
A number of previous posts on this blog have discussed Markov’s inequality, and the control one can obtain on a distribution by applying this to functions of the distribution, or functions of random variables with this distribution. In particular, studying the square of the deviation from the mean 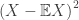
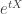
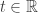
![\mathbb{E}[e^{tX}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Be%5E%7BtX%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
The case of a random walk, that is the sum of IID increments, is particularly well-studied. In [Ho63], Hoeffding studies a generalisation where the increments are merely independent, and outlines a further generalisation to discrete-time martingales, which is developed by Azuma in [Az67], leading to the famous Azuma-Hoeffding inequality. A key feature of this theorem is that we require bounded increments, which leads to tight choices of 
In addition, [Ho63] addresses the alternative model where the increments of a random walk are chosen uniformly without replacement from a particular set. The potted summary is that the sum of random increments chosen without replacement has the same mean, but is more concentrated that the corresponding sum of random increments chosen with replacement. This means that any of the concentration results proved in the earlier sections of [Ho63] for the latter situation apply equally to the setting without replacement.
Various versions of this result are referred to as Hoeffding’s inequality by the literature, and the main goal of this short article is to list some results which are definitely true about this setting!
(Note, in some contexts, ‘Hoeffding’s inequality’ will mean the concentration bound for either the with-replacement or the without-replacement setting. In this blog post, we are discussing inequalities comparing these two settings.)
Starting point – second moments in ‘vanilla’ Hoeffding
We won’t use this notation heavily, but for now let’s assume that we are studying a (multi)set of values 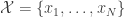
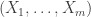
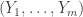
Some preliminary remarks:
- The
s are still chosen uniformly which can be interpreted as
- Any permutation of the multiset
is equally likely to appear as
;
- If determining the sequence one element at a time, then in a conditional sense, the choice of the ‘next’ element is uniform among those elements which have not yet been chosen.
- Any permutation of the multiset
- In particular, the sequence
- It is clear that
, so concentration around this common mean is the next question of interest.
- Intuitively, when
, we wouldn’t expect there to be much difference between sampling with or without replacement.
- When sampling without replacement, the cases m and N-m are symmetric with respect to the sum of
and, in particular, have the same concentration.
As a brief warmup, we establish that
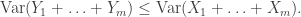
Note that the RHS is 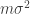
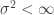
![\mathbb{E}\left[ (Y_1+\ldots+Y_m)^2\right] \le \mathbb{E}\left[ (X_1+\ldots+X_m)^2\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%28Y_1%2B%5Cldots%2BY_m%29%5E2%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B+%28X_1%2B%5Cldots%2BX_m%29%5E2%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
But this really has nothing to do with probability now, since these quantities are just symmetric polynomials in
![n\mathbb{E}[Y_1^2] + n(n-1)\mathbb{E}[Y_1Y_2] \le n\mathbb{E}[X_1^2] + n(n-1)\mathbb{E}[X_1X_2].](https://s0.wp.com/latex.php?latex=n%5Cmathbb%7BE%7D%5BY_1%5E2%5D+%2B+n%28n-1%29%5Cmathbb%7BE%7D%5BY_1Y_2%5D+%5Cle+n%5Cmathbb%7BE%7D%5BX_1%5E2%5D+%2B+n%28n-1%29%5Cmathbb%7BE%7D%5BX_1X_2%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
Since 

