
Taking a course on Large Deviations has forced me to think a bit more carefully about what happens when you have large collections of IID random variables. I guess the first thing think to think about is ‘What is a Large Deviation‘? In particular, how large or deviant does it have to be?
Of primary interest is the tail of the distribution function of 



where 



Throughout, we lose no generality by assuming that 
Now let’s consider the implications of our choice of 



On the other hand, if 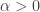

and more information to be required when 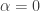
Instead, I want to return to the Central Limit Theorem. I first encountered this result in popular science books in a vague “the histogram of boys’ heights looks like a bell” kind of way, then, once a normal random variable had been to some extent defined, it returned in A-level statistics courses in a slightly more fleshed out form. As an undergraduate, you see it in several forms, including as a corollary following from Levy’s convergence theorem.
In all applications though, it is generally used as a method of calculating good approximations. It is not uncommon to see it presented as:

Although in many cases that is the right way to think use it, it isn’t the most interesting aspect of the theorem itself. CLT says that the correct scaling of 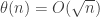
- What happens for less regular distributions? It is now more clear what the right question to ask in this setting might be. What is the appropriate scaling for
- What is special about the normal distribution? The theorem itself shows us that it appears as a universal scaling limit in distribution, but we might reasonably ask what properties such a distribution should have, as perhaps this will offer a clue to a version of CLT or LLNs for less regular distributions.
- We can see that the Weak Law of Large Numbers follows immediately from CLT. In fact we can say more, perhaps a Slightly Less Weak LLN, that

- whenever
. But of course, we also have a Strong Law of Large Numbers, which asserts that the empirical mean converges almost surely. What is the threshhold for almost sure convergence, because there is no a priori reason why it should be
?
To be continued next time.
Related articles
- Weak Law of Large Numbers and Central Limit Theorem via the Levy’s continuity theorem. (maikolsolis.wordpress.com)

Pingback: CLT and Stable Distributions | Eventually Almost Everywhere
Pingback: Gaussian tail bounds and a word of caution about CLT | Eventually Almost Everywhere
Pingback: Azuma-Hoeffding Inequality | Eventually Almost Everywhere