
Last week, we held our annual IMO training and selection camp in the lovely surroundings of Trinity College, Cambridge. Four of our students have subsequently spent this week in Kiev, for the ninth edition of the prestigious European Girls’ Mathematical Olympiad.
The UK team, none of whom had attended the competition before, and all of whom remain eligible to return at least once, did extremely well, placing fourth out of the official European countries, and earning three silver medals, and one gold medal, with complete or almost-complete solutions to all six problems between them. More details are available on the competition website.
In this post, I’m going to discuss some of the non-geometry problems. As a special treat, the discussion of Question 6 is led by Joe Benton, which is only fitting, since he wrote it. You can find the first day’s three problems here, and the second day’s problems here. The geometry problems are treated in a separate post.
Problem One

Triple equalities are hard to handle directly, so generally one starts with a single equality, for example the left hand one 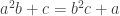

Some quick notes:
- The given equations are inhomogeneous, meaning that not every term has the same degree in terms of {a,b,c}. In complicated equations, normally we want to cancel terms, and we certainly can’t cancel terms with different degrees! So a good first idea is to find a way to make the equations homogeneous, for example using the condition, which is itself inhomogeneous. For example, one could replace
with
, and it’s clear this might lead to some cancellation. In this case, the algebra is more straightforward if one rearranges and factorises first to obtain
, from which the condition gives
.
- Shortly after this, we find
, which means
unless at least one of these terms is equal to zero.
- This case distinction should not be brushed over lightly as a tiny detail. This is the sort of thing that can lose you significant marks, especially if the omitted case turns out to be more involved than the standard case.
- This is a good example of planning your final write-up. The case distinction
is really clumsy. What about b? We have already said that the setup is cyclic in (a,b,c), and it’s annoying to throw this aspect away. It really would be much much to have the overall case distinction at the start of your argument, for example into
and
, because then in the latter case you could assume that
without loss of generality, then see what that implied for the other variables.
- In this setting, one really should check that the claimed solutions satisfy both the condition and the triple-equality. This is a complicated family of simultaneous equations, and even if you’re lucky enough to have settled on an argument that is reversible, it’s much easier to demonstrate that everything is satisfied as desired than actually to argue that the argument is reversible.
Problem Two

Maybe I speak for a number of people when I say I’m a little tired of domino tiling problems, so will leave this one out.
Problem Five

I liked this problem. A lot. It did feel like there were potential time-wasting bear traps one might slip into, and perhaps these comments are relevant:
- This feels like quite a natural problem to ask. In particular, the task specified by (A)+(B) is much more elegant than the RHS of (C). So unless you have immediate insight for the RHS of (C), it makes sense to start with the task, and aim for any bound similar to (C).
- There are a lot of transformations one could make, for example, repeatedly removing n from one of the
s, or re-ordering them conveniently somehow, which shouldn’t affect any solution. You can also attack the RHS of (C) in a number of ways (perhaps with a case split for n odd or even?). As with involved but easy angle chases discussed in the companion post, it’s probably better to hold this in mind than instantly to do all of these, since it will just obscure the argument if you end up not using the result of the simplification!
- One should always try small examples. Here, it’s worth trying examples large enough to get a sense of what’s happening, because I think the crucial observation is that (unless you were very very unlucky) there are lots of suitable sequences
. (*)
- Certainly the case where the
s themselves form a complete n-residue system is ‘easiest’ and certainly straightforward. One might say that the case where the
might have to take the largest values in some sense), but is also straightforward. There’s certainly the option of trying to rigorise this, but I don’t know whether this can be made to work.
In fact (*) is the biggest clue. As a probability theorist, one might attempt to show that a ‘typical’ choice of 
Despite the allure of the probabilistic method, some people like their maths risk-averse and deterministic. The combinatorial paraphrase is that if lots of examples work, consider studying all plausible examples simultaneously. In this setting, we might note that it is ridiculous to consider any values of 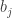

