
In this post, I want to talk about another recently-introduced model that’s generating a lot of interest in probability theory, Sznitman’s model of random interlacements. We also want to see, at least heuristically, how this relates to more familiar models.
We fix our attention on a lattice, which we assume to be 
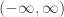
For reasons we will mention shortly, we are interested in the complement of the union of the trajectories. We call this the vacant set. We will find an intensity which we can freely scale by some parameter 
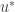


Let us first recall why it is not interesting to consider this process for d=1 or 2. On 

Therefore it is only for d=>3 that we start seeing interesting effects. It is worth mentioning at this point some of the problems that motivated considering this model. First is the disconnection time of a discrete cylinder by a simple walk. For example, Sznitman considers the random walk on 
More generally, we might be interested in random walks up to some time an order of magnitude smaller than the cover time. Recall the cover time is the time to hit each point of the set. For example, for the random walk on the d-dimensional torus 


Anyway, the main question to ask is: what should the intensity measure be?
We patch it together locally. Start with the observation that transience of the random walk means almost surely a trajectory spends only finitely many steps in a fixed finite set K. So we index all the trajectories which hit K by the first time they hit K. Given that a trajectory hits K, it is clear what the conditional distribution of this hitting point should be. Recall that SRW on Z^d is reversible, so we consider the SRW backwards from this hitting then. Then the probability that the hitting point is x (on the boundary of K) is proportional to the probability that a SRW started from x goes to infinity without hitting K again. So once we’ve settled on the distribution of the hitting point x, it is clear how to construct all the trajectories through K. We pick x on the boundary of K according to this distribution, and take the union of an SRW starting from x conditioned not to hit K again, and an SRW starting from x with no conditioning. These correspond to the trajectory before and after the hitting time, respectively.
In fact, it turns out that this is enough. Suppose we demand that the probability that the hitting point is x is equal to the probability that a SRW started from x goes to infinity without hitting K again (rather than merely proportional to). Sznitman proves that there is a unique measure on the set of trajectories that restricts to this measure for every choice of K. Furthermore, the Poisson Point Process with the globally-defined intensity, unsurprisingly restricts to a PPP with the intensity specific to K.
We have not so far said anything about trajectories which miss this set K. Note that under any sensible intensity with the translation-invariance property, the intensity measure of the trajectories which hit K must be positive, since we can cover 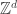
Recall how we defined the probability that the hitting point of K was some point x on the boundary. The sum of these probability is called the capacity of K. It follows that this is the parameter of the Poisson random variable. Ie, the probability that no trajectory passes through K is:
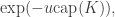
recalling that u is the free parameter in the intensity. This is the most convenient framework through which to start analysing the probability that there is an infinite connected set which is hit by no trajectory.
We conclude by summarising Sznitman’s Remark 1.2, explaining why it is preferable to work with the space of trajectories rather than the space of paths. Note that if we are working with paths, and we want translation invariance, then this restricts to translation invariance of the distribution of starting points as well, so it is in fact a stronger condition. Note then that either the intensity of starting at 0 is zero, in which case there are no trajectories at all, or it is positive, in which case the set of starting points looks like Bernoulli site percolation.
However, the results about capacity would still hold if there were a measure that restricted satisfactorily. And so the capacity of K would still be the measure of paths hitting K, which would be at least the probability that the path was started in K. But by translation invariance, this grows linearly with |K|. But capacity grows at most as fast as the size of the set of boundary points of K, which will be an order of magnitude smaller when K is, for example, a large ball.
REFERENCES
This was mainly based on
Sznitman – Vacant Set of Random Interlacements and Percolation (0704.2560)
Also
Sznitman – Random Walks on Discrete Cylinders and Random Interlacements (0805.4516)
Teixeira – On the Uniqueness of the Infinite Cluster of the Vacant Set of Random Interlacements (0805.4106)
and some useful slides by the same author (teixeira.pdf)
Related articles
- Bell inequalities in translational-invariant systems (qigcbpf.wordpress.com)
- The Riemann hypothesis in various settings (nucaltiado.wordpress.com)
- Principles of Random Walk. (ZZ) (Graduate Texts in Mathematics) book downloads (icgevis.wordpress.com)
- Pick a Random Byte (gauravsachin007.wordpress.com)
- Covariance between electorates (electionlab.wordpress.com)
