In the previous post on this topic, we discussed Dilworth’s theorem on chains and antichains in a general partially ordered set. In particular, whatever the size of the largest antichain in a poset, it is possible to partition the poset into exactly that many chains. So for various specific posets, or the directed acyclic graphs associated to them, we are interested in the size of this largest antichain.
The following example turned out to be more interesting than I’d expected. At a conventional modern maths olympiad, there are typically three questions on each paper, and for reasons lost in the mists of time, each student receives an integer score between 0 and 7 per question. A natural question to ask is “how many students need to sit a paper before it’s guaranteed that one will scores at least as highly as another on every question?” (I’m posing this as a straight combinatorial problem – the correlation between scores on different questions will be non-zero and presumably positive, but that is not relevant here.)
The set of outcomes is clearly 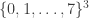 , with the usual weak domination partial order inherited from
, with the usual weak domination partial order inherited from 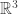 . Then an antichain corresponds to a set of triples of scores such that no triple dominates another triple. So the answer to the question posed is: “the size of the largest antichain in this poset, plus one.”
. Then an antichain corresponds to a set of triples of scores such that no triple dominates another triple. So the answer to the question posed is: “the size of the largest antichain in this poset, plus one.”
In general, we might ask about 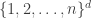 , again with the weak domination ordering. This directed graph, which generalises the hypercube as well as our example, is called the grid.
, again with the weak domination ordering. This directed graph, which generalises the hypercube as well as our example, is called the grid.
Heuristics for the largest antichain
Retaining the language of test scores on multiple questions is helpful. In the previous post, we constructed a partition of the poset into antichains, indexed by the elements of some maximal chain, by starting with the sources, then looking at everything descended only from sources, and so on. (Recall that the statement that this is possible was referred to as the dual of Dilworth’s theorem.) In the grid, there’s a lot of symmetry (in particular under the mapping  in every coordinate), and so you end up with the same family of antichains whether you work upwards from the sources or downwards from the sinks. (Or vice versa depending on how you’ve oriented your diagram…) The layers of antichains also have a natural interpretation – each layer corresponds to a given total score. It’s clear a priori why each of these is an antichain. If A scores the same as B overall, but strictly more on the first question, this must be counterbalanced by a strictly lower score on another question.
in every coordinate), and so you end up with the same family of antichains whether you work upwards from the sources or downwards from the sinks. (Or vice versa depending on how you’ve oriented your diagram…) The layers of antichains also have a natural interpretation – each layer corresponds to a given total score. It’s clear a priori why each of these is an antichain. If A scores the same as B overall, but strictly more on the first question, this must be counterbalanced by a strictly lower score on another question.
So a natural guess for the largest antichain is the largest antichain corresponding to some fixed total score. Which total score should this be? It ought to be the middle layer, that is total score 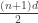 , or the two values directly on either side if this isn’t an integer. My intuition was probabilistic. The uniform distribution on the grid is achieved by IID uniform distributions in each coordinate, which you can think of as a random walk, especially if you subtract off the mean first. It feels that any symmetric random walk should have mode zero or next-to-zero. Certainly this works asymptotically in a rescaled sense by CLT, and in a slightly stronger sense by local CLT, but we don’t really want asymptotics here.
, or the two values directly on either side if this isn’t an integer. My intuition was probabilistic. The uniform distribution on the grid is achieved by IID uniform distributions in each coordinate, which you can think of as a random walk, especially if you subtract off the mean first. It feels that any symmetric random walk should have mode zero or next-to-zero. Certainly this works asymptotically in a rescaled sense by CLT, and in a slightly stronger sense by local CLT, but we don’t really want asymptotics here.
When I started writing the previous paragraph, I assumed there would be a simple justification for the claim that the middle layer(s) was largest, whether by straight enumeration, or some combinatorial argument, or even generating functions. Perhaps there is, and I didn’t spot it. Induction on d definitely works though, with a slightly stronger hypothesis that the layer sizes are symmetric around the median, and monotone on either side of the median. The details are simple and not especially interesting, so I won’t go into them.