which really is an algebra exercise, and can be demonstrated by the rearrangement inequality, or Chebyshev’s inequality (the other one – ie sequence-valued FKG not the probabilistic second-moment bound one), or by clever pre-multiplying and cancelling to reduce to Cauchy-Schwarz.
In [BPS18], which we will turn to in much greater detail shortly, the authors assert in the first sentence that Hoeffding treats also the setting of weighted sums, that is a comparison of
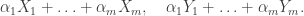
A casual reader of [Ho63] may struggle initially to identify that this has indeed happened. At the level of second-moment comparison though, the argument given above carries over essentially immediately. We have
![\mathbb{E}\left[ (\alpha_1Y_1+\ldots+\alpha_n Y_n)^2\right] = \left(\alpha_1^2+\ldots+\alpha_n^2\right) \mathbb{E}[Y_1^2] + \left(\sum_{i\ne j} \alpha_i\alpha_j \right)\mathbb{E}\left[Y_1Y_2\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%28%5Calpha_1Y_1%2B%5Cldots%2B%5Calpha_n+Y_n%29%5E2%5Cright%5D+%3D+%5Cleft%28%5Calpha_1%5E2%2B%5Cldots%2B%5Calpha_n%5E2%5Cright%29+%5Cmathbb%7BE%7D%5BY_1%5E2%5D+%2B+%5Cleft%28%5Csum_%7Bi%5Cne+j%7D+%5Calpha_i%5Calpha_j+%5Cright%29%5Cmathbb%7BE%7D%5Cleft%5BY_1Y_2%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and of course the corresponding decomposition for 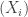
Convex ordering
For many applications, variance is sufficient as a measure of concentration, but one can say more. As a prelude, note that one characterisation of stochastic ordering (which I have sometimes referred to as stochastic domination on this blog) is that
![X\le_{st}Y \;\iff\;\mathbb{E}[f(X)] \le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bst%7DY+%5C%3B%5Ciff%5C%3B%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
whenever f is a non-decreasing function. Unsurprisingly, it’s the 
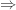
[To inform what follows, I used a number of references, in particular [BM05].]
A natural extension to handle concentration is (stochastic) convex ordering, which is defined as
![X\le_{cx} Y\;\iff \; \mathbb{E}[f(X)]\le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bcx%7D+Y%5C%3B%5Ciff+%5C%3B+%5Cmathbb%7BE%7D%5Bf%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
whenever f is a convex function. Note immediately that this definition can only ever apply to random variables for which 
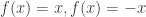
This sort of comparison has plenty of application in economics and actuarial fields, where there is a notion of risk-aversion, and convexity is the usual criterion to define risk (in the sense that the danger of a significant loss is viewed as more significant than a corresponding possibility of a significant gain). Also note that in this context, X is preferred to Y by a risk-averse observer.
In fact, it can be shown [Oh69] that a sufficient condition for 
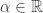
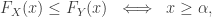
where 

We will return later to the question of adapting this measure to handle distributions with different expectations, but for now, we will return to the setting of sampling with and without replacement and show that
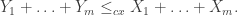
This is the result shown by Hoeffding, but by a more complicated method. We use the observations of [BPS18] which are stated in a more complicated setting which we may return to later. For notational convenience, let’s assume the elements of 
We set up a natural coupling of 
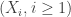
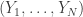

Note then that given the sequence 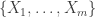
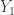


