As a final instalment in this sequence of posts on Large Deviations, I’m going to try and explain how one might be able to apply some of the theory to a problem about random graphs. I should explain in advance that much of what follows will be a heuristic argument only. In a way, I’m more interested in explaining what the technical challenges are than trying to solve them. Not least because at the moment I don’t know exactly how to solve most of them. At the very end I will present a rate function, and reference properly the authors who have proved this. Their methods are related but not identical to what I will present.
Problem
Recall the two standard definitions of random graphs. As in many previous posts, we are interested in the sparse case where the average degree of a vertex is o(1). Anyway, we start with n vertices, and in one description we add an edge between any pair of vertices independently and with fixed probability 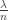 . In the second model, we choose uniformly at random from the set of graphs with n vertices and
. In the second model, we choose uniformly at random from the set of graphs with n vertices and  edges. Note that if we take the first model and condition on the number of edges, we get the second model, since the probability of a given configuration appearing in G(n,p) is a function only of the number of edges present. Furthermore, the number of edges in G(n,p) is binomial with parameters
edges. Note that if we take the first model and condition on the number of edges, we get the second model, since the probability of a given configuration appearing in G(n,p) is a function only of the number of edges present. Furthermore, the number of edges in G(n,p) is binomial with parameters  and p. For all purposes here it will make no difference to approximate the former by
and p. For all purposes here it will make no difference to approximate the former by  .
.
Of particular interest in the study of sparse random graphs is the phase transition in the size of the largest component observed as  passes 1. Below 1, the largest component has size on a scale of log n, and with high probability all components are trees. Above 1, there is a unique giant component containing
passes 1. Below 1, the largest component has size on a scale of log n, and with high probability all components are trees. Above 1, there is a unique giant component containing 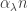 vertices, and all other components are small. For
vertices, and all other components are small. For  , where I don’t want to discuss what ‘approximately’ means right now, we have a critical window, for which there are infinitely many components with sizes on a scale of
, where I don’t want to discuss what ‘approximately’ means right now, we have a critical window, for which there are infinitely many components with sizes on a scale of 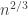 .
.
A key observation is that this holds irrespective of which model we are using. In particular, this is consistent. By the central limit theorem, we have that:
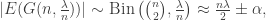
where  is the error due to CLT-scale fluctuations. In particular, these fluctuations are on a scale smaller than n, so in the limit have no effect on which value of in the edge-specified model is appropriate.
is the error due to CLT-scale fluctuations. In particular, these fluctuations are on a scale smaller than n, so in the limit have no effect on which value of in the edge-specified model is appropriate.
However, it is still a random model, so we can condition on any event which happens with positive probability, so we might ask: what does a supercritical random graph look like if we condition it to have no giant component? Assume for now that we are considering 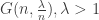 .
.
This deviation from standard behaviour might be achieved in at least two ways. Firstly, we might just have insufficient edges. If we have a large deviation towards too few edges, then this would correspond to a subcritical  , so would have no giant components. However, it is also possible that the lack of a giant component is due to ‘clustering’. We might in fact have the correct number of edges, but they might have arranged themselves into a configuration that keeps the number of components small. For example, we might have a complete graph on
, so would have no giant components. However, it is also possible that the lack of a giant component is due to ‘clustering’. We might in fact have the correct number of edges, but they might have arranged themselves into a configuration that keeps the number of components small. For example, we might have a complete graph on 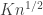 vertices plus a whole load of isolated vertices. This has the correct number of edges, but certainly no giant component (that is an O(n) component).
vertices plus a whole load of isolated vertices. This has the correct number of edges, but certainly no giant component (that is an O(n) component).
We might suspect that having too few edges would be the primary cause of having no giant component, but it would be interesting if clustering played a role. In a previous post, I talked about more realistic models of complex networks, for which clustering beyond the levels of Erdos-Renyi is one of the properties we seek. There I described a few models which might produce some of these properties. Obviously another model is to take Erdos-Renyi and condition it to have lots of clustering but that isn’t hugely helpful as it is not obvious what the resulting graphs will in general look like. It would certainly be interesting if conditioning on having no giant component were enough to get lots of clustering.
To do this, we need to find a rate function for the size of the giant component in a supercritical random graph. Then we will assume that evaluating this near 0 gives the LD probability of having ‘no giant component’. We will then compare this to the straightforward rate function for the number of edges; in particular, evaluated at criticality, so the probability that we have a subcritical number of edges in our supercritical random graph. If they are the same, then this says that the surfeit of edges dominates clustering effects. If the former is smaller, then clustering may play a non-trivial role. If the former is larger, then we will probably have made a mistake, as we expect on a LD scale that having too few edges will almost surely lead to a subcritical component.
Methods
The starting point is the exploration process for components of the random graph. Recall we start at some vertex v and explore the component containing v depth-first, tracking the number of vertices which have been seen but not yet explored. We can extend this to all components by defining:

where X(t) is the number of children of the t’th vertex. For a single component, S(t) is precisely the number of seen but unexplored vertices. It is more complicated in general. Note that when we exhaust the first component S(t)=-1, and then when we exhaust the second component S(t)=-2 and so on. So in fact
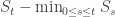
is the number of seen but unexplored vertices, with  equal to (-1) times the number of components already explored up to time t.
equal to (-1) times the number of components already explored up to time t.
Once we know the structure of the first t vertices, we expect the distribution of X(t) – 1 to be
![\text{Bin}\Big(n-t-[S_t-\min_{0\leq s\leq t}S_s],\tfrac{\lambda}{n}\Big)-1.](https://s0.wp.com/latex.php?latex=%5Ctext%7BBin%7D%5CBig%28n-t-%5BS_t-%5Cmin_%7B0%5Cleq+s%5Cleq+t%7DS_s%5D%2C%5Ctfrac%7B%5Clambda%7D%7Bn%7D%5CBig%29-1.&bg=ffffff&fg=333333&s=0&c=20201002)
We aren’t interested in all the edges of the random graph, only in some tree skeleton of each component. So we don’t need to consider the possibility of edges connecting our current location to anywhere we’ve previously visited (as such an edge would have been consider then – it’s a depth-first exploration), hence the -t. But we also don’t want to consider edges connecting our current location to anywhere we’ve seen, since that would be a surplus edge creating a cycle, hence the -S_s. It is binomial because by independence even after all this conditioning, the probability that there’s an edge from my current location to any other vertex apart from those discounted is equal to and independent.
For Mogulskii’s theorem in the previous post, we had an LDP for the rescaled paths of a random walk with independent stationary increments. In this situation we have a random walk where the increments do not have this property. They are not stationary because the pre-limit distribution depends on time. They are also not independent, because the distribution depends on behaviour up to time t, but only through the value of the walk at the present time.
Nonetheless, at least by following through the heuristic of having an instantaneous exponential cost for a LD event, then products of sums becoming integrals within the exponent, we would expect to have a similar result for this case. We can find the rate function  latex \text{Po}(\lambda)-1$ and thus get a rate function for paths of the exploration process
latex \text{Po}(\lambda)-1$ and thus get a rate function for paths of the exploration process