Now, consider all assignments of 

We obtain

So there exists a particular sequence B, for which

We discussed at the start of the post how one shouldn’t instantly panic or agonise over the form of the RHS of (C). This is now a good moment to address this (though hopefully neither panic nor agonise). We have shown

and we want to replace this final term by 

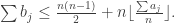
In the case n even, we make a similar argument, based on both the sum of B and 
Notes
- this still hasn’t addressed the question of the best possible sequence B, beyond the remarks made in the introduction.
- other methods may describe a construction of a suitable sequence B. This method has merely proved the existence of such a sequence.
Problem Six

This problem was found very hard, with only six solutions (indeed, only six students scored >1 out of 7). I can personally vouch to spending at least two hours thinking about Joe’s closely-related original statement in the summer before making progress towards a solution. Anyone reading about this problem on the internet would do well to bear in mind that the oft-expressed sentiment that the difficulty of a problem is a function of the length of the shortest known solution is very much fallacious.
The key to this problem is to identify the main content, which is any condition under which the blue labelling cannot be a 3-colouring. The exact details of the circumference labels and the yellow labels may turn out, like many Scandinavian breakfasts, to be a carefully-crafted collection of red herrings.

We are not relevant to the problem.
Joe writes: The first thing you realise when reading the statement is that there’s an awful lot of information – probably so much that it’s obscuring what’s actually going on. Much of the art in setting a problem is taking a nice idea and hiding it in a statement that is still natural but gives as little as possible away. Correspondingly, much of the art of solving such a problem is reversing this process and extracting or abstracting the key information and structure from the problem to (hopefully!) reveal the original idea. In this case, the problem statement seems to be quite strong – it turns out to be hard to construct any examples with consecutive integer labellings – which suggests that some of the specificity in the question is one of these red herrings. Perhaps we could aim to prove a wider class of labellings are impossible, and see that this then implies that the specific labelling in the question can’t occur?
A first natural step is to rephrase the question slightly, so that we instead assume no blue label is divisible by 3 and then have to show that we can’t have yellow labels 0, …, N. This feels more natural as i) it removes the very restrictive assumption that the yellow labels are consecutive (instead turning it into a conclusion); and ii) turns the condition on the blue labellings into a condition about the value of neighbouring marked points modulo 3 – namely that no marked points joined by an edge have the same value modulo 3. Now what we have looks like a graph where the vertices are coloured one of three colours according to their value modulo 3. Indeed, this was the perspective I originally had when coming up with the problem.
From this perspective we have three types of edges: 0 to 1, 0 to 2, and 1 to 2. The conditions on the labels at the boundary can be seen as giving us some restriction on what types of edge we can see there. Now we start to see the outlines of a global counting argument where we try and relate the numbers of 0-1, 0-2 and 1-2 edges we could have. If the yellow labels really are going to be 0, …, N then we know that we must have 
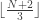

Now comes the key idea, which is where the problem originally came from. Often, if we 2-colour a graph (or some other object), counting arguments based on parity follow naturally. So what happens if given a 3-colouring we merge two colours and treat them as one, to create a 2-colouring artificially? It was this idea of taking a 3-colouring, viewing it as three 2-colourings and applying a parity argument three ways that was my inspiration for the problem. Once I’d decided I liked that idea, the challenge was then finding a set up that would hide it a not-completely-artificial way. All the red-herrings we have just removed came about naturally as an attempt to add some extra structure to preserve but obscure this intended proof method.
If we decided to eg colour all marked points that are 0 modulo 3 white, and colour the rest black, then the condition that there are no 1-1 or 2-2 edges implies that any black-black edge must be a 1-2 edge. Then we have a 2-coloured graph where every interior marked point has even degree. After a little experimentation we might conjecture and prove that the parity of the number of black-white edges is dictated by the parity of the number of white (or black) points on the boundary. This gives

where 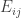
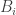
From a problem setter’s point of view, the fact that the conditions that there were no 1-1 or 2-2 edges and every vertex had even degree played out nicely in the proof is not a coincidence, nor the fact that 0,…,N happens to fall into the class of labellings ruled out by this proof; rather, that was why the setup in the question with chords and blue labels was chosen. And from a problem solver’s point of view, when those details fall nicely into place it’s a hint that you are on the right path.
