
This blog was recently revived, via a post about convex ordering and its relevance to the problem of sampling with and without replacement that forms part of the potpourri of related results all sometimes referred to as Hoeffding’s inequality.
The previous post had been lying almost-complete but dormant for over two years. I revisited it because of a short but open-ended question about trees posed in our research group meeting by Serte Donderwinkel, one of our high-flying doctoral students.
Simplified Question:
For a Galton-Watson tree, can one obtain upper bounds in probability on the height of the tree, uniformly across all offspring distributions with mean 
Note that in this setting, it is helpful to have in mind the classical notation 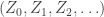
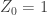
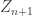
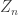

1) Subcritical case. When 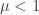
![\mathbb{P}(Z_k>0)\le \mathbb{E}[Z_k]=\mu^k](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28Z_k%3E0%29%5Cle+%5Cmathbb%7BE%7D%5BZ_k%5D%3D%5Cmu%5Ek&bg=ffffff&fg=333333&s=0&c=20201002)
Furthermore, if we’re studying all such offspring distributions, this is the best possible upper bound, by considering the offspring distribution given by 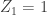
2) In the critical or supercritical case, 
So neither case is especially interesting for now.
Refined question:
What if instead we aren’t trying to obtain a bound uniformly across all offspring distributions with given mean 
This is the question Serte was asking in our group meeting, in the setting where 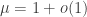
Nonetheless the interpretation via convex ordering feels perfect for a blog post, rather than being lost forever.
Convex ordering for offspring distributions
The main observation is that given two offspring distributions X and Y, such that 
As a warm-up, and because it was the original genesis, we first study heights. We will use the notation
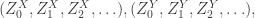
to denote the two Galton-Watson processes. We shall compare 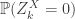
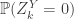

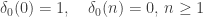
it holds that 
![\mathbb{E}[\delta_0(X)]\le \mathbb{E}[\delta_0(Y)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdelta_0%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5B%5Cdelta_0%28Y%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
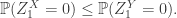
We can then prove that 
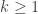

![\mathbb{P}(Z^X_{k+1}=0) = \mathbb{E}\left[ (\mathbb{P}(Z^X_k=0))^X\right] \le \mathbb{E}\left[(\mathbb{P}(Z^X_k=0))^Y\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28Z%5EX_%7Bk%2B1%7D%3D0%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%28%5Cmathbb%7BP%7D%28Z%5EX_k%3D0%29%29%5EX%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%28%5Cmathbb%7BP%7D%28Z%5EX_k%3D0%29%29%5EY%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
By the induction hypothesis, this final quantity is at most
![\mathbb{E}\left[(\mathbb{P}(Z^Y_k=0))^Y\right] = \mathbb{P}(Z^Y_{k+1}=0)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%28%5Cmathbb%7BP%7D%28Z%5EY_k%3D0%29%29%5EY%5Cright%5D+%3D+%5Cmathbb%7BP%7D%28Z%5EY_%7Bk%2B1%7D%3D0%29&bg=ffffff&fg=333333&s=0&c=20201002)
In conclusion, we have shown that
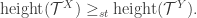
To return to the original context, suppose we have a large class of offspring distributions 

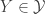

Convex ordering of generation sizes
The above argument solves the original problem, but brushes over the natural question: is it true that 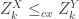
The answer is yes. Here’s a proof.
This follows from the following general statement:
Lemma 1: Suppose 
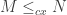
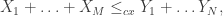
where 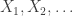
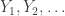
Lemma 2: Suppose 
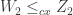

Proof of Lemma 2: First, note that for any random variable X, and convex function f
![\mathbb{E}\left[f(Z+x)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bf%28Z%2Bx%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
(Indeed, this holds since “f(z+x) is convex” holds for every z, and any definition of convex will pass to the expectation.)
Now we can attack the lemma directly, we may write
![\mathbb{E}\left[ f(W_1+W_2)\right]=\mathbb{E}\left[\, \mathbb{E}[f(W_1+W_2) \mid W_2 ] \,\right] \le \mathbb{E}\left[\, \mathbb{E}[f(W_1+Z_2)\mid Z_2 ] \, \right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28W_1%2BW_2%29%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5Bf%28W_1%2BW_2%29+%5Cmid+W_2+%5D+%5C%2C%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5Bf%28W_1%2BZ_2%29%5Cmid+Z_2+%5D+%5C%2C+%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
But then for any 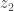
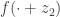
![\mathbb{E}[f(W_1+z_2)]\le \mathbb{E}[f(Z_1+z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28W_1%2Bz_2%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Z_1%2Bz_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[ f(W_1+W_2)\right]\le \mathbb{E} \left[ f(Z_1+Z_2)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28W_1%2BW_2%29%5Cright%5D%5Cle+%5Cmathbb%7BE%7D+%5Cleft%5B+f%28Z_1%2BZ_2%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
which proves the lemma.
Corollary 3: When 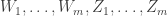

