Remarks from Cramer’s Theorem
So in the previous post we discussed Cramer’s theorem on large deviations for means of i.i.d. random variables. It’s worth stepping back and thinking more abstractly about what we showed. Each  has some law, which we think of as a measure on
has some law, which we think of as a measure on  , though this could equally well be some other space, depending on where the random variables are supported. The law of large numbers asserts that as
, though this could equally well be some other space, depending on where the random variables are supported. The law of large numbers asserts that as  , these measures are increasingly concentrated at a single point in , which in this case is
, these measures are increasingly concentrated at a single point in , which in this case is 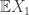 . Cramer’s theorem then asserts that the measure of certain sets not containing this point of concentration decays exponentially in n, and quantifies the exponent, a so-called rate function, via a Legendre transform of the log moment generating function of the underlying distribution.
. Cramer’s theorem then asserts that the measure of certain sets not containing this point of concentration decays exponentially in n, and quantifies the exponent, a so-called rate function, via a Legendre transform of the log moment generating function of the underlying distribution.
One key point is that we considered only certain sets  , though we could equally well have considered
, though we could equally well have considered ![(-\infty,a],\,a<\mathbb{E}X_1](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2Ca%5D%2C%5C%2Ca%3C%5Cmathbb%7BE%7DX_1&bg=ffffff&fg=333333&s=0&c=20201002) . What would happen if we wanted to consider an interval, say
. What would happen if we wanted to consider an interval, say ![[a,b],\,\mathbb{E}X_1<a<b](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D%2C%5C%2C%5Cmathbb%7BE%7DX_1%3Ca%3Cb&bg=ffffff&fg=333333&s=0&c=20201002) ? Well,
? Well, ![\mu_n([a,b])=\mu_n([a,\infty))-\mu_n((b,\infty))](https://s0.wp.com/latex.php?latex=%5Cmu_n%28%5Ba%2Cb%5D%29%3D%5Cmu_n%28%5Ba%2C%5Cinfty%29%29-%5Cmu_n%28%28b%2C%5Cinfty%29%29&bg=ffffff&fg=333333&s=0&c=20201002) , and we might as well assume that
, and we might as well assume that 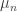 is sufficiently continuous, at least in the limit, that we can replace the open interval bound with a closed one. Then Cramer’s theorem asserts, written in a more informal style, that
is sufficiently continuous, at least in the limit, that we can replace the open interval bound with a closed one. Then Cramer’s theorem asserts, written in a more informal style, that  and similarly for
and similarly for  . So provided
. So provided  , we have
, we have
![\mu_n([a,b])\sim e^{-nI(a)}-e^{-nI(b)}\sim e^{-nI(a)}.](https://s0.wp.com/latex.php?latex=%5Cmu_n%28%5Ba%2Cb%5D%29%5Csim+e%5E%7B-nI%28a%29%7D-e%5E%7B-nI%28b%29%7D%5Csim+e%5E%7B-nI%28a%29%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
To in order to accord with our intuition, we would like I(x) to be increasing for 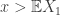 , and decreasing for
, and decreasing for 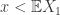 . Also, we want
. Also, we want  , to account for the fact that
, to account for the fact that  . For each consider a sequence of coin tosses. The probability that the observed proportion of heads is in
. For each consider a sequence of coin tosses. The probability that the observed proportion of heads is in ![[\frac12,1]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac12%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) should be roughly 1/2 for all n.
should be roughly 1/2 for all n.
Note that in the previous displayed equation for ![\mu_n([a,b])](https://s0.wp.com/latex.php?latex=%5Cmu_n%28%5Ba%2Cb%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) the right hand side has no dependence on b. Informally, this means that any event which is at least as unlikely as the event of a deviation to a, will in the limit happen in the most likely of the unlikely ways, which will in this case be a deviation to a, because of relative domination of exponential functions. So if, rather than just half-lines and intervals, we wanted to consider more general sets, we might conjecture a result of the form:
the right hand side has no dependence on b. Informally, this means that any event which is at least as unlikely as the event of a deviation to a, will in the limit happen in the most likely of the unlikely ways, which will in this case be a deviation to a, because of relative domination of exponential functions. So if, rather than just half-lines and intervals, we wanted to consider more general sets, we might conjecture a result of the form:
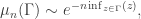
with the approximation defined formally as in the statement of Cramer’s theorem. What can go wrong?
Large Deviations Principles
Well, if the set  a single point, and the underlying distribution is continuous, then we would expect
a single point, and the underlying distribution is continuous, then we would expect  for all n. Similarly, we would expect
for all n. Similarly, we would expect  , but there is no a priori reason why I(z) should be continuous at . (In fact, this is false.), so taking
, but there is no a priori reason why I(z) should be continuous at . (In fact, this is false.), so taking  again gives a contradiction.
again gives a contradiction.
So we need something a bit more precise. Noting that the problem here is that measure (in this case, measure of likeliness on an exponential scale) can leak into open sets through the boundary in the limit, and also the rate function requires some sort of neighbourhood to make sense for continuous RVs, so boundaries of closed sets may give an overestimate. This is reminiscent of weak convergence, and motivated by this, the appropriate general definition for a Large Deviation Principle is:
A sequence of measure  on some space E satisfies an LDP with rate function I and speed n if
on some space E satisfies an LDP with rate function I and speed n if 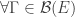 :
:
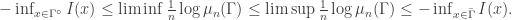
Although this might look very technical, you might as well think of it as nothing more than the previous conjecture for general sets, with the two problems that we mentioned now taken care of.
So, we need to define a rate function. ![I: E\rightarrow[0,\infty]](https://s0.wp.com/latex.php?latex=I%3A+E%5Crightarrow%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) is a rate function, if it not identically infinite. We also demand that it is lower semi-continuous, and has closed level sets
is a rate function, if it not identically infinite. We also demand that it is lower semi-continuous, and has closed level sets  . These definitions are in fact equivalent. I will say what lower semi-continuity is in a moment. Some authors also demand that the level sets be compact. Others call this a good rate function, or similar. The advantage of this is that infima on closed sets are attained.
. These definitions are in fact equivalent. I will say what lower semi-continuity is in a moment. Some authors also demand that the level sets be compact. Others call this a good rate function, or similar. The advantage of this is that infima on closed sets are attained.
It is possible to specify a different rate. The rate gives the speed of convergence.  can be replaced with any function converging to 0, including continuously.
can be replaced with any function converging to 0, including continuously.
Lower Semi-Continuity
A function f is lower semi-continuous if
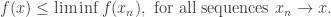

