
A long time ago, I wrote quite a few a things about uniform trees. That is, a uniform choice from the 
In another historic post, I talked about the Aldous-Broder algorithm. Here’s a quick summary. We run a random walk on the complete graph 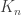
It’s worth noting that this algorithm works to construct a uniform spanning tree on any connected base graph.
This post is about a few alternative constructions and interpretations of the uniform random tree. The first construction uses a Galton-Watson process. We take a Galton-Watson process where the offspring distribution is Poisson(1), and condition that the total population size is n. The resulting random tree has a root but no labels, however if we assign labels in [n] uniformly at random, the resulting rooted tree has the uniform distribution among rooted trees on [n].
Proof
This is all about moving from ordered trees to non-ordered trees. That is, when setting up a Galton-Watson tree, we distinguish between the following two trees, drawn extremely roughly in Paint:

That is, it matters which of the first-generation vertices have three children. Anyway, for such a (rooted) ordered tree T with n vertices, the probability that the Galton-Watson process ends up equal to T is

where 

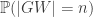
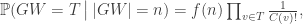
where f(n) is a function of n alone (ie depends on T only through its size n).
But given an unordered rooted tree t, labelled by [n], there are 


Heuristic for Poisson offspring distribution
In this proof, the fact that 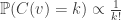

We can provide independent motivation though, from the Aldous-Broder construction. Both the conditioned Galton-Watson construction and the A-B algorithm supply the tree with a root, so we’ll keep that, and look at the distribution of the degree of the root as constructed by A-B. Let 

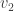
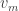

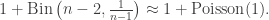
Now, in the Galton-Watson process, conditioning the tree to have fixed, large size changes the offspring distribution of the root. Conveniently though, in a limiting sense it’s the same change as conditioning the tree to have size at least n. Since these events are monotone in n, it’s possible to take a limit of the conditioning events, and interpret the result as the Galton-Watson tree conditioned to survive. It’s a beautiful result that this interpretation can be formalised as a local limit. The limiting spine decomposition consists of an infinite spine, where the offspring distribution is a size-biased version of the original offspring distribution (and so in particular, always has at least one child) and where non-spine vertices have the original distribution.
In particular, the number of the offspring of the root is size-biased, and it is well-known and not hard to check that size-biasing Poisson(c) gives 1+Poisson(c) ! So in fact we have, in an appropriate limiting sense in both objects, a match between the degree distribution of the root in the uniform tree, and in the conditioned Galton-Watson tree.
This isn’t supposed to justify why a conditioned Galton-Watson tree is relevant a priori (especially the unconditional independence of degrees), but it does explain why Poisson offspring distributions are relevant.
Construction via G(N,p) and the random cluster model
The main reason uniform trees were important to my thesis was their appearance in the Erdos-Renyi random graph G(N,p). The probability that vertices {1, …, n} form a tree component in G(N,p) with some particular structure is

Here, the first two terms give the probability that the graph structure on {1, …, n} is correct, and the the final term gives the probability of the (independent) event that these vertices are not connected to anything else in the graph. In particular, this has no dependence on the tree structure chosen on [n] (for example, whether it should be a path or a star – both examples of trees). So the conditional distribution is uniform among all trees.
If we work in some limiting regime, where 

One slightly unsatisfying aspect to this construction is that we have to embed the tree of size [n] within a much larger graph on [N] to see uniform trees. We can’t choose a scaling p=p(n) such that G(n,p) itself concentrates on trees. To guarantee connectivity with high probability, we need to take 
At this PIMS summer school in Vancouver, one of the courses is focusing on lattice spin models, including the random cluster model, which we now briefly define. We start with some underlying graph G. From a physical motivation, we might take G to be 
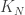

where the edge-weight 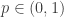



As in the Erdos-Renyi graph, consider fixing the underlying graph G, and taking 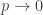

In other words, the limit of the distribution is the uniform spanning tree of G, and so this (like Aldous-Broder) is a substantial generalisation, which constructs the uniform random tree in the special case where 