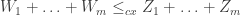
Proof of Lemma 1: Note that
![\mathbb{E}\left[ f(X_1+\ldots+X_M)\mid M=n\right] \le \mathbb{E}\left[ f(Y_1+\ldots+Y_N)\mid N=n\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28X_1%2B%5Cldots%2BX_M%29%5Cmid+M%3Dn%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y_1%2B%5Cldots%2BY_N%29%5Cmid+N%3Dn%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
follows from Corollary 3. So a useful question to consider is whether ![\mathbb{E}\left[f(Y_1+\ldots+Y_n)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bf%28Y_1%2B%5Cldots%2BY_n%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Denote this quantity by 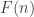

There is a canonical coupling between the RVs used to define all of 
![F(n+1)-F(n)= \mathbb{E}\left[ f(Y_1+\ldots+Y_n + Y^*) - f(Y_1+\ldots+Y_n)\right],](https://s0.wp.com/latex.php?latex=F%28n%2B1%29-F%28n%29%3D+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y_1%2B%5Cldots%2BY_n+%2B+Y%5E%2A%29+-+f%28Y_1%2B%5Cldots%2BY_n%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![F(n)-F(n-1)=\mathbb{E}\left[f(Y_1+\ldots+Y_{n-1}+Y^*) - f(Y_1+\ldots+Y_{n-1})\right],](https://s0.wp.com/latex.php?latex=F%28n%29-F%28n-1%29%3D%5Cmathbb%7BE%7D%5Cleft%5Bf%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%2BY%5E%2A%29+-+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
where 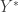

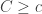

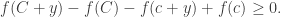
(Essentially, this says that the ‘chord’ of f on the interval ![[c,C+y]](https://s0.wp.com/latex.php?latex=%5Bc%2CC%2By%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![[C,c+y]](https://s0.wp.com/latex.php?latex=%5BC%2Cc%2By%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![[c+y,C]](https://s0.wp.com/latex.php?latex=%5Bc%2By%2CC%5D&bg=ffffff&fg=333333&s=0&c=20201002)
In any case, setting 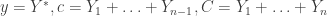
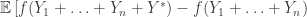
![\left.- f(Y_1+\ldots+Y_{n-1}+Y^*) + f(Y_1+\ldots+Y_{n-1})\right]\ge 0,](https://s0.wp.com/latex.php?latex=%5Cleft.-+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%2BY%5E%2A%29+%2B+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%29%5Cright%5D%5Cge+0%2C&bg=ffffff&fg=333333&s=0&c=20201002)
as required. So
![\mathbb{E}\left[ X_1+\ldots+X_M\right] = \mathbb{E}\left[ \,\mathbb{E}[X_1+\ldots+X_M\mid M]\,\right] \le \mathbb{E}\left[\, \mathbb{E}[Y_1+\ldots+Y_M\mid M]\,\right] = \mathbb{E}[f(M)]\le \mathbb{E}[f(N)] = \mathbb{E}[Y_1+\ldots+Y_N],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+X_1%2B%5Cldots%2BX_M%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5C%2C%5Cmathbb%7BE%7D%5BX_1%2B%5Cldots%2BX_M%5Cmid+M%5D%5C%2C%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_M%5Cmid+M%5D%5C%2C%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Bf%28M%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28N%29%5D+%3D+%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_N%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
completing the proof of Lemma 1.
Final comments
- The analysis in this post is not sufficient to study the total population sizes of two Galton-Watson trees generated by X and Y. Note that in Lemma 2, it is important that the random variables are independent. Otherwise, we could, for example, consider
with
. So for total population size, since
are not independent, an alternative approach would be required.
- A further characterisation of convex ordering is given by Strassen’s theorem [Str65], which is touched on in the previous post, and to which I may return to in a future post on this topic. This may be a more promising avenue for established a convex ordering result on total population size.
- Lemma 1 requires that X,Y are non-negative. Note that during the argument we set
- In a recent article in ECP addressing Lemma 1 by a different method, Berard and Juillet [BJ20] provide a simple example showing that the non-negative assumption is genuinely necessary. Consider the random variable
with equal probability so
. But then, taking both X and Y to be simple random walk on
, we do not have
.
References
[BJ20] – Berard, Juillet – A coupling proof of convex ordering for compound distributions, 2020
[Str65] – Strassen – The existence of probability measures with given marginals, 1965