From now on, the hypothesis is that this middle layer of the grid is the largest antichain. Why shouldn’t it, for example, be some mixture of middle-ish layers? (*) Well, heuristically, any score sequence in one layer removes several possibilities from a directly adjacent layer, and it seems unlikely that this effect is going to cancel out if you take some intermediate number of score sequences in the first layer. Also, the layers get smaller as you go away from the middle, so because of the large amount of symmetry (coordinates are exchangeable etc), it feels reasonable that there should be surjections between layers in the outward direction from the middle. The union of all these surjections gives a decomposition into chains.
This result is in fact true, and its proof by Bollobas and Leader, using shadows and compression can be found in the very readable Sections 0 and 1 of [1].
Most of the key ideas to a compression argument are present in the case n=2, for which some notes by Leader can be found here, starting with Proof 1 of Theorem 3, the approach of which is developed over subsequent sections. We treat the case n=2, but focusing on a particularly slick approach that does not generalise as successfully. We also return to the original case d=3 without using anything especially exotic.
Largest antichain in the hypercube – Sperner’s Theorem
The hypercube  is the classical example. There is a natural correspondence between the vertices of the hypercube, and subsets of
is the classical example. There is a natural correspondence between the vertices of the hypercube, and subsets of ![[d]](https://s0.wp.com/latex.php?latex=%5Bd%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The ordering on the hypercube corresponds to the ordering given by containment on
. The ordering on the hypercube corresponds to the ordering given by containment on ![\mathcal{P}([d])](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D%28%5Bd%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) . Almost by definition, the k-th layer corresponds to subsets of size k, and thus includes
. Almost by definition, the k-th layer corresponds to subsets of size k, and thus includes 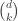 subsets. The claim is that the size of the largest antichain is
subsets. The claim is that the size of the largest antichain is  , corresponding to the middle layer if d is even, and one of the two middle layers if d is odd. This result is true, and is called Sperner’s theorem.
, corresponding to the middle layer if d is even, and one of the two middle layers if d is odd. This result is true, and is called Sperner’s theorem.
I know a few proofs of this from the Combinatorics course I attended in my final year at Cambridge. As explained, I’m mostly going to ignore the arguments using compression and shadows, even though these generalise better.
As in the previous post, one approach is to exhibit a covering family of exactly this number of disjoint chains. Indeed, this can be done layer by layer, working outwards from the middle layer(s). The tool here is Hall’s Marriage Theorem, and we verify the relevant condition by double-counting. Probably the hardest case is demonstrating the existence of a matching between the middle pair of layers when d is odd.
Take d odd, and let  . Now consider any subset S of the d’-th layer
. Now consider any subset S of the d’-th layer ![\binom{[d]}{d'}](https://s0.wp.com/latex.php?latex=%5Cbinom%7B%5Bd%5D%7D%7Bd%27%7D&bg=ffffff&fg=333333&s=0&c=20201002) . We now let the upper shadow of S be
. We now let the upper shadow of S be
![\partial^+(S):= \{A\in \binom{[d]}{d'+1}\,:\, \exists B\in S, B\subset A\},](https://s0.wp.com/latex.php?latex=%5Cpartial%5E%2B%28S%29%3A%3D+%5C%7BA%5Cin+%5Cbinom%7B%5Bd%5D%7D%7Bd%27%2B1%7D%5C%2C%3A%5C%2C+%5Cexists+B%5Cin+S%2C+B%5Csubset+A%5C%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
the sets in the (d’+1)-th layer which lie above some set in S. To apply Hall’s Marriage theorem, we have to show that 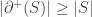 for all choice of S.
for all choice of S.
We double-count the number of edges in the hypercube from  to
to 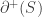 . Firstly, for every element
. Firstly, for every element 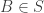 , there are exactly d’ relevant edges. Secondly, for every element
, there are exactly d’ relevant edges. Secondly, for every element 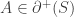 , there are exactly d’ edges to some element of , and so in particular there are at most d’ edges to elements of S. Thus
, there are exactly d’ edges to some element of , and so in particular there are at most d’ edges to elements of S. Thus
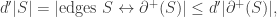
which is exactly what we require for Hall’s MT. The argument for the matching between other layers is the same, with a bit more notation, but also more flexibility, since it isn’t a perfect matching.