![\mathbb{E}\left[X_1+\ldots+X_m\,\big|\, \{Y_1,\ldots,Y_m\}\right] = Y_1+\ldots+Y_m,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BX_1%2B%5Cldots%2BX_m%5C%2C%5Cbig%7C%5C%2C+%5C%7BY_1%2C%5Cldots%2CY_m%5C%7D%5Cright%5D+%3D+Y_1%2B%5Cldots%2BY_m%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and so we may coarsen the conditioning to obtain
![\mathbb{E}\left[X_1+\ldots+X_m\,\big|\, Y_1+\ldots+Y_m\right] = Y_1+\ldots+Y_m.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BX_1%2B%5Cldots%2BX_m%5C%2C%5Cbig%7C%5C%2C+Y_1%2B%5Cldots%2BY_m%5Cright%5D+%3D+Y_1%2B%5Cldots%2BY_m.&bg=ffffff&fg=333333&s=0&c=20201002)
This so-called martingale coupling is very useful for proving convex ordering. You can think of ![\mathbb{E}[X|Y]=Y](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%7CY%5D%3DY&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[f(X)] = \mathbb{E}\left[ \mathbb{E}[f(X)|Y] \right] \ge \mathbb{E}\left[f\left(\mathbb{E}[X|Y] \right)\right] = \mathbb{E}\left[ f(Y)\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cmathbb%7BE%7D%5Bf%28X%29%7CY%5D+%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5Bf%5Cleft%28%5Cmathbb%7BE%7D%5BX%7CY%5D+%5Cright%29%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y%29%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
So we have shown that sampling without replacement is greater than sampling with replacement in the convex ordering, if we consider sums of the samples.
If we want to handle weighted sums, and tried to reproduce the previous argument directly, it would fail, since
![\mathbb{E}\left[\alpha_1X_1+\ldots+\alpha_nX_n\,\big|\,\{Y_1,\ldots,Y_m\}\right]=(\alpha_1+\ldots+\alpha_m)(Y_1+\ldots+Y_m),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Calpha_1X_1%2B%5Cldots%2B%5Calpha_nX_n%5C%2C%5Cbig%7C%5C%2C%5C%7BY_1%2C%5Cldots%2CY_m%5C%7D%5Cright%5D%3D%28%5Calpha_1%2B%5Cldots%2B%5Calpha_m%29%28Y_1%2B%5Cldots%2BY_m%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
which is not in general equal to 
Non-uniform weighted sampling
Of course, it’s not always the case that we want to sample according to the uniform distribution. My recent personal motivation for investigating this setup has been the notion of exploring a graph generated by the configuration model, for which vertices appear for the first time in a random order that is size-biased by their degrees.
In general we can think of each element of 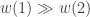
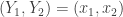
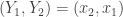
In addition, it will in general not be the case that
![\mathbb{E}[Y_1+\ldots+Y_m]=\mathbb{E}[X_1+\ldots+X_m],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_m%5D%3D%5Cmathbb%7BE%7D%5BX_1%2B%5Cldots%2BX_m%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and this is easily seen again in the above example, where ![\mathbb{E}[Y_1+Y_2]=x_1+x_2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_1%2BY_2%5D%3Dx_1%2Bx_2&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[X_1+X_2]\approx 2x_1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%2BX_2%5D%5Capprox+2x_1&bg=ffffff&fg=333333&s=0&c=20201002)
However, one can still compare such distributions, with the notion of increasing convex ordering, which is defined as:
![X\le_{icx} Y\;\iff\; \mathbb{E}[f(X)]\le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bicx%7D+Y%5C%3B%5Ciff%5C%3B+%5Cmathbb%7BE%7D%5Bf%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
for all convex non-decreasing functions f. From an economic point view, increasing convex ordering becomes a comment on the relative contribution of losses above some threshold between the two distributions (and that X is better or worse than Y for all such thresholds), and is sometimes called stop-loss order. More formally, as in [BM05] we have:
![X\le_{icx}Y\;\iff\; \mathbb{E}[\max(X-t,0)]\le \mathbb{E}[\max(Y-t,0)]\,\forall t\in\mathbb{R}.](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bicx%7DY%5C%3B%5Ciff%5C%3B+%5Cmathbb%7BE%7D%5B%5Cmax%28X-t%2C0%29%5D%5Cle+%5Cmathbb%7BE%7D%5B%5Cmax%28Y-t%2C0%29%5D%5C%2C%5Cforall+t%5Cin%5Cmathbb%7BR%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
In [BPS18], the authors study the case of successive sampling where the weights are monotone-increasing in the values, that is 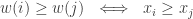
The coupling introduced above is particularly useful in this more exotic setting. The authors show that conditional on the event A of the form 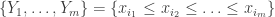
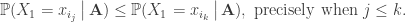
This is achieved by comparing the explicit probabilities of pairs of orderings for 
![\mathbb{E}[X_1\,\big|\, \mathbf{A}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%5C%2C%5Cbig%7C%5C%2C+%5Cmathbf%7BA%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[X_1\,\big|\, \mathbf{A}] = \sum_{j=1}^m x_{i_j}\mathbb{P}(X_1=x_{i_j}) \le \frac{1}{n}\left(\sum_{j=1}^m x_{i_j}\right)\left(\sum \mathbb{P}\right) = \frac{\left(Y_1+\ldots+Y_m\,\big|\,\mathbf{A}\right)}{m}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%5C%2C%5Cbig%7C%5C%2C+%5Cmathbf%7BA%7D%5D+%3D+%5Csum_%7Bj%3D1%7D%5Em+x_%7Bi_j%7D%5Cmathbb%7BP%7D%28X_1%3Dx_%7Bi_j%7D%29+%5Cle+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28%5Csum_%7Bj%3D1%7D%5Em+x_%7Bi_j%7D%5Cright%29%5Cleft%28%5Csum+%5Cmathbb%7BP%7D%5Cright%29+%3D+%5Cfrac%7B%5Cleft%28Y_1%2B%5Cldots%2BY_m%5C%2C%5Cbig%7C%5C%2C%5Cmathbf%7BA%7D%5Cright%29%7D%7Bm%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
As before, letting 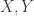
![\mathbb{E}[X\,\big|\, Y] \ge Y](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5C%2C%5Cbig%7C%5C%2C+Y%5D+%5Cge+Y&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[f(X)] = \mathbb{E}\left[ \mathbb{E}[f(X)|Y] \right] \ge \mathbb{E}\left[f\left(\mathbb{E}[X|Y] \right)\right] \ge \mathbb{E}\left[ f(Y)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cmathbb%7BE%7D%5Bf%28X%29%7CY%5D+%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5Bf%5Cleft%28%5Cmathbb%7BE%7D%5BX%7CY%5D+%5Cright%29%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
works exactly as before to establish convex ordering.
References
[Az67] – Azuma – 1967 – Weighted sums of certain dependent random variables
[BM05] – Bauerle, Muller – 2005 – Stochastic orders and risk measures: consistency and bounds. (Online version here)
[BPS18] – Ben Hamou, Peres, Salez – 2018 – Weighted sampling without replacement (ArXiv version here)
[Ho63] – Hoeffding – 1963 – Probability inequalities for sums of bounded random variables
[Oh69] – Ohlin – 1969 – On a class of measures of dispersion with application to optimal reinsurance

Great post!!! Thank you
Pingback: Convex ordering on trees | Eventually Almost Everywhere