
As I’ve explained in some posts from a while ago, I’ve been thinking about some models related to random graph processes, where we ensure the configuration stays critical by deleting any cycles as they appear. Under various assumptions, this behaves in the limit as the number of vertices grows to infinity, like a coagulation-fragmentation process, with multiplicative coalescence and quadratic fragmentation rate, where the fragmentation kernel is the Poisson-Dirichlet distribution, PD(1/2,1/2). I found it quite hard to find accessible notes on these, partly because the theory is still relatively recently, and also because it seems to be one of those topics where you can’t understand anything properly until you kind of understand everything.
This post was motivated and is based on chapter 3 of Pitman’s Combinatorial Stochastic Processes, and the opening pair of lectures from Pierre Tarres’s TCC course on Self-Interaction and Learning.
It makes sense to begin by discussing the Dirichlet distribution, and there to start with the most simple case, the Beta distribution. As we learned in the Part A Statistics course while trying some canonical examples of posterior distributions, it is convenient to ignore the normalising constants of various distributions until right at the end. This is particularly true of the Beta distribution, which is indeed often used as a prior in such situations. The density function of 
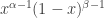

(note that the ‘base case’ is the definition of the Gamma function.) For the generalisation we are about to make, it is helpful to think of this Beta density as a distribution not on [0,1], but on partitions of [0,1] into two parts. That is pairs (x,y) such that x+y=1. Why? Because then the density has the form 
Indeed the Dirichlet distribution with parameters 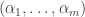
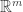
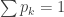
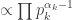

You can prove this by inducting on the number of variables, using the Beta distribution as a base case.
In many situations, it is useful to be able to express some distribution as a function of IID random variables with a simpler distribution. We can’t quite do that for the Dirichlet distribution, but we can express it very simply as function of independent RVs from the same family. It turns out that the family of Gamma distributions is a wise choice. Recall that the gamma distribution with parameters 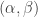
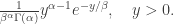
Anyway, define independent RVs 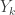
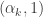
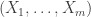
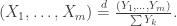
In other words, the Dirichlet distribution gives the ratio between independent gamma RVs. Note the following:
– the sum of the gamma distributions, ie the factor we have to scale by to get back to a ratio, is a gamma distribution itself.
– If we wanted, we could define it in an identical way using Gamma with parameters 

– More helpfully, because the gamma distribution is additive in the first argument, we can take a limit to construct a gamma process, where the increments have the form required. This will be a useful interpretation when we take a limit, as largest increments will correspond to largest jumps.
Polya’s Urn
This is one of the best examples of a self-reinforcing process, where an event which has happened in the past is more likely to happen again in the future.
The basic model is as follows. We start with one white ball and one black ball in a bag. We draw a ball from the bag uniformly at random then replace it along with an additional ball of the same colour. Repeat this procedure.
The first step is to look at the distribution at some time n, ie after n balls have been added, so there are n+2 in total. Note that there are exactly n+1 possibilities for the state of the bag at this time. We must have between 1 and n+1 black balls, and indeed all of these are possible. In general, part of the reason why this process is self-reinforcing is that any distribution is in some sense an equilibrium distribution.
What follows is a classic example of a situation which is a notational nightmare in general, but relatively straightforward for a fixed finite example.
Let’s example n=5, and consider the probability that the sequence of balls drawn is BBWBW. This probability is:

So far this isn’t especially illuminating, especially if we start trying to cancel these fractions. But note that the denominator of the product will clearly be 6!. What about the numerator? Well, the contribution to the numerator of the product from black balls is 1x2x3=3! while the contribution from white balls is 1×2=2!. In particular, the contribution to the numerator from each colour is independent of the order of whites and blacks. It depends only on the number of whites and blacks. So we can conclude that the probability that we end up a particular ordering of k+1 whites and (n-k)+1 blacks is
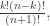
and so the probability that we end up with k+1 whites where we no longer care about ordering is

In other words, the distribution of the number of white balls in the bag after n balls have been added is uniform on [1, n+1].
That looks like it might be something of a neat trick, so the natural question to ask is what happens if we adjust the initial conditions. Suppose that instead we start with 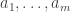
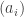

As before, the order in which balls of various colours are drawn doesn’t matter hugely. Suppose that the first n balls drawn feature 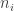
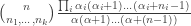
where 

![\frac{\alpha(\alpha+1)\ldots(\alpha+n-1)}{n!}=\frac{[\alpha_i+(n_i-1)]!}{n_i! (\alpha_i-1)!}\approx \frac{n_i^{\alpha_i-1}}{(\alpha_i-1)!}.](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Calpha%28%5Calpha%2B1%29%5Cldots%28%5Calpha%2Bn-1%29%7D%7Bn%21%7D%3D%5Cfrac%7B%5B%5Calpha_i%2B%28n_i-1%29%5D%21%7D%7Bn_i%21+%28%5Calpha_i-1%29%21%7D%5Capprox+%5Cfrac%7Bn_i%5E%7B%5Calpha_i-1%7D%7D%7B%28%5Calpha_i-1%29%21%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
The denominator will just be a fixed constant, so we get that overall, the probability above is approximately

which we recall is the pdf of the distribution distribution with parameters 
Next time I’ll introduce a more complicated family of self-reinforcing processes, and discuss some interesting limits of the Dirichlet distribution that relate to such processes.
Related articles
- The Poisson-Dirichlet process, and large prime factors of a random number (terrytao.wordpress.com)
- Polymath8b: Bounded intervals with many primes, after Maynard (terrytao.wordpress.com)


Pingback: The Chinese Restaurant Process | Eventually Almost Everywhere
Pingback: Persistent Hubs | Eventually Almost Everywhere