
I am aiming to write a short post about each lecture in my ongoing course on Random Graphs. Details and logistics for the course can be found here.
As we enter the final stages of the semester, I want to discuss some extensions to the standard Erdos-Renyi random graph which has been the focus of most of the course so far. In doing so, we can revisit material that we have already covered, and discover how easily one can extend this directly to more exotic settings.
The focus of this lecture was the model of inhomogeneous random graphs (IRGs) introduced by Soderberg [Sod02] and first studied rigorously by Bollobas, Janson and Riordan [BJR07]. Soderberg and this blog post address the case where vertices have a type drawn from a finite set. BJR address the setting with more general typespaces, in particular a continuum of types. This generalisation is essential if one wants to use IRGs to model effects more sophisticated than those of the classical Erdos-Renyi model G(n,c/n), but most of the methodology is present in the finite-type setting, and avoids the operator theory language which is perhaps intimidating for a first-time reader.
Inhomogeneous random graphs
Throughout, 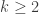


Given 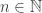
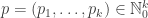



- the vertex set is [n],
- types are assigned uniformly at random to the vertices such that exactly
vertices have type i.
- Conditional on these types, each edge
(for
) is present, independently, with probability
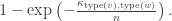
Notes on the definition:
- Alternatively, we could assign the types so that vertices
have type 1,
have type 2, etc etc. This makes no difference except in terms of the notation we have to use if we want to use exchangeability arguments later.
- An alternative model considers some distribution
on [k], and assigns the types of the vertices of [n] in an IID fashion according to
- Note that the edge probability given is
. The exponential form has a more natural interpretation if we ever need to turn the IRGs into a process. Additionally, it avoids the requirement to treat small values of n (for which, a priori,
might be greater than 1) separately.

In the above example, one can see that, roughly speaking, red vertices are more likely to be connected to each other than blue vertices. However, for both colours, they are more likely to be connected to a given vertex of the same colour than a vertex of the opposite colour. This might, for example, correspond to the kernel 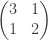
The definition given above corresponds to a sparse setting, where the typical vertex degrees are 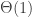
From an applications point of view, it’s not hard to imagine that an IRG of some flavour might be a good model for many phenomena observed in reality, especially when a mean-field assumption is somewhat appropriate. The friendships of boys and girls in primary school seems a particularly resonant example, though doubtless there are many others.
One particular application is to recover the types of the vertices from the topology of the graph. That is, if you see the above picture without the colours, can you work out which vertices are red, and which are blue? (Assuming you know the kernel.) This is clearly impossible to do with anything like certainty in the sparse setting – how does one decide about isolated vertices, for example? The probabilities that a red vertex is isolated and that a blue vertex is isolated differ by a constant factor in the 
Poisson multitype branching processes
As in the case of the classical random graph G(n,c/n), we learn a lot about the IRG by studying its local structure. Let’s assume from now on that we are given a sequence of IRGs 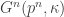
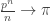
![\pi=(\pi_1,\ldots,\pi_k)\in[0,1]^k](https://s0.wp.com/latex.php?latex=%5Cpi%3D%28%5Cpi_1%2C%5Cldots%2C%5Cpi_k%29%5Cin%5B0%2C1%5D%5Ek&bg=ffffff&fg=333333&s=0&c=20201002)
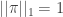
Now, let 
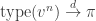
Then, conditional on 
- when
, the number of type j neighbours of
.
- the number of type i neighbours of
.
Note that ![p_j\left[1-\exp\left(-\frac{\kappa_{i,j}}{n}\right)\right]\approx \frac{p_j\cdot \kappa_{i,j}}{n} \approx \kappa_{i,j}\pi_j](https://s0.wp.com/latex.php?latex=p_j%5Cleft%5B1-%5Cexp%5Cleft%28-%5Cfrac%7B%5Ckappa_%7Bi%2Cj%7D%7D%7Bn%7D%5Cright%29%5Cright%5D%5Capprox+%5Cfrac%7Bp_j%5Ccdot+%5Ckappa_%7Bi%2Cj%7D%7D%7Bn%7D+%5Capprox+%5Ckappa_%7Bi%2Cj%7D%5Cpi_j&bg=ffffff&fg=333333&s=0&c=20201002)
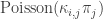
This motivates the following definition of a branching process tree, whose vertices have k types. Given 
- Declare the root to have type i with probability
;
- Then, inductively, a vertex with type i has some number of children of type j, distributed as
, and other parent vertices.
(It would be safer to define this formally as a subset of the Ulam-Harris tree 
(It may be helpful to think of the branching mechanism as a Poisson random measure on the type space. This definition then immediately generalises to the case where type-space is continuous.)
Claim:
Note: in Lecture 6, we set up the notation of local weak convergence in considerable detail. It’s important to stress that this was established for graphs, not for graphs with k types. That said, the extension of the definition is immediate if one extends the definition of graph isomorphism to include a correct matching of types. However, rather more care is required if one is to extend the definition to the case of a continuum of types, for which one must handle the situation where two graphs with types are close if they are isomorphic as graphs, and all the types of pairs of vertices matched by the isomorphism are close. See [vdHRGCN2, Section 1.2] or our recent pre-print [CRY18] for considerably more detail.
Survival probabilities, Perron-Frobenius theorem
Recall that for G(n,c/n), we have a phase transition around the critical value c=1, with major qualitative changes in the properties of the graph, in particular the emergence of a unique giant component occupying a positive proportion of the vertices for c>1. The goal for the rest of the lecture is to characterise whether a sequence of sparse IRGs exhibits sub/supercritical behaviour, in terms of 
First, we recall a classical result about positive matrices, which may be unfamiliar to anyone approaching this random graphs course without a full mathematical background in linear algebra.
Theorem (Perron – 1907): Let 
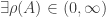