The second proof looks at maximal chains. Recall, in this context, a maximal chain is a sequence  where each
where each ![B_k:= \binom{[d]}{k}](https://s0.wp.com/latex.php?latex=B_k%3A%3D+%5Cbinom%7B%5Bd%5D%7D%7Bk%7D&bg=ffffff&fg=333333&s=0&c=20201002) . We now consider some largest-possible antichain
. We now consider some largest-possible antichain  , and count how many maximal chains include an element
, and count how many maximal chains include an element  . If
. If  , it’s easy to convince yourself that there are
, it’s easy to convince yourself that there are 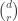 such maximal chains. However, given
such maximal chains. However, given 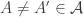 , the set of maximal chains containing A and the set of maximal chains containing A’ are disjoint, since is an antichain. From this, we obtain
, the set of maximal chains containing A and the set of maximal chains containing A’ are disjoint, since is an antichain. From this, we obtain
 (**)
(**)
Normally after a change of notation, so that we are counting the size of the intersection of the antichain with each layer, this is called the LYM inequality after Lubell, Yamamoto and Meshalkin. The heuristic is that the sum of the proportions of layers taken up by the antichain is at most one. This is essentially the same as earlier at (*). This argument can also be phrased probabilistically, by choosing a *random* maximal chain, and considering the probability that it intersects the proposed largest antichain, which is, naturally, at most one. Of course, the content is the same as this deterministic combinatorial argument.
Either way, from (**), the statement of Sperner’s theorem follows rapidly, since we know that  for all A.
for all A.
Largest antichain in the general grid
Instead of attempting a proof or even a digest of the argument in the general case, I’ll give a brief outline of why the previous arguments don’t transfer immediately. It’s pretty much the same reason for both approaches. In the hypercube, there is a lot of symmetry within each layer. Indeed, almost by definition, any vertex in the k-th layer can be obtained from any other vertex in the k-th layer just by permuting the labels (or permuting the coordinates if thinking as a vector).
The hypercube ‘looks the same’ from every vertex, but that is not true of the grid. Consider for clarity the n=8, d=3 case we discussed right at the beginning, and compare the scores (7,0,0) and (2,2,3). The number of maximal chains through (7,0,0) is  , while the number of maximal chains through (2,2,3) is
, while the number of maximal chains through (2,2,3) is 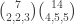 , and the latter is a lot larger, which means any attempt to use the second argument is going to be tricky, or at least require an extra layer of detail. Indeed, exactly the same problem arises when we try and use Hall’s condition to construct the optimal chain covering directly. In the double-counting section, it’s a lot more complicated than just multiplying by d’, as was the case in the middle of the hypercube.
, and the latter is a lot larger, which means any attempt to use the second argument is going to be tricky, or at least require an extra layer of detail. Indeed, exactly the same problem arises when we try and use Hall’s condition to construct the optimal chain covering directly. In the double-counting section, it’s a lot more complicated than just multiplying by d’, as was the case in the middle of the hypercube.
Largest antichain in the d=3 grid
We can, however, do the d=3 case. As we will see, the main reason we can do the d=3 case is that the d=2 case is very tractable, and we have lots of choices for the chain coverings, and can choose one which is well-suited to the move to d=3. Indeed, when I set this problem to some students, an explicit listing of a maximal chain covering was the approach some of them went for, and the construction wasn’t too horrible to state.
[Another factor is that it computationally feasible to calculate the size of the middle layer, which is much more annoying in d>3.]
[I’m redefining the grid here as 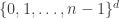 rather than .]
rather than .]
The case distinction between n even and n odd is going to make both the calculation and the argument annoying, so I’m only going to treat the even case, since n=8 was the original problem posed. I should be honest and confess that I haven’t checked the n odd case, but I assume it’s similar.
So when n is even, there are two middle layers namely 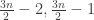 (corresponding to total score 10 and total score eleven in the original problem). I calculated the number of element in the
(corresponding to total score 10 and total score eleven in the original problem). I calculated the number of element in the  layer by splitting based on the value of the first coordinate. I found it helpful to decompose the resulting sum as
layer by splitting based on the value of the first coordinate. I found it helpful to decompose the resulting sum as

