
You have N counters serving customers. What is a better arrangement? To have N queues, one for each counter, as in a supermarket (in the heady days before self-checkout, when ‘something unexpected in the bagging area’ might necessitate a trip to the doctor); or a single queue feeding to counters when they become free, as at a train station, or airport passport control?
Queueing is a psychologically intense process, at least in this country. Here are some human points:
– When you have to choose your line, you might, if you have nothing better to do, spend your time in the queue worrying about whether you chose optimally; whether Fortune has given a customer who arrived after you an advantage. (*)
– A single queue feels long, but conversely gives its users the pleasing feeling of almost constant progress. A particularly difficult customer doesn’t have as great an effect.
Interestingly, we can qualify these remarks in purely mathematical terms. We shall see that the mean waiting times are the same, but that, as we might expect, the variance is less for the single queue.
So to begin, we assume that the arrival process is Poisson, and the service times are exponential. These assumptions are very much not required, but it makes it easier to set up the model as a Markov chain. We do need that 
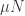

We assume that in the N-queues arrangement, if a counter is free but the corresponding queue is empty, then a customer from a non-zero queue will take the place if possible. We do not worry about how this customer is chosen. Indeed, we do not concern ourselves with how the customers choose a queue, except to ask that the choice algorithm is previsible. That is, they cannot look into the future and optimise (or otherwise) accordingly. This assumption is standard and reasonable by considering the real-world situation.
Now if we set things up in the right way, we can couple the two processes. Precisely, we start with no customers, and define

to be the sequence of arrival times (note that almost surely no two customers arrive at the same time). Now say that
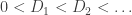
are the times at which a customer starts being served, that is, moves from the queue to the counter. Say 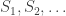


The important point is that service times are independent of the queueing process, and are i.i.d. This is where we use the fact that the queue choice strategies are previsible. So, in fact all we need to examine is how customers spend in the queue. Concretely, take Q the queueing time, and S the service time. These are independent so:
![\mathbb{E}[Q+S]=\mathbb{E}Q+\mathbb{E}S](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BQ%2BS%5D%3D%5Cmathbb%7BE%7DQ%2B%5Cmathbb%7BE%7DS&bg=ffffff&fg=333333&s=0&c=20201002)
and 
Observe that 
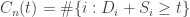
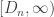
the number of the first n customers being served at time t, we have
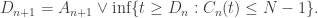
Therefore, by induction on n, we have that 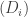
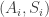
We can also define, for both models, the number of customers served before the queue is empty again as:
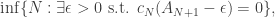
ie, the least N for which the queue is empty just before the N+1-th customer arrives. As previously discussed, N is a.s. finite. The processes are Markov chains, the first time the queue is empty is a stopping time, and it is meaningful to consider the average waiting time of the N customers before the queue is empty again. There is an expectation over N implicit here too, but this won’t be necessary for our result.
We can now finish the proof. This mean waiting time is

for the single queue. For multiple queues, suppose the i-th customer to arrive is the 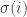
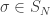

which is clearly equal to the previous expression as we can reorder a finite sum.
For variance, we have to consider
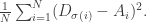
Observe that for 
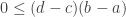

which we can then apply repeatedly to show that

with equality precisely when 
References
This problem comes from Examples Sheet 1 of the Part III course Stochastic Networks. An official solution of the same flavour as this is also linked from the course page.
Related articles
- Improving Queues Management of McDonald (thinkingbookworm.typepad.com)
- Shorter border control queues for people on ‘low-risk’ flights (thisislondon.co.uk)
- How Home Depot tackles queues (operationsroom.wordpress.com)

Nice! May I ask if it possible to model some other phenomena? For instance, in a supermarket (or at a train station, for that matter), if the queue builds up, they open another desk. Is it possible (and desirable) to model that in as well, or do you think it won’t change the result too much (or make the maths annoyingly hard)?
I think it should be possible to model that. If you supply well-behaved (ie probably exponential, linear or logarithmic for the calculation to be doable) cost functions to the waiting times and the number of checkouts open, I doubt it is that hard to optimise for the number of checkouts to operate.
Making this number is dynamic may on first inspection be annoying, as it would be hard to specify a rule for opening and closing extra checkouts. Eg, suppose you started with a single server, and say that if and when a tenth person arrives at the queue you open a second checkout. This seems reasonable, but when should you close this second one? In particular, because this new server is immediately occupied, the size of the queue becomes 9, and thus the number of servers is not a function of the queue size. This makes it much more complicated to describe as a Markov chain.
However. So long as everything in the operation is a function of S, A and D as described, then the overall result will be the same. That is, no matter how complicated you make something, for a single queue the order is preserved whereas for many queues it isn’t. If the arrival and departure times are the same, then the single queue will always have lower variance.
Pingback: Simple Queues | Eventually Almost Everywhere
Pingback: Understanding the Queue: An In-depth Look into the Concept in American English – englishraven.com