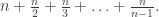This post is aimed at secondary-school students pitched roughly at the level of the British Mathematical Olympiad. It is ostensibly about a certain class of number theory problems, but the main underlying mathematical principle is broader than this. The post is based on an in-person session I have given to students and at teachers’ conferences a few times over the past five years, but I’ve chosen to write it up at this moment because of the connection to Problem 4 on the most recent BMO1 paper, which we discuss later in the post.
Prologue
Alice and Bob make the following statements:
- Alice: all prime numbers are odd.
- Bob: we can’t say anything about whether prime numbers are odd or even.
These are different types of statement, one objective, one more subjective; but both are wrong. Alice is wrong because 2 is a prime, and 2 is of course even. Bob is wrong because while Alice is wrong, and the alternative statement “all prime numbers are even” is even more wrong1, there are plenty of possible statements that are true and useful, including
- Cleo: all prime numbers are odd except 2.
and weaker versions (that may be more relevant in other contexts) like “all primes greater than 
The characters now turn their attention to another family of integers, the square numbers 

- Alice: no square numbers are prime.
- Bob: I agree.
- Alice: most square numbers are not sixth powers.
- Bob: hang on, but infinitely many square numbers are sixth powers?
The difficulty in the second statement is what does most mean in this context? The square of an integer n is a sixth power if and only if n is a cube, and so Alice’s statement is equivalent to the statement “most positive integers are not cubes”, which is intuitively reasonable, but would require more clarification than the analogous statement “most primes are odd”. Is it not relevant, for example, that 1/4 of the first eight positive integers are in fact cubes?
It is not impossible to formalise this notion of most in a reasonable way to permit the two statements above2.
But the bulk of this post will discuss situations that extend the first of these conversations, ie when it’s not true to say “all element of X have property Y”, but where it’s nonetheless possible to make a useful intermediate statement.
Warmup problems
I hope most readers know how to solve an equation such as

and indeed learning how to solve such equations forms a important milestone in mathematical education as the first example of various principles of algebra. When such equations are still novel, teachers would be advised to avoid examples such as

for which the answers are, respectively, ‘no solutions’ and ‘every x satisfies this’. While they are perfectly valid equations, it means something slightly different to solve them, since the answer set has different structure and, more importantly, the method is different since it doesn’t consist of a sequence of a manipulations leading directly to the required conclusion 
However, I mention this in passing to clarify that even in the simplest possible family of equations (probably encountered somewhere between ages 9 and 13) we are mindful that not all equations have unique solutions.
I’ve adapted a problem from the American competition AIME:
Find all integers 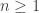

One could start by writing 

which is never a prime, since 
So at a meta-level, comparing with the other problem in this section, this one also begins with reversible algebraic manipulations, but does not end with a direct reduction to ![n = [...]](https://s0.wp.com/latex.php?latex=n+%3D+%5B...%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Finally, we remark that the original version of the AIME problem was
Prove that for all integers 
The same algebraic reduction as (*) resolves the original version without an extra step concerning primes.
To be, or not to be, a perfect square
The rest of this article will focus entirely on problems of the form: find all positive integers n such that […] is a perfect square.
As setup, we’ll always consider a function f(n), and the sequence f(1),f(2),f(3),… and the question, comment on the set of n is f(n) a square? In particular, this is a more open-ended question than for which n is f(n) a square, which requires a more exact answer. We’ll aim for one of the following possible answers:
- f(n) is always a square;
- f(n) is a square for infinitely many n;
- f(n) is a square for only finitely many n;
- f(n) is never a square.
Clearly this is not an exhaustive list of possible descriptions3 of the set under discussion, but it will do for now. The difference between the second and the third bullet point can be thought of as: “are there arbitrarily large values of n for which f(n) is a square?”
As some examples:
is never a square, because the only squares that differ by 1 are {0,1} which aren’t attainable when
is a square for only finitely many n, because the only squares that differ by 3 are {1,4}.
Exercises to try yourself
,
- or, now with p ranging over the set of prime numbers:
.
Some discussion of some of these follows later to avoid spoilers.
BMO1 2023, Problem 4