based on whether there is an upper bound, or a lower bound on the value taken by the second coordinate. This is not very interesting, and I obtained the answer  , and of course this is an integer, since n is even.
, and of course this is an integer, since n is even.
Now to show that any antichain has size at most . Here we use our good control on the chain coverings in the case d=2. We note that there is a chain covering of the (n,d=2) grid where the chains have 2n-1, 2n-3,…, 3, 1 elements (%). We get this by starting with a maximal chain, then taking a maximal chain on what remains etc. It’s pretty much the first thing you’re likely to try.
Consider an antichain with size A in the (n,d=3) grid, and project into the second and third coordinates. The image sets are distinct, because otherwise a non-trivial pre-image would be a chain. So we have A sets in the (n,d=2) grid. How many can be in each chain in the decomposition (%). Well, if there are more than n in any chain in (%), then two must have been mapped from elements of the (n,d=3) grid with the same first coordinate, and so satisfy a containment relation. So in fact there are at most n image points in any of the chains of (%). So we now have a bound of  . But of course, some of the chains in (%) have length less than n, so we are throwing away information. Indeed, the number of images points in a given chain is at most
. But of course, some of the chains in (%) have length less than n, so we are throwing away information. Indeed, the number of images points in a given chain is at most

and so the number of image points in total is bounded by

where there are n/2 copies of n in the first half of the sum. Evaluating this sum gives , exactly as we wanted.
References
[1] – Bollobas, Leader (1991) – Compressions and Isoperimetric Inequalities. Available open-access here.



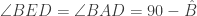




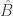


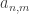 the number of forests with vertex set [n] consisting of m unrooted trees. Recall that if we were interested in rooted trees, we could appeal to Prufer codes to show that there are
the number of forests with vertex set [n] consisting of m unrooted trees. Recall that if we were interested in rooted trees, we could appeal to Prufer codes to show that there are 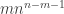 such forests, and indeed results of Pitman give a coalescent/fragmentation scheme as m varies between 1 and n-1. It seems that there is no neat combinatorial re-interpretation of the unrooted case though, so Britikov uses an analytic method.
such forests, and indeed results of Pitman give a coalescent/fragmentation scheme as m varies between 1 and n-1. It seems that there is no neat combinatorial re-interpretation of the unrooted case though, so Britikov uses an analytic method.
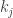 s correspond to the sizes of the m trees in the forest;
s correspond to the sizes of the m trees in the forest; 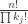 gives the multinomial number of ways to assign vertices to the trees; given the labels for a tree of size
gives the multinomial number of ways to assign vertices to the trees; given the labels for a tree of size 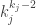 ways to make up the tree itself; and
ways to make up the tree itself; and  accounts for the fact that the trees have no order.
accounts for the fact that the trees have no order.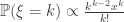 ,
,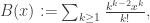
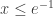 is precisely the condition for
is precisely the condition for 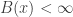 . Note now that if
. Note now that if 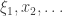 are IID copies of
are IID copies of  , then
, then

