
The meat of this course covers rate of convergence of the distribution of Markov chains. In particular, we want to be thinking about lots of distributions simultaneously, so we really to be comfortable working with the space of measures on a (for now) finite state space. This is not really too bad actually, since we can embed it in a finite-dimensional real vector space.

Since most operations we might want to apply to distributions are linear, it doesn’t make much sense to inherit the usual Euclidean metric. In the end, the metric we use is the same as the 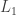


Perhaps the best justification for total variation distance is from a gambling viewpoint. Suppose your opinion for the distribution of some outcome is 


Formally, we define:

Note that if this maximum is achieved at A, it is also achieved at 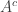
![||\mu-\nu||_{TV}=\max_{A\subset\Omega} \left[\mu(A)-\nu(A)\right].](https://s0.wp.com/latex.php?latex=%7C%7C%5Cmu-%5Cnu%7C%7C_%7BTV%7D%3D%5Cmax_%7BA%5Csubset%5COmega%7D+%5Cleft%5B%5Cmu%28A%29-%5Cnu%28A%29%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
If we decompose 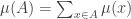
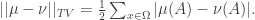
There are plenty of other interesting interpretations of total variation distance, but I don’t want to get bogged down right now. We are interested in the rate of convergence of distributions of Markov chains. Given some initial distribution 
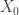

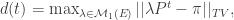
the worst-case scenario, where we choose the initial distribution that mixes the slowest, at least judging at time t. Now, here’s where the space of measures starts to come in useful. For now, we relax the requirement that measures must be probability distributions. In fact, we allow them to be negative as well. Then 
But although I haven’t yet been explicit about this, it is easy to see that 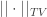
Then, we know from linear optimisation theory, that convex functions on an affine space achieve their maxima at boundary points. And the boundary points for this definition of 

where 


The triangle inequality gives 

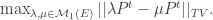
The function we are maximising is a convex function on 


I’m not suggesting this method is qualitatively different to that proposed by the authors of the book. However, I think this is very much the right way to be thinking about these matters of maximising norms over a space of measures. Partly this is good because it gives an easy ‘sanity check’ for any idea. But also because it gives some idea of whether it will or won’t be possible to extend the ideas to the case where the state space is infinite, which will be of interest much later.
Related articles
- Mixing Times 1- Reversing Markov Chains
- Mixing Times 2 – Metropolis Chains
- Split-Bregman for total variation: parameter choice (mirror2image.wordpress.com)
- Hormander-Minlin (nucaltiado.wordpress.com)

Pingback: Mixing Times 4 – Avoiding Periodicity | Eventually Almost Everywhere