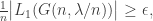 with high probability.
with high probability.


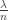 . In the second model, we choose uniformly at random from the set of graphs with n vertices and
. In the second model, we choose uniformly at random from the set of graphs with n vertices and  edges. Note that if we take the first model and condition on the number of edges, we get the second model, since the probability of a given configuration appearing in G(n,p) is a function only of the number of edges present. Furthermore, the number of edges in G(n,p) is binomial with parameters
edges. Note that if we take the first model and condition on the number of edges, we get the second model, since the probability of a given configuration appearing in G(n,p) is a function only of the number of edges present. Furthermore, the number of edges in G(n,p) is binomial with parameters  and p. For all purposes here it will make no difference to approximate the former by
and p. For all purposes here it will make no difference to approximate the former by  .
. passes 1. Below 1, the largest component has size on a scale of log n, and with high probability all components are trees. Above 1, there is a unique giant component containing
passes 1. Below 1, the largest component has size on a scale of log n, and with high probability all components are trees. Above 1, there is a unique giant component containing 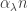 vertices, and all other components are small. For
vertices, and all other components are small. For  , where I don’t want to discuss what ‘approximately’ means right now, we have a critical window, for which there are infinitely many components with sizes on a scale of
, where I don’t want to discuss what ‘approximately’ means right now, we have a critical window, for which there are infinitely many components with sizes on a scale of 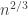 .
.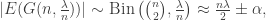
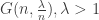 .
. , so would have no giant components. However, it is also possible that the lack of a giant component is due to ‘clustering’. We might in fact have the correct number of edges, but they might have arranged themselves into a configuration that keeps the number of components small. For example, we might have a complete graph on
, so would have no giant components. However, it is also possible that the lack of a giant component is due to ‘clustering’. We might in fact have the correct number of edges, but they might have arranged themselves into a configuration that keeps the number of components small. For example, we might have a complete graph on 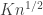 vertices plus a whole load of isolated vertices. This has the correct number of edges, but certainly no giant component (that is an O(n) component).
vertices plus a whole load of isolated vertices. This has the correct number of edges, but certainly no giant component (that is an O(n) component).
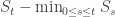
 equal to (-1) times the number of components already explored up to time t.
equal to (-1) times the number of components already explored up to time t.![\text{Bin}\Big(n-t-[S_t-\min_{0\leq s\leq t}S_s],\tfrac{\lambda}{n}\Big)-1.](https://s0.wp.com/latex.php?latex=%5Ctext%7BBin%7D%5CBig%28n-t-%5BS_t-%5Cmin_%7B0%5Cleq+s%5Cleq+t%7DS_s%5D%2C%5Ctfrac%7B%5Clambda%7D%7Bn%7D%5CBig%29-1.&bg=ffffff&fg=333333&s=0&c=20201002)
 latex \text{Po}(\lambda)-1$ and thus get a rate function for paths of the exploration process
latex \text{Po}(\lambda)-1$ and thus get a rate function for paths of the exploration process
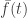 is the height of f above its previous minimum.
is the height of f above its previous minimum. with f. This doesn’t seem unreasonable. After all, if we pick a giant component within o(n) steps, then everything considered before the giant component won’t show up in the O(n) rescaling, so we will have a series of macroscopic excursions above 0 with widths giving the actual sizes of the giant components. The problem is that even though with high probability we will pick a giant component after O(1) components, then probability that we do not do this decays only exponentially fast, so will show up as a term in the LD analysis. We would hope that this would not be important – after all later we are going to take an infimum, and since the order we choose the vertices to explore is random and in particular independent of the actual structure, it ought not to make a huge difference to any result.
with f. This doesn’t seem unreasonable. After all, if we pick a giant component within o(n) steps, then everything considered before the giant component won’t show up in the O(n) rescaling, so we will have a series of macroscopic excursions above 0 with widths giving the actual sizes of the giant components. The problem is that even though with high probability we will pick a giant component after O(1) components, then probability that we do not do this decays only exponentially fast, so will show up as a term in the LD analysis. We would hope that this would not be important – after all later we are going to take an infimum, and since the order we choose the vertices to explore is random and in particular independent of the actual structure, it ought not to make a huge difference to any result.![L_\infty([0,1])](https://s0.wp.com/latex.php?latex=L_%5Cinfty%28%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) . In this generalised case, we will also need to check that approximating the Binomial distribution by its Poisson limit is valid on an exponential scale. Note that because errors in the approximation for small values of t affect the parameter of the distribution at larger times, this will be more complicated to check than for the IID case.
