
Although we could have defined things for a more general topological space, most of our thoughts about Cramer’s theorem, and the Gartner-Ellis theorem which generalises it, are based on means of real-valued random variables. For Cramer’s theorem, we genuinely are interested only in means of i.i.d. random variables. In Gartner-Ellis, one might say that we are able to relax the condition on independence and perhaps identical distribution too, in a controlled way. But this is somewhat underselling the theorem: using G-E, we can deal with a much broader category of measures than just means of collections of variables. The key is that convergence of the log moment generating function is exactly enough to give a LDP with some rate, and we have a general method for finding the rate function.
So, Gartner-Ellis provides a fairly substantial generalisation to Cramer’s theorem, but is still similar in flavour. But what about if we look for additional properties of a collection of i.i.d. random variables 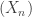
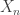

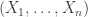
As n grows towards infinity, we expect this empirical distribution to approximate the real underlying distribution fairly well. This isn’t necessarily quite as easy as it sounds. By the strong law of large numbers applied to indicator functions 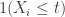
So such empirical distributions might well admit an LDP. Note that in the case of Bernoulli random variables, the empirical distribution is in fact exactly equivalent to the empirical mean, so Cramer’s theorem applies. But, in fact we have a general LDP for empirical distributions. I claim that the main point of interest here is the nature of the rate function – I will discuss why the existence of an LDP is not too surprising at the end.
The rate function is going to be interesting whatever form it ends up taking. After all, it is effectively going to some sort of metric on measures, as it records how far a possible empirical measure is from the true distribution. Apart from total variation distance, we don’t currently have many standard examples for metrics on a space of measures. Anyway, the rate function is the main content of Sanov’s theorem. This has various forms, depending on how fiddly you are prepared for the proof to be.
Define 

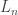
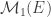
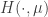

The function H is the relative entropy, defined by:

whenever 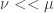

Note that an alternative form is:
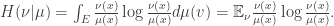
Perhaps it is more clear why this expectation is something we would want to minimise.
In particular, if we want to know the most likely asymptotic empirical distribution inducing a large deviation empirical mean (as in Cramer), then we find the distribution with suitable mean, and smallest entropy relative to the true underlying distribution.
A remark on the proof. If the underlying set of values is finite, then a proof of this result is essentially combinatorial. The empirical distribution is some multinomial distribution, and we can obtain exact forms for everything and then proceed with asymptotic approximations.
I said earlier that I would comment on why the LDP is not too surprising even in general, once we know Gartner-Ellis. Instead of letting 
If the support K of the 
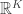
![[0,1]^K](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5EK&bg=ffffff&fg=333333&s=0&c=20201002)
Related articles
- Large Deviations 1 – Motivation and Cramer’s Theorem (eventuallyalmosteverywhere.wordpress.com)
- Large Deviations 2 – LDPs, Rate Functions and Lower Semi-Continuity (eventuallyalmosteverywhere.wordpress.com)
- Large Deviations 3 – Gartner-Ellis Theorem: Where do the all terms come from? (eventuallyalmosteverywhere.wordpress.com)
- The law of small numbers (r-bloggers.com)
- Sleeper theorems (johndcook.com)
- Competition ranking and empirical distributions (brainder.org)

Pingback: Large Deviations 5 – Stochastic Processes and Mogulskii’s Theorem | Eventually Almost Everywhere