This problem does not have exactly the same structure as the previous exercise. A solution will follow shortly, but before starting, [spoilers] I want to emphasise that the main part of the solution involves framing this problem exactly as in the exercise above.
- We will establish that there are only finitely many n such that
is a square, using a classical number theory argument.
- In doing so, we will eliminate all integers n that are at least some threshold value K from consideration (which we think of as “n large”, even though in this case it isn’t so large).
- The actual set of solutions comes from check the remaining “small” values of n.
- The point to emphasise is that while this third bullet is definitely an important component of a successful solution (and does feel closest to actually addressing the “find all” aspect of the problem statement), it is not really the key step, since checking a small number of possibilities is fundamentally much more straightforward than an argument to eliminate the other infinitely-many integers.
This overall structure is very common when solving Diophantine equations involving integers, even if the exact statement isn’t “find all n such that […] is a perfect square”.
Anyway, to the solution of this problem. As in many problems of this difficulty in this number theory, it’s really useful to aim to factorise and analyse the factors, remembering that they are integers! In this case, writing 


Here the two factors are (k-1) and (k+1). We know nothing about k, so we know nothing intrinsic about these factors, except that they differ by 2. But now when we consider that their product is 
- (k-1) and (k+1) differ by two, and so have the same parity5. Then
- But more than this, one factor will be a multiple of 4, while the other will not be. So all the powers of 2 within
- The idea is that
is generally much larger than n, and so this will force one of the factors to be much larger than the other factor, which is not permitted. (Recall that the factors differ by 2.)
So formally, we might write that 




and we now have exactly the language to describe the truth of this inequality! It is only true for finitely many positive integers n. There are a number of ways to prove this, but it is important that we do provide a lower bound. One possibility is to check that (*) holds for n=5, and then prove (*) for all 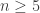
At this point, we have shown that 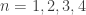

To link this to the background, note that this final procedure of “finding all the solutions” really had nothing in common structure-wise with “solving 
Comments on exercises
is a square for infinitely many n, while
is never a square, for reasons that are often framed in the language of quadratic residues.
is a square only when n=3, which can be seen via a similar argument to the argument above for the BMO problem. Meanwhile
is never a square, which can also be checked using quadratic residues.
is a square for infinitely many n (specifically, when
), while
is only a square for finitely many n, because when n is large, we have
. This style of argument is sometimes called square-sandwiching, although it can of course be deployed in contexts other than squares. Problems that turn on this method have appeared in BMO surprisingly often in the past 15 years. For this particular example, note that one does have to check a handful of values to confirm it is for finitely many but at least one n (rather than for no n).
Footnotes
- of course, writing even more wrong is in itself making a nuanced comment about the parity of the prime numbers. ↩︎
- given a set
, a natural formalisation of the notion that ‘most integers are not in A’ would be that
In other words, the proportion of elements of A amongst the first n integers vanishes as
. This is certainly true when A is the set of cubes.
There are many sets for which this limit does not exist, including quite natural sets like the integers whose decimal representation starts with a 1, and so a full treatment of this notion of asymptotic density would require more than a footnote. ↩︎ - in particular, we might wish to draw a distinction between f(n) is a square for infinitely many n and the stronger statement f(n) is a square for all-but-finitely many n, and in some applications that difference is crucial. ↩︎
- A common error is to make some reasonable-sounding assumption about how the factors of
are split between (k-1) and (k+1), for example by assuming that
and
because this is visually a natural way to pair them up. ↩︎
- parity refers to whether a number is odd or even. ↩︎




 is its circumcircle. The tangents
is its circumcircle. The tangents 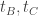 at B,C respectively meet at L. The line through B parallel to AC meets
at B,C respectively meet at L. The line through B parallel to AC meets  at D. The line through C parallel to AB meets
at D. The line through C parallel to AB meets 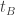 at E. The circumcircle of triangle BCD meets AC internally at T. The circumcircle of triangle BCE meets AB extended at S. Prove that ST, BC and AL are concurrent.
at E. The circumcircle of triangle BCD meets AC internally at T. The circumcircle of triangle BCE meets AB extended at S. Prove that ST, BC and AL are concurrent.
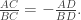

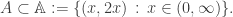
 , on the grounds that any pair is possible. Suppose that your friend has chosen the pair of values according to some distribution on
, on the grounds that any pair is possible. Suppose that your friend has chosen the pair of values according to some distribution on  , which we’ll assume has a density f, which is known by you. Maybe this isn’t the actual density, but it serves perfectly well if you treat it as *your* opinion on the likelihood. Then this actually does reduce to a problem along the lines of first-year probability, whether or not you get to see the amount in your envelope.
, which we’ll assume has a density f, which is known by you. Maybe this isn’t the actual density, but it serves perfectly well if you treat it as *your* opinion on the likelihood. Then this actually does reduce to a problem along the lines of first-year probability, whether or not you get to see the amount in your envelope.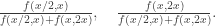