![\mathbb{E}[e^{it\xi}]=\frac{B(xe^{it})}{B(x)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Be%5E%7Bit%5Cxi%7D%5D%3D%5Cfrac%7BB%28xe%5E%7Bit%7D%29%7D%7BB%28x%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) , and it will be enough to clarify the behaviour of this as
, and it will be enough to clarify the behaviour of this as 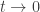 . It’s easier to work with a relation analytic function
. It’s easier to work with a relation analytic function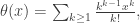
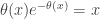 everywhere where
everywhere where 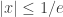 . We want to consider x=1/e, for which
. We want to consider x=1/e, for which 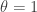 .
. , so we will make progress by relating
, so we will make progress by relating  in two ways. One way involves playing around with contour integrals in a fashion that is clear in print, but involves quite a lot of notation. The second way is the Renyi relation which asserts that
in two ways. One way involves playing around with contour integrals in a fashion that is clear in print, but involves quite a lot of notation. The second way is the Renyi relation which asserts that  . We will briefly give a combinatorial proof. Observe that after multiplying through by factorials and interpreting the square of a generating function, this is equivalent to
. We will briefly give a combinatorial proof. Observe that after multiplying through by factorials and interpreting the square of a generating function, this is equivalent to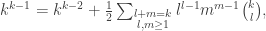
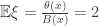 when x=1/e. If we wanted, we could show that the variance is infinite, which is not completely surprising, as the parameter x lies on the radius of convergence of the generating function.
when x=1/e. If we wanted, we could show that the variance is infinite, which is not completely surprising, as the parameter x lies on the radius of convergence of the generating function.![\mathbb{E}[ e^{it\xi}] = 1+2it + \frac{2}{3}i |2t|^{3/2} (i\mathrm{sign}(t))^{3/2} + o(|t|^{3/2}).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+e%5E%7Bit%5Cxi%7D%5D+%3D+1%2B2it+%2B+%5Cfrac%7B2%7D%7B3%7Di+%7C2t%7C%5E%7B3%2F2%7D+%28i%5Cmathrm%7Bsign%7D%28t%29%29%5E%7B3%2F2%7D+%2B+o%28%7Ct%7C%5E%7B3%2F2%7D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
 converges to
converges to  , where
, where  is a constant arising out of the previous step.
is a constant arising out of the previous step.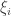 s taking a specific value, rather than a range of values on the scale of the fluctuations, we actually need a local limit theorem.
s taking a specific value, rather than a range of values on the scale of the fluctuations, we actually need a local limit theorem. and variance
and variance 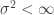 . Then the partial sums satisfy
. Then the partial sums satisfy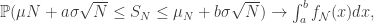
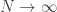 . But what about the probability of
. But what about the probability of 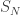 taking a particular value m that lies between
taking a particular value m that lies between  and
and  ? If the underlying distribution was continuous, this would be uncontroversial – considering the probability of lying in a range that is smaller than the scale of the CLT can be shown in a similar way to the CLT itself. A local limit theorem asserts that when the underlying distribution is supported on some lattice, mostly naturally the integers, then these probabilities are in the limit roughly the same whenever m is close to
? If the underlying distribution was continuous, this would be uncontroversial – considering the probability of lying in a range that is smaller than the scale of the CLT can be shown in a similar way to the CLT itself. A local limit theorem asserts that when the underlying distribution is supported on some lattice, mostly naturally the integers, then these probabilities are in the limit roughly the same whenever m is close to 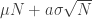 .
.
 , uniformly on any set of m for which
, uniformly on any set of m for which  is bounded. Conveniently, the two occurrences of b clear, and Britikov obtains
is bounded. Conveniently, the two occurrences of b clear, and Britikov obtains
 , so it is natural to consider adding some sort of labelling of the tree, where for each non-root vertex in turn there are three options. So, given a rooted tree T, we label the vertices such that the root has label 0, and if a parent vertex has label k, any offspring has label k-1, k or k+1. Such a labelling is called admissable, and
, so it is natural to consider adding some sort of labelling of the tree, where for each non-root vertex in turn there are three options. So, given a rooted tree T, we label the vertices such that the root has label 0, and if a parent vertex has label k, any offspring has label k-1, k or k+1. Such a labelling is called admissable, and 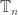 is the set of rooted plane trees with n edges and an admissable labelling.
is the set of rooted plane trees with n edges and an admissable labelling. from an element of
from an element of  , with a single corner (ie no edges yet) and denote this corner to be the successor of the corners in the original tree with minimal label.
, with a single corner (ie no edges yet) and denote this corner to be the successor of the corners in the original tree with minimal label.
 to be the family of rooted plane maps with n edges. The root is a distinguished oriented edge. Our aim is to count the size of this set.
to be the family of rooted plane maps with n edges. The root is a distinguished oriented edge. Our aim is to count the size of this set.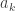 the number of plane trees with k edges, we can define a generating function via
the number of plane trees with k edges, we can define a generating function via  . If the root vertex v has no offspring, this gives one possibility corresponding to k=0. Otherwise, there is a well-defined left-most offspring of the root, called u. Then u and its descendents form a plane tree, and v and its descendents apart from those through u also form a plane tree. So after accounting for the edge between u and v, we obtain
. If the root vertex v has no offspring, this gives one possibility corresponding to k=0. Otherwise, there is a well-defined left-most offspring of the root, called u. Then u and its descendents form a plane tree, and v and its descendents apart from those through u also form a plane tree. So after accounting for the edge between u and v, we obtain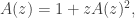
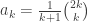 .
.
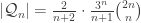 . This may not look like we have achieved much, but we can now apply Euler’s formula to any quadrangulation in this set to deduce that the number of vertices present is n+2. If we consider the set
. This may not look like we have achieved much, but we can now apply Euler’s formula to any quadrangulation in this set to deduce that the number of vertices present is n+2. If we consider the set  , where now we identify a particular vertex
, where now we identify a particular vertex 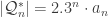 , where
, where  is the nth Catalan number as before. Now we have the most efficient setup to look for a bijection with some type of decorated plane tree as discussed before.
is the nth Catalan number as before. Now we have the most efficient setup to look for a bijection with some type of decorated plane tree as discussed before.


