
Turan’s theorem gives bounds on the number of edges required in a graph on a fixed number of vertices n to guarantee it contains a complete graph of size r+1. Equivalently, an upper bound on the number of edges in a 
Rather than give an expression for the bound immediately, it is more natural to consider the Turan graph T(n,r), the maximal graph on n vertices without a copy of 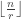
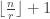
There are a number of ways to enumerate the edges in T(n,r), and some can get quite complicated quite quickly. After a moderate amount of thought, this is my favourite. Let 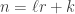
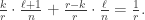
So the probability they are in different classes is 
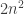
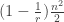
A standard proof
For both proofs, I find it slightly easier to work in the complement graph, where we are aiming for the largest number of edges with an independent set of size (r+1). Suppose we have a graph with the minimal number of vertices such that there’s no independent set of given size. Suppose also that there is an edge joining vertices v and w, such that 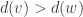


Note that by attempting to make the neighbourhoods of connected vertices equal, we are making the graph look more like a union of complete components. We can do a similar trick if we have three vertices u,v,w such that there are edges between u and v and v and w, but not u and w. Then we know the degrees of u,v,w are the same by the previous argument, and so it can again be checked that making 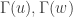
The consequence of this is that we’ve shown that the minimum can only be attained when presence of edges is an equivalence relation (ignoring reflexivity). Thus the minimum is only attained for a union of at most r complete graphs. Jensen (or any root-mean-square type inequality) will then confirm that the true minimum is attained when the sizes of the r components are as equal as possible.
A probabilistic proof
The following probabilistic proof is courtesy of Alon and Spencer. The motivation is that in the (equality) case of a union of complete graphs, however we try to build up a maximal independent set, we always succeed. That is, it doesn’t matter how we choose which vertex (unconnected to those we already have) to add next – we will always get a set of size r. This motivates a probabilistic proof, as an argument in expectation will have equality in the equality case, which is always good.
Anyway, we build up an independent set in a graph by choosing uniformly at random a vertex which is not connected to any we have so far, until this set of vertices is empty. It makes sense to settle the randomness at the start, so give the vertices a uniform random labelling on [n], and at each stage, choose the independent vertex with minimal label.
Thus, a vertex v will be chosen for the independent set if, and only if, it has a smaller label than all of its neighbours, that is, with probability 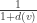
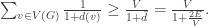
One can chase through the expressions to get the bound we want back.
Olympiad example
The reason I was thinking about Turan’s theorem was a problem which the UK IMO squad was discussing. It comes from an American selection test (slightly rephrased): given 100 points in the plane, what is the largest number of pairs of points with 
The key step is to think about how large a collection of points can have this property pairwise. It is easy to come up with an example of four points which work, and seemingly impossible to come up with an example with five points. To prove this, I found it easiest to place a point at the origin, then explicitly work with coordinates relative the basis 
Anyway, once you are convinced that you can’t have five points with this property pairwise, you are ready to convert into a graph-theoretic statement. Vertices correspond to points, and edges link pairs of points whose distance is in (1,2] as required. We know from the previous paragraph that there is no copy of 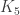
It also tells us under what sort of circumstances the bound is attained, and from this, it’s natural to split the 100 points into four groups of 25, for example by taking four points which satisfy the condition pairwise (eg a diamond around the origin), and placing each group very near one of the points.
Extensions and other directions
The existence of a complete subgraph is reminiscent of Ramsey theory, which in one case is a symmetric version of Turan’s theorem. In Turan, we are adding enough edges to force a complete subgraph, while in the original form of Ramsey theory, we are asking how large the graph needs to be to ensure that for any edge configuration, either the original graph or the complement graph includes a complete subgraph. It makes a lot more sense to phrase this in terms of colours for the purpose of generalisation.
A natural extension is to ask about finding copies of fixed graphs H other than the complete graph. This is the content of the Erdos-Stone theorem. I’d prefer to say almost nothing rather than be vague, but the key difference is that the bound is asymptotic in the number of vertices rather than exact. Furthermore, the asymptotic proportion of vertices depends on the chromatic number of H, which tells you how many classes r are required to embed H in a (large if necessary) r-partite graph. So it is perhaps unsurprising that the limiting proportions end up matching the proportion of edges in the Turan graphs, namely r-1/r as r varies, which leaves the exact scaling open to further investigation in the case where H is bipartite (hence has chromatic number 2).