where 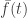 is the height of f above its previous minimum.
is the height of f above its previous minimum.
Technicalities and Challenges
1) First we need to prove that it is actually possible to extend Mogulskii to this more general setting. Even though we are varying the distribution continuously, so we have some sort of ‘local almost convexity’, the proof is going to be fairly fiddly.
2) Having to consider excursions above the local minima is a massive hassle. We would ideally like to replace 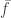 with f. This doesn’t seem unreasonable. After all, if we pick a giant component within o(n) steps, then everything considered before the giant component won’t show up in the O(n) rescaling, so we will have a series of macroscopic excursions above 0 with widths giving the actual sizes of the giant components. The problem is that even though with high probability we will pick a giant component after O(1) components, then probability that we do not do this decays only exponentially fast, so will show up as a term in the LD analysis. We would hope that this would not be important – after all later we are going to take an infimum, and since the order we choose the vertices to explore is random and in particular independent of the actual structure, it ought not to make a huge difference to any result.
with f. This doesn’t seem unreasonable. After all, if we pick a giant component within o(n) steps, then everything considered before the giant component won’t show up in the O(n) rescaling, so we will have a series of macroscopic excursions above 0 with widths giving the actual sizes of the giant components. The problem is that even though with high probability we will pick a giant component after O(1) components, then probability that we do not do this decays only exponentially fast, so will show up as a term in the LD analysis. We would hope that this would not be important – after all later we are going to take an infimum, and since the order we choose the vertices to explore is random and in particular independent of the actual structure, it ought not to make a huge difference to any result.
3) A key lemma in the proof of Mogulskii in Dembo and Zeitouni was the result that it doesn’t matter from an LDP point of view whether we consider the linear (continuous) interpolation or the step-wise interpolation to get a process that actually lives in ![L_\infty([0,1])](https://s0.wp.com/latex.php?latex=L_%5Cinfty%28%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) . In this generalised case, we will also need to check that approximating the Binomial distribution by its Poisson limit is valid on an exponential scale. Note that because errors in the approximation for small values of t affect the parameter of the distribution at larger times, this will be more complicated to check than for the IID case.
. In this generalised case, we will also need to check that approximating the Binomial distribution by its Poisson limit is valid on an exponential scale. Note that because errors in the approximation for small values of t affect the parameter of the distribution at larger times, this will be more complicated to check than for the IID case.
4) Once we have a rate function, if we actually want to know about the structure of the ‘typical’ graph displaying some LD property, we will need to find the infimum of the integrated rate function with some constraints. This is likely to be quite nasty unless we can directly use Euler-Lagrange or some other variational tool.
Answer
Papers by O’Connell and Puhalskii have found the rate function. Among other interesting things, we learn that:

while the rate function for the number of edges:
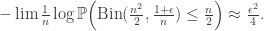
So in fact it looks as if there might be a significant contribution from clustering after all.

![[a_1,b_1]\supset [a_2,b_2]\supset [a_3,b_3]\supset\ldots](https://s0.wp.com/latex.php?latex=%5Ba_1%2Cb_1%5D%5Csupset+%5Ba_2%2Cb_2%5D%5Csupset+%5Ba_3%2Cb_3%5D%5Csupset%5Cldots&bg=ffffff&fg=333333&s=0&c=20201002)
![\cap_{n\geq 1}[a_n,b_n]\neq \varnothing](https://s0.wp.com/latex.php?latex=%5Ccap_%7Bn%5Cgeq+1%7D%5Ba_n%2Cb_n%5D%5Cneq+%5Cvarnothing&bg=ffffff&fg=333333&s=0&c=20201002)


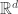

![(0,1]=\cup_{n\geq 1}[\frac{1}{n},1].](https://s0.wp.com/latex.php?latex=%280%2C1%5D%3D%5Ccup_%7Bn%5Cgeq+1%7D%5B%5Cfrac%7B1%7D%7Bn%7D%2C1%5D.&bg=ffffff&fg=333333&s=0&c=20201002)


![[a_1,b_1]](https://s0.wp.com/latex.php?latex=%5Ba_1%2Cb_1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
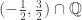
![\cap_{n\geq 1}[\pi-\frac{1}{n},\pi+\frac{1}{n}]\cap\mathbb{Q}](https://s0.wp.com/latex.php?latex=%5Ccap_%7Bn%5Cgeq+1%7D%5B%5Cpi-%5Cfrac%7B1%7D%7Bn%7D%2C%5Cpi%2B%5Cfrac%7B1%7D%7Bn%7D%5D%5Ccap%5Cmathbb%7BQ%7D&bg=ffffff&fg=333333&s=0&c=20201002)
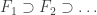