. In this generalised case, we will also need to check that approximating the Binomial distribution by its Poisson limit is valid on an exponential scale. Note that because errors in the approximation for small values of t affect the parameter of the distribution at larger times, this will be more complicated to check than for the IID case.
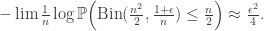
 . There are various neat proofs, many of which consider a mild generalisation which gives us a more natural framework for using induction. This might be a suitable subject for a subsequent post.
. There are various neat proofs, many of which consider a mild generalisation which gives us a more natural framework for using induction. This might be a suitable subject for a subsequent post.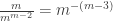 . By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge.
. By contrast, it is not possible to obtain a star on m+n vertices by joining a tree on m vertices and a tree on n vertices with an additional edge. , and we are considering the rescaled exploration process
, and we are considering the rescaled exploration process 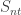 , which has asymptotic mean
, which has asymptotic mean  . We can calculate similarly an expression for the asymptotic variance
. We can calculate similarly an expression for the asymptotic variance
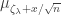 is negative, and has small variance, which would confirm that the giant component has size bounded above by
is negative, and has small variance, which would confirm that the giant component has size bounded above by 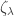 almost surely. A similar argument is required for the lower bound. The variance is a separate matter, but it is therefore necessary that
almost surely. A similar argument is required for the lower bound. The variance is a separate matter, but it is therefore necessary that  should be decreasing at
should be decreasing at  , that is
, that is 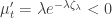 . This is what we try to prove in the remainder of this post. Recall that in the previous post we have checked that it is equal to zero here.
. This is what we try to prove in the remainder of this post. Recall that in the previous post we have checked that it is equal to zero here. corresponds to ndt for S, during which S will visit some components of size log n and some of O(1) and some in between. In particular, some fixed proportion of vertices are isolated, that is, in a component of size 1.
corresponds to ndt for S, during which S will visit some components of size log n and some of O(1) and some in between. In particular, some fixed proportion of vertices are isolated, that is, in a component of size 1. towards zero, because S_t decreases by 1 over a time-interval of length log n, which gives a gradient of zero in the limit. However, the isolated vertices give a gradient of -1, because S_t decreases by 1 over a time interval of 1. Despite the fact that log n intervals are likely to appear earlier, it still remains the case that after exhausting a component (in particular, at time
towards zero, because S_t decreases by 1 over a time-interval of length log n, which gives a gradient of zero in the limit. However, the isolated vertices give a gradient of -1, because S_t decreases by 1 over a time interval of 1. Despite the fact that log n intervals are likely to appear earlier, it still remains the case that after exhausting a component (in particular, at time  consists of some complicated weighted mean of 0 and -1. In particular, it is negative.
consists of some complicated weighted mean of 0 and -1. In particular, it is negative.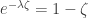 . We want to show that
. We want to show that 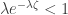 . Substituting
. Substituting


 . So it suffice to check the result for small
. So it suffice to check the result for small 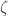 . But, again using a Taylor series:
. But, again using a Taylor series:
 is the expected number of vertices in the first generation of a
is the expected number of vertices in the first generation of a  whose progeny become extinct. This motivates considering the canonical decomposition of a supercritical branching process Z into the skeleton process and the dual process. The skeleton
whose progeny become extinct. This motivates considering the canonical decomposition of a supercritical branching process Z into the skeleton process and the dual process. The skeleton 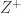 consists of all vertices which have infinitely many successors. It is relatively easy to show that this is a branching process with offspring distribution
consists of all vertices which have infinitely many successors. It is relatively easy to show that this is a branching process with offspring distribution  conditioned on being positive. The dual process
conditioned on being positive. The dual process  is a G-W branching process with offspring distribution
is a G-W branching process with offspring distribution 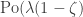 , by a sprinkling argument, which says that if we begin with a Poisson number of things, then remove each one independently with some fixed probability, the remaining number of things is Poisson also.