One way of thinking about this definition is to say that the function cannot jump upwards as it reaches a boundary, it can only jump downwards (or not jump at all). The article on Wikipedia for semi-continuity has this picture explaining how a lower semi-continuous function must behave at discontinuities. Note that the value of f at the discontinuity could be the blue dot, or anything less than the blue dot. It is reasonable clear why this definition is equivalent to having closed level sets.
So the question to ask is: why should rate functions be lower semi-continuous? Rather than proceeding directly, we argue by uniqueness. Given a function on with discontinuities, we can turn it into a cadlag function, or a caglad function by fiddling with the values taken at points of discontinuity. We can do a similar thing to turn any function into a lower semi-continuous function. Given f, we define

The notes I borrowed this idea from described this as the maximal lower semi-continuous regularisation, which I think is quite a good explanation despite the long words.
Anyway, the claim is that if  satisfies a LDP then so does $I_*(x)$. This needs to be checked, but it explains why we demand that the rate function be lower semi-continuous. We really want the rate function to be unique, and this is a good way to prevent an obvious cause of non-uniqueness. It needs to be checked that it is actually unique once we have this assumption, but that is relatively straightforward.
satisfies a LDP then so does $I_*(x)$. This needs to be checked, but it explains why we demand that the rate function be lower semi-continuous. We really want the rate function to be unique, and this is a good way to prevent an obvious cause of non-uniqueness. It needs to be checked that it is actually unique once we have this assumption, but that is relatively straightforward.
So, to check that the lower semi-continuous regularisation of I satisfies the LDP if I does, we observe that the upper bound is trivial, since 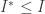 everywhere. Then, for every open set G, note that for
everywhere. Then, for every open set G, note that for  , so we might as well consider sequences within G, and so
, so we might as well consider sequences within G, and so  . So, since
. So, since 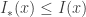 , it follows that
, it follows that

and thus we get the upper bound for the LDP.
References
The motivation for this particular post was my own, but the set of notes here, as cited in the previous post were very useful. Also the Wikipedia page on semi-continuity, and Frank den Hollander’s book ‘Large Deviations’.


Pingback: Large Deviations 4 – Sanov’s Theorem | Eventually Almost Everywhere
Pingback: Poisson Tails | Eventually Almost Everywhere
Pingback: Large Deviations 5 – Stochastic Processes and Mogulskii’s Theorem | Eventually Almost Everywhere
In the last but one paragraph, you say “We really want the rate function not to be unique, and this is a good way to prevent an obvious cause of non-uniqueness.”
I think you mean “We want the rate function to be unique”, or is there something I am missing?