
I wasn’t able to post this at the time because of the embargo on discussing this particular question until the end of IMO 2015.


I’m currently enjoying the slow descent into summer in the delightful surroundings of Tonbridge School where we are holding our final camp to select the UK team for this year’s IMO. The mechanism for this selection is a series of four exams following the format of the IMO itself. We take many of the questions for these tests from the shortlist of questions proposed but not used at the previous year’s competition. In this post, I’m going to talk about one of these questions. Obviously, since lots of other countries do the same thing, there is an embargo on publication or public-facing discussion of these problems until after the next competition, so this won’t appear for a couple of months.
The statement of the problem is the following:
IMO Shortlist 2014, N6: Let 

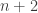
![I=[0,a_1a_2\ldots a_n]](https://s0.wp.com/latex.php?latex=I%3D%5B0%2Ca_1a_2%5Cldots+a_n%5D&bg=ffffff&fg=333333&s=0&c=20201002)
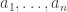
I marked our students’ attempts at this problem and spoke to them about it afterwards. In particular, the official solution we were provided with, and which we photocopied and gave to our students contains some good theory and some magic. On closer inspection, the magic turns out to be unnecessary, and actually distracts a little from the theory. Anyway, this is my guided tour of the problem.
We begin with two items from the rough work that some students submitted. Someone treated the case n=2, which is not quite trivial, but not hard at all, and remarked, sensibly, that n=3 seemed to have become hard. Packaged with this was the implicit observation that for the purpose of the question posed, 
The second idea coming out of rough work was to consider what happens when an interval gets broken into two by a ‘new point’, whatever that means. In particular, what happens to the sum of the squares of the interval lengths modulo p? The way the student had set up this procedure suggested that the calculations would be easy in the case where the point being added was a multiple of 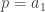
It does, however, suggest an inductive argument, if instead you add the points which are multiples of 
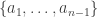

Now we are happy this might work in principle, let’s do it in practice. We are adding all these multiples of 
We are only interested in non-trivial splittings of intervals. We might initially be concerned that an existing interval might be split into more than two sub-intervals by the addition of the multiples of

using that 
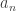

Now we have the challenge of evaluating this sum, or at least showing that it is divisible by p. Given a multiple 
Well, on the left of 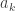

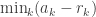
![\sum_{a\text{ a new multiples of }a_n} \left( \min_i(r_i)\right) \left[ \min_j(a_j-r_j) \right].](https://s0.wp.com/latex.php?latex=%5Csum_%7Ba%5Ctext%7B+a+new+multiples+of+%7Da_n%7D+%5Cleft%28+%5Cmin_i%28r_i%29%5Cright%29+%5Cleft%5B+%5Cmin_j%28a_j-r_j%29+%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
Now we return to the question of how to index the new multiples of 
Yes, of course we can. There’s a bijection between the possible sequences of remainders, and the new multiples of
![r_1,\ldots,r_{n-1} \in [1,a_1-1]\times\ldots\times [1,a_{n-1}-1].](https://s0.wp.com/latex.php?latex=r_1%2C%5Cldots%2Cr_%7Bn-1%7D+%5Cin+%5B1%2Ca_1-1%5D%5Ctimes%5Cldots%5Ctimes+%5B1%2Ca_%7Bn-1%7D-1%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
Remember that the fact that they are not allowed to be zero is because we only care now about new points being added.
Even now though, it’s not obvious how to compute this sum, so the natural thing to try is to invert our view of what we are summing over. That is, to consider how many of the index sequences result in particular values of x and y. Given x and y at least one, each remainder ![[x,a_k-y]](https://s0.wp.com/latex.php?latex=%5Bx%2Ca_k-y%5D&bg=ffffff&fg=333333&s=0&c=20201002)

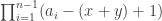
Fortunately this is easily fixed. If the minimum for x is not attained, we know that ![r_k\in[x+1,a_k-y],](https://s0.wp.com/latex.php?latex=r_k%5Cin%5Bx%2B1%2Ca_k-y%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)

This is a polynomial in (x+y), so we’ll call in P(x+y). We’ll come back to this expression. We still need to tidy up our overall sum, in particular by deciding what bounds we want on x and y. Thinking about the intervals of width p, it is clear that the bounds should be 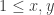


If you’ve got to this stage, I hope you would feel that this seems really promising. You’ve got to show that some sum of polynomial-like things over a reasonably well-behaved index set is divisible by p. If you don’t know general theorems that might confirm that this is true, once you’ve got statements like this, you might well guess then verify their existence.
First though, we need to split up this xy term, since our sum is really now all about x+y, which we’ll call z.

Once we’ve had our thought that we mainly care about polynomials mod p at this stage, we might even save ourselves some work and just observe that 

where Q is some cubic, which we could work out if we really wanted to. But what’s the degree of P? P is made of a sum of 3 polynomials whose degree is clear because they are a product of linear factors. So each of these has degree (n-1), but in fact we can clearly see that the leading term cancels, and also with a tiny bit more care that the second order terms cancel too, so P has degree at most n-3.
[Tangent: students might well ask why it is convention to take the degree of the identically zero polynomial to be 
[Tangent 2: In my initially erroneous evaluation of the number of remainder sequences, without the inclusion-exclusion argument, I indeed ended up with P having degree n-1. I also worked out Q as being quadratic though, so my overall necessary condition was only one off from what was required, showing that two wrongs are not as good as two rights, but marginally better than only one wrong.]
Anyway, we are taking a sum of polynomials of degree at most 
It’s presented as a lemma in the official solution that if you have a polynomial of degree at most p-2, then 
![\{z^k: z\in[1,p-1]\}](https://s0.wp.com/latex.php?latex=%5C%7Bz%5Ek%3A+z%5Cin%5B1%2Cp-1%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The most important point is that this lemma is a) easy-ish and b) a natural thing to try given where you might have got in the question at this stage. From here you’re now basically done.
I don’t think this is an easy question at all, since even with lots of guiding through the steps there are a lot of tangents one might get drawn down, especially investigating exact forms of polynomials which it turns out we only need vague information about. Nonetheless, there are lots of lessons to be learned from the argument, which definitely makes it a good question at this level in my opinion.