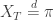 . Note that there is one trivial way to do this. We can sample Y from distribution
. Note that there is one trivial way to do this. We can sample Y from distribution  before starting the process, then stop X at the first time T for which
before starting the process, then stop X at the first time T for which  . But this is no help really, as we need to have Y in the first place!
. But this is no help really, as we need to have Y in the first place!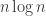 , where n is the number of cards.
, where n is the number of cards.![\phi: S\times[0,1]\rightarrow S,\text{ s.t. }\mathbb{P}(\phi(i,U)=j)=p_{ij},](https://s0.wp.com/latex.php?latex=%5Cphi%3A+S%5Ctimes%5B0%2C1%5D%5Crightarrow+S%2C%5Ctext%7B+s.t.+%7D%5Cmathbb%7BP%7D%28%5Cphi%28i%2CU%29%3Dj%29%3Dp_%7Bij%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
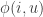 as i varies, to obtain a random map
as i varies, to obtain a random map  . Crucially, this map is not necessarily a bijection.
. Crucially, this map is not necessarily a bijection. . For some chains, and some representations, in particular random walks on vertex-transitive graphs (such as SRW – only for now we are restricting attention to finite state spaces) it is possible to choose
. For some chains, and some representations, in particular random walks on vertex-transitive graphs (such as SRW – only for now we are restricting attention to finite state spaces) it is possible to choose 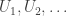 be an IID sequence of U[0,1] random variables, and write
be an IID sequence of U[0,1] random variables, and write  for the random map induced by
for the random map induced by  . Then consider the sequence of iterated maps:
. Then consider the sequence of iterated maps:
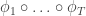 is a single state. Ie, as we go backwards in time through the maps
is a single state. Ie, as we go backwards in time through the maps 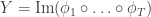
 , we can choose N such that the probability the algorithm stops in at most N steps is greater than
, we can choose N such that the probability the algorithm stops in at most N steps is greater than  .
.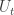 . Thus at time 0, the distribution of the chain is still the equilibrium distribution. But if we condition on the event that
. Thus at time 0, the distribution of the chain is still the equilibrium distribution. But if we condition on the event that 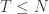 , then
, then 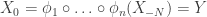 regardless of the initial value. So
regardless of the initial value. So  , and hence the result follows, since
, and hence the result follows, since 



 .
. . Typically these will be the sizes of various combinatorial sets. Eg a_n = number of partitions of [n] with some property. Define the generating function of the sequence to be:
. Typically these will be the sizes of various combinatorial sets. Eg a_n = number of partitions of [n] with some property. Define the generating function of the sequence to be:

![[x^k]g(x)](https://s0.wp.com/latex.php?latex=%5Bx%5Ek%5Dg%28x%29&bg=ffffff&fg=333333&s=0&c=20201002) to denote the coefficient of
to denote the coefficient of 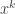 in the power series g(x). So, if
in the power series g(x). So, if 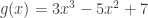 , then
, then ![[x^2]g(x)=-5](https://s0.wp.com/latex.php?latex=%5Bx%5E2%5Dg%28x%29%3D-5&bg=ffffff&fg=333333&s=0&c=20201002) . It hopefully should never be relevant unless you read some other notes on the topic, but the notation
. It hopefully should never be relevant unless you read some other notes on the topic, but the notation ![[\alpha x^2]g(x):=\frac{[x^2]g(x)}{\alpha}](https://s0.wp.com/latex.php?latex=%5B%5Calpha+x%5E2%5Dg%28x%29%3A%3D%5Cfrac%7B%5Bx%5E2%5Dg%28x%29%7D%7B%5Calpha%7D&bg=ffffff&fg=333333&s=0&c=20201002) , which does make sense after a while.
, which does make sense after a while. appear, as the name suggests, as coefficients of
appear, as the name suggests, as coefficients of
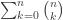 and
and  by substituting
by substituting  into f_n.
into f_n.