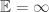
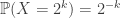 for k=1,2,…, which is the content of the *St. Petersburg paradox*, another supposed paradox in probability, but one whose resolution is a bit more clear.
for k=1,2,…, which is the content of the *St. Petersburg paradox*, another supposed paradox in probability, but one whose resolution is a bit more clear.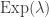 . So the mean of this smaller number is
. So the mean of this smaller number is 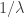 . Then, conditional on seeing x in my envelope, the expected value of the number in the other envelope is
. Then, conditional on seeing x in my envelope, the expected value of the number in the other envelope is (*)
(*)
 . The shape of this interval should fit our intuition, namely that the optimal strategy should be to switch if the value in your envelope is small enough.
. The shape of this interval should fit our intuition, namely that the optimal strategy should be to switch if the value in your envelope is small enough. , we should switch on seeing x precisely if
, we should switch on seeing x precisely if
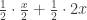 , you are doing a conditional expectation, and it’s got to be conditional with respect to something. Here it’s the uniform prior, or at least the uniform prior restricted to the set of values that are now possible given the revelation of your number.
, you are doing a conditional expectation, and it’s got to be conditional with respect to something. Here it’s the uniform prior, or at least the uniform prior restricted to the set of values that are now possible given the revelation of your number.![\mathbb{E}\left[X|Y\right]>Y,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BX%7CY%5Cright%5D%3EY%2C&bg=ffffff&fg=333333&s=0&c=20201002)



 for large N, we get a non-trivial limit.
for large N, we get a non-trivial limit.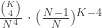 . Now, if
. Now, if 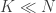 , this final term should not be significant. Removing this is not exactly the same as specifying the probability that at least four birthdays are on January 1st. But in fact this removal turns a lower bound (because {exactly four}<{at least four}) into an upper (in fact a union) bound. So if the factor being removed is very close to one, we can use whichever expression is more convenient.
, this final term should not be significant. Removing this is not exactly the same as specifying the probability that at least four birthdays are on January 1st. But in fact this removal turns a lower bound (because {exactly four}<{at least four}) into an upper (in fact a union) bound. So if the factor being removed is very close to one, we can use whichever expression is more convenient.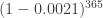 to estimate the probability that we never have four-overlap? When we did our previous iterative calculation, we were using independence of the different kids’ birthdays. But the event that we have four-overlap on January 1st is not quite independent of the event that we have four-overlap on January 2nd. Why? Well if we know at least four people were born on January 1st, there are fewer people left (potentially) to be born on January 2nd. But maybe this dependence is mild enough that we can ignore it?
to estimate the probability that we never have four-overlap? When we did our previous iterative calculation, we were using independence of the different kids’ birthdays. But the event that we have four-overlap on January 1st is not quite independent of the event that we have four-overlap on January 2nd. Why? Well if we know at least four people were born on January 1st, there are fewer people left (potentially) to be born on January 2nd. But maybe this dependence is mild enough that we can ignore it?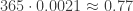 . So the probability that there is at least one day with four-overlap is at most ~0.77.
. So the probability that there is at least one day with four-overlap is at most ~0.77.

 such events, and each is independent of the collection of
such events, and each is independent of the collection of 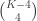 disjoint events. Thus we can consider using LLL if
disjoint events. Thus we can consider using LLL if  . Unfortunately, this difference of binomial coefficients is large in our example, and so in fact the LHS has order
. Unfortunately, this difference of binomial coefficients is large in our example, and so in fact the LHS has order 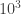 .
. for the distribution of birthdays in the model with a random number of friends
for the distribution of birthdays in the model with a random number of friends (*)
(*)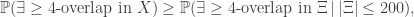