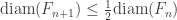

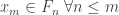

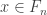

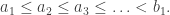
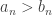
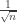 to see the fluctuations on a finite positive scale.
to see the fluctuations on a finite positive scale.
 denotes an induced subgraph. Then it is relatively clear what the limit should be, as it is well-defined to take a union. This won’t work directly for a limit of random graphs, because the above relation in probability doesn’t even really make sense if we have a different probability space for each finite graph. This is a general clue that we should be looking to use convergence in distribution rather than anything stronger.
denotes an induced subgraph. Then it is relatively clear what the limit should be, as it is well-defined to take a union. This won’t work directly for a limit of random graphs, because the above relation in probability doesn’t even really make sense if we have a different probability space for each finite graph. This is a general clue that we should be looking to use convergence in distribution rather than anything stronger.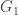 consists of a single vertex v. If the limit graph (remember this is just the union, since that is well-defined) has bounded degrees, then there is some N such that
consists of a single vertex v. If the limit graph (remember this is just the union, since that is well-defined) has bounded degrees, then there is some N such that 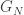 contains all the information we might want about the limiting neighbourhood of vertex v. For some larger N,
contains all the information we might want about the limiting neighbourhood of vertex v. For some larger N, 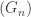 is the random rooted infinite graph (G, p) if the neighbourhoods of
is the random rooted infinite graph (G, p) if the neighbourhoods of 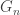 around a randomly chosen vertex converge in distribution to the neighbourhoods of G around p. Formally, say
around a randomly chosen vertex converge in distribution to the neighbourhoods of G around p. Formally, say ![(G_n)[U_n]\stackrel{d}{\rightarrow} (G,p)](https://s0.wp.com/latex.php?latex=%28G_n%29%5BU_n%5D%5Cstackrel%7Bd%7D%7B%5Crightarrow%7D+%28G%2Cp%29&bg=ffffff&fg=333333&s=0&c=20201002) if for all r>0, for any finite rooted graph (H,w), the probability that (H,w) is isomorphic to the ball of radius r in
if for all r>0, for any finite rooted graph (H,w), the probability that (H,w) is isomorphic to the ball of radius r in  branching process, this is exactly the limit sense we mean. The approximation fails if we fix n and take the neighbourhood size very large (eg radius n), but for finite neighbourhoods, or any radius growing more slowly than n, the approximation is good.
branching process, this is exactly the limit sense we mean. The approximation fails if we fix n and take the neighbourhood size very large (eg radius n), but for finite neighbourhoods, or any radius growing more slowly than n, the approximation is good. vertices). If we fix the root, then the limit is the infinite-level binary tree, though this isn’t especially surprising or interesting.
vertices). If we fix the root, then the limit is the infinite-level binary tree, though this isn’t especially surprising or interesting.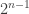 vertices are leaves, not counting the base of the tree, and
vertices are leaves, not counting the base of the tree, and 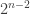 are distance 1 from a leaf, and
are distance 1 from a leaf, and  are distance 2 from a leaf and so on.
are distance 2 from a leaf and so on. ,
,![\pi(\theta)\propto [I(\theta)]^{1/2}](https://s0.wp.com/latex.php?latex=%5Cpi%28%5Ctheta%29%5Cpropto+%5BI%28%5Ctheta%29%5D%5E%7B1%2F2%7D&bg=ffffff&fg=333333&s=0&c=20201002) where I is the Fisher information, defined as
where I is the Fisher information, defined as![I(\theta)=-\mathbb{E}_\theta\Big[\frac{\partial^2 l(X_1,\theta)}{\partial \theta^2}\Big],](https://s0.wp.com/latex.php?latex=I%28%5Ctheta%29%3D-%5Cmathbb%7BE%7D_%5Ctheta%5CBig%5B%5Cfrac%7B%5Cpartial%5E2+l%28X_1%2C%5Ctheta%29%7D%7B%5Cpartial+%5Ctheta%5E2%7D%5CBig%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 , and l is the log-likelihood. Proving that this has the property that it is invariant under reparameterisation requires demonstrating that the Jeffreys prior corresponding to
, and l is the log-likelihood. Proving that this has the property that it is invariant under reparameterisation requires demonstrating that the Jeffreys prior corresponding to  is the same as applying a change of measure to the Jeffreys prior for
is the same as applying a change of measure to the Jeffreys prior for 