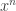 in the product
in the product 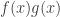 , and it is now clear that
, and it is now clear that ^{a+b}](https://s0.wp.com/latex.php?latex=%5Cbinom%7Ba%2Bb%7D%7Bn%7D%3D%5Bx%5En%5D%281%2Bx%29%5E%7Ba%2Bb%7D&bg=ffffff&fg=333333&s=0&c=20201002) , while
, while^a(1+x)^b,](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk%2Bl%3Dn%7D%5Cbinom%7Ba%7D%7Bk%7D%5Cbinom%7Bb%7D%7Bl%7D%3D%5Bx%5En%5D%281%2Bx%29%5Ea%281%2Bx%29%5Eb%2C&bg=ffffff&fg=333333&s=0&c=20201002)
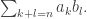
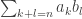 .
.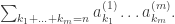
 s will all be the same. We don’t even have to specify how many k_i’s there are to be considered. After all, if we want the sum to be n, then only finitely many can be non-zero. So:
s will all be the same. We don’t even have to specify how many k_i’s there are to be considered. After all, if we want the sum to be n, then only finitely many can be non-zero. So:![\sum_{m}\sum_{k_1+\ldots+k_m=n}a_{k_1}\ldots a_{k_m}=[x^n]f(x)^n=[x^n]f(x)^\infty,](https://s0.wp.com/latex.php?latex=%5Csum_%7Bm%7D%5Csum_%7Bk_1%2B%5Cldots%2Bk_m%3Dn%7Da_%7Bk_1%7D%5Cldots+a_%7Bk_m%7D%3D%5Bx%5En%5Df%28x%29%5En%3D%5Bx%5En%5Df%28x%29%5E%5Cinfty%2C&bg=ffffff&fg=333333&s=0&c=20201002)

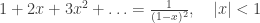

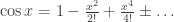
 , and sort out convergence later if necessary.
, and sort out convergence later if necessary.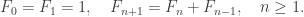
![[x^n]F(x)=[x^{n-1}]F(x)+[x^{n-2}]F(x)=[x^n](xF(x)+x^2F(x)),](https://s0.wp.com/latex.php?latex=%5Bx%5En%5DF%28x%29%3D%5Bx%5E%7Bn-1%7D%5DF%28x%29%2B%5Bx%5E%7Bn-2%7D%5DF%28x%29%3D%5Bx%5En%5D%28xF%28x%29%2Bx%5E2F%28x%29%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
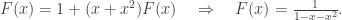
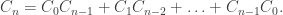
 such that
such that 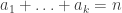 . Let p(n) be the number of partitions of [n].
. Let p(n) be the number of partitions of [n].

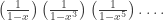

 , then you can encode this with the bivariate generating function
, then you can encode this with the bivariate generating function
![[x^ay^b]](https://s0.wp.com/latex.php?latex=%5Bx%5Eay%5Eb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and so on. There’s some interesting stuff on counting lattice paths with this method.
and so on. There’s some interesting stuff on counting lattice paths with this method. and
and  by judicious choice of x in f(x). By taking half the sum or half the difference, we can obtain
by judicious choice of x in f(x). By taking half the sum or half the difference, we can obtain
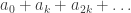 , this is given by:
, this is given by:
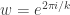 is a $k$th root of unity. Exercise: Prove this.
is a $k$th root of unity. Exercise: Prove this. . We might consider a unicyclic graph to be a tree with an extra edge. But if we consider the number of ways to add a further vertex to a tree, we get
. We might consider a unicyclic graph to be a tree with an extra edge. But if we consider the number of ways to add a further vertex to a tree, we get![n^{n-2}\left[\binom{n}{2}-(n-1)\right]=n^{n-2}\binom{n-1}{2}.](https://s0.wp.com/latex.php?latex=n%5E%7Bn-2%7D%5Cleft%5B%5Cbinom%7Bn%7D%7B2%7D-%28n-1%29%5Cright%5D%3Dn%5E%7Bn-2%7D%5Cbinom%7Bn-1%7D%7B2%7D.&bg=ffffff&fg=333333&s=0&c=20201002)