, by a sprinkling argument, which says that if we begin with a Poisson number of things, then remove each one independently with some fixed probability, the remaining number of things is Poisson also. , just take a copy of
, just take a copy of  . After all, the dual process is almost surely finite, so the offspring distribution cannot have expectation greater than 1. Checking that this is strong is more fiddly. The best way I have come up with is to examine the tail of the distribution of total population size of the original branching process.
. After all, the dual process is almost surely finite, so the offspring distribution cannot have expectation greater than 1. Checking that this is strong is more fiddly. The best way I have come up with is to examine the tail of the distribution of total population size of the original branching process.
 are iid with the offspring distribution. When
are iid with the offspring distribution. When  , this is a large deviation event, for which Cramer’s theorem applies (assuming, as is the case for the Poisson distribution, that the offspring distribution has finite variance). When,
, this is a large deviation event, for which Cramer’s theorem applies (assuming, as is the case for the Poisson distribution, that the offspring distribution has finite variance). When, 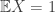 , the Central Limit Theorem says that with high probability,
, the Central Limit Theorem says that with high probability,![X_1+\ldots+X_n\in [n-n^{3/4},n+n^{3/4}],](https://s0.wp.com/latex.php?latex=X_1%2B%5Cldots%2BX_n%5Cin+%5Bn-n%5E%7B3%2F4%7D%2Cn%2Bn%5E%7B3%2F4%7D%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)

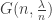 , in the super-critical phase
, in the super-critical phase  . The number of neighbours of each of these which we haven’t already considered is then
. The number of neighbours of each of these which we haven’t already considered is then 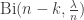 , conditional on k, the number of vertices we have already discounted. After any finite number of steps, k=o(n), and so it is fairly reasonable to approximate this just by
, conditional on k, the number of vertices we have already discounted. After any finite number of steps, k=o(n), and so it is fairly reasonable to approximate this just by  . Furthermore, as n grows, this distribution converges to
. Furthermore, as n grows, this distribution converges to  , because we require
, because we require  for the survival probability to be non-zero. Obviously, all of this needs to be made precise and rigorous, and this is treated in sections 4.3 and 4.4 of the notes.
for the survival probability to be non-zero. Obviously, all of this needs to be made precise and rigorous, and this is treated in sections 4.3 and 4.4 of the notes.
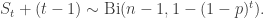
 is number of vertices we have explored or seen, ie are connected to a vertex we have explored. Suppose the remaining vertices are called unseen, and we began the exploration at vertex 1. Then any vertex with label in {2,…,n} is unseen if it successively avoids being in the neighbourhood of v(1), v(2), … v(t). This happens with probability
is number of vertices we have explored or seen, ie are connected to a vertex we have explored. Suppose the remaining vertices are called unseen, and we began the exploration at vertex 1. Then any vertex with label in {2,…,n} is unseen if it successively avoids being in the neighbourhood of v(1), v(2), … v(t). This happens with probability  , and so the probability of being an explored or seen vertex is the complement of this.
, and so the probability of being an explored or seen vertex is the complement of this.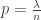 with
with  .
. .
.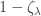 . We have:
. We have:
 . In fact we also have a central limit theorem for S_t, which enables us to deduce that
. In fact we also have a central limit theorem for S_t, which enables us to deduce that  with high probability, as well as in expectation, which is precisely what is required to prove that the giant component of
with high probability, as well as in expectation, which is precisely what is required to prove that the giant component of 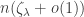 .
.