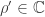

Proof: One can use Brouwer’s fixed point theorem, among many other methods.
Note: This is relevant to the existence of equilibrium distributions for (finite) Markov chains. (Though there are easier arguments to demonstrate this existence.) A very old post on this blog gives a rather obscure proof using linear programming in this special case of stochastic matrices.
Frobenius (1912 etc): gives further results in the case of non-negative matrices. For the purposes of an initial study of IRGs, one can assume that all relevant results hold so long as the kernel is irreducible. This can be characterised by the existence of some m for which 
The punchline is that, as in the homogeneous setting of G(n,c/n), the presence of a giant component in the random graph, and the survival of the corresponding branching process, are essentially the same problem. We won’t explore the connection between these in detail during this course (not least because this is a single lecture), but this motivates focusing on the following theorem. Firstly, since it will be relevant repeatedly, this post borrows the following notation from [Yeo18]: let 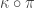
![[\kappa_{i,j}\pi_j]_{i,j\in[k]}](https://s0.wp.com/latex.php?latex=%5B%5Ckappa_%7Bi%2Cj%7D%5Cpi_j%5D_%7Bi%2Cj%5Cin%5Bk%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Theorem:

Notes: The content of this theorem is first proved in Section 5 of [BJR07] in, as discussed earlier, the setting of more general type-spaces.
In other words, the principal eigenvalue of 
Proof: We start with the subcritical and critical settings 
It’s useful to study the survival probability conditional on the type of the root, with a view to finding some sort of recursion, just as in the original monotype setting. (Throughout this argument, we suppress the notational dependence on 
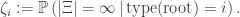
Then the vector 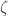
![\zeta_i= 1- \exp\left(-[(\kappa\circ\pi)\zeta]_i\right),](https://s0.wp.com/latex.php?latex=%5Czeta_i%3D+1-+%5Cexp%5Cleft%28-%5B%28%5Ckappa%5Ccirc%5Cpi%29%5Czeta%5D_i%5Cright%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
since the tree survives if, and only if, the root has at least one child (of any type) for which the subtree rooted there survives.
Linearising the RHS, we obtain

and this inequality is strict in at least one coordinate if 

(As demanded in the main exercise for this lecture, one can show directly that in the subcritical setting when 
![\mathbb{E}\left[|\Xi|\right]<\infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%7C%5CXi%7C%5Cright%5D%3C%5Cinfty&bg=ffffff&fg=333333&s=0&c=20201002)
Supercritical case 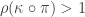
For this, we will show that the equation (*) has a strictly positive solution. It’s not a priori clear that the survival probabilities should correspond to the maximal solution. I will omit this here because, modulo a change of notation, it’s covered very clearly in Lemma 5.6 of [BJR07], and is intuitively motivated by the corresponding result in the monotype case.
Motivated by (*), introduce the function 
![f(x) = \left( 1 - \exp\left(-[(\kappa\circ\pi)x]_i \right)\right)_{i\in[k]},](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Cleft%28+1+-+%5Cexp%5Cleft%28-%5B%28%5Ckappa%5Ccirc%5Cpi%29x%5D_i+%5Cright%29%5Cright%29_%7Bi%5Cin%5Bk%5D%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
so that (*) becomes 

Now, let 
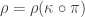

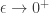
![[f(\epsilon \nu)]_i = 1-\exp(-\rho \epsilon \nu_i) = \rho\epsilon \nu_i + O(\epsilon^2),](https://s0.wp.com/latex.php?latex=%5Bf%28%5Cepsilon+%5Cnu%29%5D_i+%3D+1-%5Cexp%28-%5Crho+%5Cepsilon+%5Cnu_i%29+%3D+%5Crho%5Cepsilon+%5Cnu_i+%2B+O%28%5Cepsilon%5E2%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and so for 

So, writing 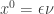


![x^n\uparrow x\in[0,1]^k](https://s0.wp.com/latex.php?latex=x%5En%5Cuparrow+x%5Cin%5B0%2C1%5D%5Ek&bg=ffffff&fg=333333&s=0&c=20201002)
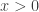

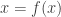
References
[Abbe] – Community detection and stochastic block models
[BJR07] – Bollobas, Janson, Riordan – 2007 – The phase transition in inhomogeneous random graphs
[CRY18] – Crane, Rath, Yeo – 2018+ – Age evolution in the mean field forest fire model via multitype branching process
[Sod02] – Soderberg – 2002 – General formalism for inhomogeneous random graphs
[vdHRGCN2] – van der Hofstad – Random graphs and complex networks, Volume II
[Yeo18] – Yeo – 2018+ – Frozen percolation with k types
