
This is something interesting which came up on the first problem sheet for the Part A Statistics course. The second question introduced the Weibull distribution, defined in terms of parameters 

As mentioned in the statement of the question, this distribution is “typically used in industrial reliability studies in situations where failure of a system comprising many similar components occurs when the weakest component fails”. Why could that be? Expressed more theoretically, the lifetimes of various components might reasonably be assumed to behave like i.i.d. random variables in many contexts. Then the failure time of the system is given by the minimum of the constituent random variables.
So this begs the question: what does the distribution of minimum of a collection of i.i.d. random variables look like? First, we need to think why there should be an answer at all. I mean, it would not be unreasonable to assume that this would depend rather strongly on the underlying distribution. But of course, we might say the same thing about sums of i.i.d. random variables, but there is the Central Limit Theorem. Phrased in a way that is deliberately vague, this says that subject to some fairly mild conditions on the underlying distribution (finite variance in this case), the sum of n i.i.d. RVs look like a normal distribution for large n. Here we know what ‘looks like’ means, since we have a notion of a family of normal distributions. Formally, though, we might say that ‘looks like’ means that the image of the distribution under some linear transformation, where the coefficients are possibly functions of n, converges to the distribution N(0,1) as n grows.
The technical term for this is to say that the underlying RV we are considering, which in this case would be 
Anyway, with that perspective, it is perhaps more reasonable to imagine that the minimum of a collection of i.i.d. RVs might have some limit distribution. Because we typically feel more comfortable thinking about right-tails rather than left-tails of probability distributions, this problem is more often considered for the maximum of i.i.d. RVs. The Fisher-Tippett-Gnedenko theorem, proved in various forms in the first half of the 20th century, asserts that again under mild regularity assumptions, the maximum of such a collection does lie in the domain of attraction of one of a small set of distributions. The Weibull distribution as defined above is one of these. (Note that if we are considering domains of attraction, then scaling x by a constant is of no consequence, so we can drop the parameterisation by 
This is considered the first main theorem of Extreme Value Theory, which addresses precisely this sort of problem. It is not hard to consider why this area is of interest. To decide how much liquidity they require, an insurance company needs to know the likely size of the maximum claim during the policy. Similarly, the designer of a sea-wall doesn’t care about the average wave-height – what matters is how strong the once-in-a-century storm which threatens the town might be. A good answer might also explain how to resolve the apparent contradiction that most human characteristics are distributed roughly normally across the population. Normal distributions are unbounded, yet physiological constraints enable us to state with certainty that there will never be twelve foot tall men (or women). In some sense, EVT is a cousin of Large Deviation theory, the difference being that unlikely events in a large family of i.i.d. RVs are considered on a local scale rather than globally. Note that large deviations for Cramer’s theorem in the case where the underlying distribution has a heavy tail are driven by a single very deviant value, rather than by lots of slightly deviant data, so in this case the theories are comparable, though generally analysed from different perspectives.
In fact, we have to consider the reversed Weibull distribution for a maximum, which is supported on ![(-\infty,0]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C0%5D&bg=ffffff&fg=333333&s=0&c=20201002)
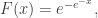
and the Frechet distribution

Note that 
The differences between them lie in the tail behaviour. The reversed Weibull distribution has an actual upper bound, the Gumbel an exponential, fast-decaying tail, and the Frechet a polynomial ‘fat’ tail. It is not completely obvious that these properties are inherited from the original distribution. After all, to get from the original distribution to extreme value distribution, we are taking the maximum, then rescaling and translating in a potentially quite complicated way. However, it is perhaps reasonable to see that the property of the underlying distribution having an upper bound is preserved through this process. Obviously, the bound itself is not preserved – after all, we are free to apply arbitrary linear transformations to the distributions!
In any case, it does turn out to be the case that the U[0,1] distribution has maximum converging to a reversed Weibull; the exponential tails of the Exp(1) and N(0,1) distributions lead to a Gumbel limit; and the fat-tailed Pareto distribution gives the Frechet limit. The calculations are reasonably straightforward, especially once the correct rescaling is known. See this article from Duke for an excellent overview and the details for these examples I have just cited. These notes discuss further properties of these limiting distributions, including the unsurprising fact that their form is preserved under taking the maximum of i.i.d. copies. This is analogous to the fact that the family of normal distributions is preserved under taking arbitrary finite sums.
From a statistical point of view, devising a good statistical test for what class of extreme value distribution a particular set of data obeys is of great interest. Why? Well mainly because of the applications, some of which were suggested above. But also because of the general statistical principle that it is unwise to extrapolate beyond the range of the available data. But that is precisely what we need to do if we are considering extreme values. After all, the designer of that sea-wall can’t necessarily rely on the largest storm in the future being roughly the same as the biggest storm in the past. So because the EVT theorem gives a clear description of the distribution, to find the limiting properties, which is where the truly large extremes might occur, it suffices to find a good test for the form of the limit distribution – that is, which of the three possibilities is relevant, and what the parameter should be. This seems to be fairly hard in general. I didn’t understand much of it, but this paper provided an interesting review.
Anyway, that was something interesting I didn’t know about (for the record, I also now know how to construct a sensible Q-Q plot for the Weibull distribution!), though I am assured that EVT was a core element of the mainstream undergraduate mathematics syllabus forty years ago.
Related articles
- The law of small numbers (r-bloggers.com)
- What is the expected value function of the Gumbel distribution? (ask.metafilter.com)
- The Law of Small Numbers (architects.dzone.com)