 is the number of partitions of [n] with k blocks. Remember that the blocks in a partition are necessarily unordered. This makes sense in this setting as the cyclic permutation chosen from the (k-1)! possibilities specifies the order on the cycle.
is the number of partitions of [n] with k blocks. Remember that the blocks in a partition are necessarily unordered. This makes sense in this setting as the cyclic permutation chosen from the (k-1)! possibilities specifies the order on the cycle.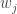 arrangements of any block of size j, and there are
arrangements of any block of size j, and there are 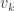 ways to arrange the blocks, if there are k of them. Note that we assume
ways to arrange the blocks, if there are k of them. Note that we assume  , and
, and  . Pitman denotes these sequences by
. Pitman denotes these sequences by  . Then the (n,k)th partial Bell polynomial,
. Then the (n,k)th partial Bell polynomial, 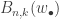 gives the number of divisions into k blocks:
gives the number of divisions into k blocks:
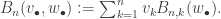
 give the number of permutations of [n] with k cycles. Since we don’t want to impose any combinatorial structure on the set of cycles, we don’t need to consider
give the number of permutations of [n] with k cycles. Since we don’t want to impose any combinatorial structure on the set of cycles, we don’t need to consider  , and the number of ways to make a j-cycle from a j-block is
, and the number of ways to make a j-cycle from a j-block is  , so
, so  . Similarly, the Stirling numbers of the second kind
. Similarly, the Stirling numbers of the second kind 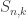 give the number of permutations of [n] into k blocks. Almost by definition,
give the number of permutations of [n] into k blocks. Almost by definition,  , where $1^\bullet$ is defined to be the sequence containing all 1s.
, where $1^\bullet$ is defined to be the sequence containing all 1s. , it is clear why there are
, it is clear why there are  ordered partitions encoding this structure. This multinomial coefficient can be written as a product of factorials of $n_i$s over i, and so we can write:
ordered partitions encoding this structure. This multinomial coefficient can be written as a product of factorials of $n_i$s over i, and so we can write:
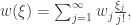
![B_{n,k}(w_\bullet)=n![\xi^n]\frac{w(\xi)^k}{k!},\quad B_n(v_\bullet,w_\bullet)=n![\xi^n]v(w(\xi)).](https://s0.wp.com/latex.php?latex=B_%7Bn%2Ck%7D%28w_%5Cbullet%29%3Dn%21%5B%5Cxi%5En%5D%5Cfrac%7Bw%28%5Cxi%29%5Ek%7D%7Bk%21%7D%2C%5Cquad+B_n%28v_%5Cbullet%2Cw_%5Cbullet%29%3Dn%21%5B%5Cxi%5En%5Dv%28w%28%5Cxi%29%29.&bg=ffffff&fg=333333&s=0&c=20201002)
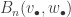 counts the number of partitions of [n] subject to some extra structure. If we choose uniformly from this set, we get a distribution on this combinatorial object, for which the Bell polynomial provides the normalising constant. If we then ignore the extra structure, the sequences
counts the number of partitions of [n] subject to some extra structure. If we choose uniformly from this set, we get a distribution on this combinatorial object, for which the Bell polynomial provides the normalising constant. If we then ignore the extra structure, the sequences 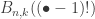 and there is certainly no simple form for this, so the possibility of doing a technical limiting argument seems slim.
and there is certainly no simple form for this, so the possibility of doing a technical limiting argument seems slim.
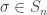 and a colouring of [n] with k colours such that the orbits of
and a colouring of [n] with k colours such that the orbits of  are monochromatic. We prove that the LHS also has this property by induction on the number of vertices. We claim there is a 1-to-(x+n) map from configurations on n vertices to configurations on (n+1) vertices. Given
are monochromatic. We prove that the LHS also has this property by induction on the number of vertices. We claim there is a 1-to-(x+n) map from configurations on n vertices to configurations on (n+1) vertices. Given ![a\in[n]](https://s0.wp.com/latex.php?latex=a%5Cin%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , we construct
, we construct  by
by  ,
,  and for all other x,
and for all other x, 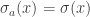 . We give n+1 the same colour as a. This gives us n possibilities. Alternatively, we can map (n+1) to itself and give it any colour we want. This gives us x possibilities. A slightly more careful argument shows that this is indeed a 1-to-(x+n) map, which is exactly what we require.
. We give n+1 the same colour as a. This gives us n possibilities. Alternatively, we can map (n+1) to itself and give it any colour we want. This gives us x possibilities. A slightly more careful argument shows that this is indeed a 1-to-(x+n) map, which is exactly what we require.


