
I’m currently at the training camp in Cambridge for this year’s UK IMO squad. This afternoon I gave a talk to some of the less experienced students about combinatorics. My aim was to cover as many useful tricks for calculating the sizes of combinatorial sets as I could in an hour and a half. We started by discussing binomial coefficients, which pleasingly turned out to be revision for the majority. But my next goal was to demonstrate that we are much more interested in the fact that we can calculate these if we want than in the actual expression for their values.
Put another way, my argument was that the interpretation of 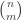

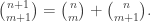
This is not a hard result to prove by manipulating factorials, but it is a very easy result to prove in the path-counting setting, for example.
So it turned out that the goal of my session, as further supported by some unsubtly motivated problems from the collection, was to convince the students to use bijections as much as possible. That is, if you have to count something awkward, show that counting the awkward thing is equivalent to counting something more manageable, then count that instead. For many simpler questions, this equivalence is often drawn implicitly using words (“each of the n objects can be in any subset of the collection of bags so we multiply…” etc), but it is always worth having in mind the formal bijective approach. Apart from anything else, asking the question “is this bijection so obvious I don’t need to prove it” is often a good starting-point for assessing whether the argument is in fact correct!
Anyway, I really wanted to show my favouriite bijection argument, but there wasn’t time, and I didn’t want to spoil other lecturers’ thunder by defining a graph and a tree and so forth. The exploration process encoding of trees is a strong contender, but today I want to define quickly the Prufer coding for trees, and use it to prove a famous result I’ve been using a lot recently, Cayley’s formula for the number of spanning trees on the complete graph with n vertices, 
We are going to count rooted trees instead. Since we can choose any vertex to be the root, there are 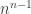
![[n]^{n-1}](https://s0.wp.com/latex.php?latex=%5Bn%5D%5E%7Bn-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Let’s record informally how we would recover a tree from the Prufer code. First, observe that the label of any vertex which is not a leaf must appear in the code. Why? Well, the root label appears right at the end, if not earlier, and every vertex must be deleted. But a vertex cannot be deleted until it has degree one, so the neighbours further from the root (or ancestors) of the vertex must be removed first, and so by construction the label appears. So know what the root is, and what the leaves are straight away.
In fact we can say slightly more than this. The number of times the root label appears is the degree of the root, while the number of times any other label appears is the degree of the corresponding vertex minus one. Call this sequence the Prufer degrees.
So we construct the tree backwards from the leaves towards the root. We add edges one at a time, with the k-th edge joining the vertex with the k-th label to some other vertex. For k=1, this other vertex is the leaf with maximum label. In general, let 
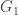
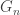



Proving that this is indeed the inverse is a bit fiddly, more because of notation than any actual mathematics. You probably want to show injectivity by an extremal argument, taking the closest vertex to the root that is different in two trees with the same Prufer code. I hope it isn’t a complete cop out to swerve around presenting this in full technical detail, as I feel I’ve achieved by main goal of explaining why bijection arguments can reduce a counting problem that was genuinely challenging to an exercise in choosing sensible notation for proving a fairly natural bijection.
Related articles
- Of Triangular Numbers and Bijections (provosta.wordpress.com)
- The Canonical Bijective Homomorphism (caltech.typepad.com)
- Uniform Spanning Trees (eventuallyalmosteverywhere.wordpress.com)
- Linear time labeling algorithm for a tree? (cs.stackexchange.com)

Pingback: Generating Functions for the IMO | Eventually Almost Everywhere
Pingback: Generating uniform trees | Eventually Almost Everywhere