
In several previous posts, I have talked about scaling limits of various random graphs. Typically in this situation we are interested in convergence of large-scale properties of the graph as the size grows to some limit. These properties will normally be metric in flavour: diameter, component size and so on. To describe convergence of these properties, we divide by the relevant scale, which will often be some simple function of n. If we are looking to find an actual limit object, this is even more important. This is rather similar to describing properties of centred random walks. There, if we run the walk for time n, we have to rescale by 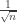
One of the best examples is Aldous’ Continuum Random Tree which we can view as the limit of a Galton-Watson tree conditioned to have total size n, as n tends to infinity. Because of the exploration process or contour process interpretation, where these functions behave rather like a random walk, the correct scaling in this context is again
Local limits aim to give convergence towards a (discrete) infinite graph. The sort of properties we are looking for are now local properties such as degrees and correlations of degrees. These don’t require knowledge of the whole graph, only of some finite subset. First consider the possibility that the sequence of deterministic graphs has the property:

where 
In the previous example, suppose the first finite graph 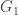
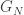
This is all the motivation we require for a genuine definition. We will define our limit in terms of neighbourhoods, so we need some mechanism to choose the central vertex of such a neighbourhood. The answer is to consider rooted graphs, that it a graph with an identified vertex. We can introduce randomness by specifying a random graph, or by giving a distribution for the choice of root. If G is finite, the canonical choice is to choose the root uniformly from the set of vertices. This isn’t an option for an infinite graph, so we define the system as (G, p) where G is a (for now deterministic) graph, and p is a probability measure on V(G).
We say that the limit of finite 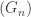
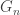
![(G_n)[U_n]\stackrel{d}{\rightarrow} (G,p)](https://s0.wp.com/latex.php?latex=%28G_n%29%5BU_n%5D%5Cstackrel%7Bd%7D%7B%5Crightarrow%7D+%28G%2Cp%29&bg=ffffff&fg=333333&s=0&c=20201002)
Informally, we might say that if we zoom in on an average vertex in
1) When we talk about approximating the component size in a sparse Erdos-Renyi random graph by a 
2) To emphasise why rooting the finite graphs makes a difference, consider the full binary tree with n levels (so 
Things get a bit more complicated if we root randomly. Remember that the motivation for random rooting is that we want to know the local structure around a vertex chosen at random in many applications. If we definitely know what vertex we are going to choose, we know the local structure a priori. Note that in an n-level binary tree, 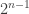
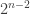

This gives us a precise description of the limiting local neighbourhood structure. The resulting limiting object is called the canopy tree. One picture of this can be found on page 6 of this paper. A verbal description is also possible. Consider the set of non-negative integers, arranged in the usual manner on the real line, with edges between adjacent elements. The distribution of the root will be supported on this set of vertices, corresponding to the distance from the leaves in the pre-limit graph. So we have mass 1/2 at 0, 1/4 at 1, 1/8 at 2 and so on. We then connect each vertex k to a full k-level binary tree. The resulting canopy tree looks like an infinite-level full binary tree, viewed from the leaves, which is of course a reasonable heuristic, since that is there the mass is concentrated if we randomly root.
3) In particular, the limit is not the infinite-level binary tree. The canopy tree and the infinite-level binary tree have qualitatively different properties. Simple random walk on the canopy tree is recurrent for example. In fact, a result of Benjamini and Schramm, as explained in this review by Curien, says that any local limit of uniformly bounded degree, uniformly rooted, planar graphs is recurrent for SRW. The infinite-level binary tree can be expressed as a local limit if we choose the root distribution sensibly, using large random 3-regular graphs. The previous result does not apply because the random 3-regular graphs are not almost surely planar.
REFERENCES:
– Much of this article is a paraphrase of a section of Itai Benjamini’s mini-course at the DSSA in Haifa March 2013.
– As well as the review paper linked above, these notes by David Aldous were very useful.
Related articles
- Graphs and Trees (propermath.wordpress.com)
- Colouring a Graph (golem.ph.utexas.edu)
- Minimum Spanning Tree Algorithms (alikhuram.wordpress.com)
- New Ramanujan Graphs! (gilkalai.wordpress.com)
- Vertex Cover In Bipartite Graph (supanthap.wordpress.com)
- Longest path in an undirected tree with only one traversal (cs.stackexchange.com)
- Last Week on the arXiv (15th-19th April, 2013) (flusteredmonkey.wordpress.com)

Nice notes! Especially since there isn’t much about graph limits on blogs or Wikipedia (yet ;)). I think it’d be nice to include the keyword “Benjamini Schramm convergence” (another name for the local limit you described) somewhere in the post, if only for the sake of googlability.