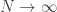 . Here, though, let’s just take L=365/2 and see what happens. For (*) we get ~0.472.
. Here, though, let’s just take L=365/2 and see what happens. For (*) we get ~0.472. , observe that this event corresponds to 1.4 standard deviations above the mean, so we can approximate using quantiles of the normal distribution, via the CLT. (Obviously this isn’t completely precise, but it could be made precise if we really wanted.) I looked up a table, and this probability is, conveniently for calculations, roughly 0.1. Thus we obtain a lower bound of
, observe that this event corresponds to 1.4 standard deviations above the mean, so we can approximate using quantiles of the normal distribution, via the CLT. (Obviously this isn’t completely precise, but it could be made precise if we really wanted.) I looked up a table, and this probability is, conveniently for calculations, roughly 0.1. Thus we obtain a lower bound of 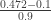 . Allowing for the fairly weak estimates at various points, we still get a lower bound of around 0.4. Which is good, because it shows that my intuition wasn’t right, but that I was in the right ball-park for it being a ‘middle-probability event’.
. Allowing for the fairly weak estimates at various points, we still get a lower bound of around 0.4. Which is good, because it shows that my intuition wasn’t right, but that I was in the right ball-park for it being a ‘middle-probability event’. . There are also some good general asymptotics, or at least recipes for asymptotics, in equations (17) and (18).
. There are also some good general asymptotics, or at least recipes for asymptotics, in equations (17) and (18).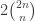 , but after a bit more thought is clearly not symmetric enough.
, but after a bit more thought is clearly not symmetric enough.
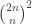 .
.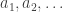 of positive integers satisfying
of positive integers satisfying  .
.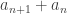 to be perfect squares. It seemed just about possible that we could arbitrarily large finite sequences with this property. (Though this also turns out to be impossible.)
to be perfect squares. It seemed just about possible that we could arbitrarily large finite sequences with this property. (Though this also turns out to be impossible.)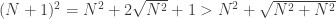 . So this seemed like a very good idea, and my instinct was that this should work, and I felt glad that I hadn’t pursued the quadratic residues approach.
. So this seemed like a very good idea, and my instinct was that this should work, and I felt glad that I hadn’t pursued the quadratic residues approach.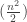 , and the answer was no as
, and the answer was no as
 , we have
, we have 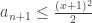 . This is clearly a problem or at best a very tight constraint if all the
. This is clearly a problem or at best a very tight constraint if all the  have to be perfect squares, so even though we aren’t completely finished, I am confident I can be in one or two lines, with a bit of care. Fiddling with small values of n looked like it would work, or showing that looking at a large enough initial subsequence that the effect of the first two terms dissipated, we must by the pigeonhole principle have
have to be perfect squares, so even though we aren’t completely finished, I am confident I can be in one or two lines, with a bit of care. Fiddling with small values of n looked like it would work, or showing that looking at a large enough initial subsequence that the effect of the first two terms dissipated, we must by the pigeonhole principle have 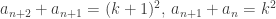 , which is enough by a parity argument, using the original statement.
, which is enough by a parity argument, using the original statement. can’t actually be
can’t actually be 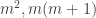 respectively. Suddenly this seems great, because we’ve actually solved the problem for a huge range of n, ie everything not within between these extrema.
respectively. Suddenly this seems great, because we’ve actually solved the problem for a huge range of n, ie everything not within between these extrema.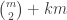 .
. years of this website’s existence.
years of this website’s existence.

 years, but for now, I’m still enjoying the journey through mathematics.
years, but for now, I’m still enjoying the journey through mathematics.





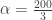 .
. ” dominates the strategy “pick y”, because we always do at least as well with the first strategy as the second, regardless of what the other players do, and indeed in some cases do strictly better. Now comes the potentially philosophical bit. We have concluded that it would be irrational for us to pick any number greater than
” dominates the strategy “pick y”, because we always do at least as well with the first strategy as the second, regardless of what the other players do, and indeed in some cases do strictly better. Now comes the potentially philosophical bit. We have concluded that it would be irrational for us to pick any number greater than 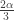 . This equally applies to all the other agents, and so we continue, showing that for any k, it is irrational to pick any number greater than
. This equally applies to all the other agents, and so we continue, showing that for any k, it is irrational to pick any number greater than  . In conclusion, the only rational strategy is to pick 0, and hence everyone will do this.
. In conclusion, the only rational strategy is to pick 0, and hence everyone will do this.![\max_{x\in[k]} \mathbb{P}(x) \rightarrow 0](https://s0.wp.com/latex.php?latex=%5Cmax_%7Bx%5Cin%5Bk%5D%7D+%5Cmathbb%7BP%7D%28x%29+%5Crightarrow+0&bg=ffffff&fg=333333&s=0&c=20201002) ) has this property.
) has this property. . Taking
. Taking  , the asymptotic distribution of the number of 1s is Poisson with parameter
, the asymptotic distribution of the number of 1s is Poisson with parameter  .
.


 . Note that the number of atoms in the universe is *only* about
. Note that the number of atoms in the universe is *only* about 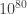 , so if we are going to write down this list, we better have very compact handwriting! But being serious, this number is way too large to realistically compute with, so we have to come up with some cleverer methods.
, so if we are going to write down this list, we better have very compact handwriting! But being serious, this number is way too large to realistically compute with, so we have to come up with some cleverer methods.