
A couple of months ago I wrote a post about Polya’s Urn, the simplest example of self-reinforcing process. Recall that we have a bag containing black and white balls, and sequentially we draw a ball then replace it together with an additional ball of the same colour. The process is self-reinforcing in the sense that if there is a surplus of black balls, the dynamics will reinforce this by adding more black balls than white balls. Alternatively, you can think of a natural limit process when the number of balls is large, for which any distribution is an invariant distribution. We have seen models such as the Preferential Attachment dynamics for network creation, where the degrees of vertices clearly have this self-reinforcing property. New vertices are more likely to join to existing vertices with large degrees.
One difference between the Polya Urn and some of the models we might be interested in for applications is that for the urn model, the number of classes (in this context colours of balls) is fixed. In many applications, we will want to allow new classes to appear. In the process which follows, we will allow this, and the new classes will have initial size equal to 1, so will be at a disadvantage for the self-reinforcing dynamics. Nonetheless, some will show up in a meaningful way in the limit. It is worth emphasising that Polya’s Urn gave us the Dirichlet distribution in the limit, and this can be thought of as a partition of [0,1]. These more general processes will give us a more interesting family of partitions, called the Poisson-Dirichlet distributions. These will turn up in a wide variety of contexts, and this is perhaps the friendliest way to introduce them.
The model is this. We start with a single diner who sits at the first table. Then whenever the (n+1)th diner arrives, they join a table with k diners already with probability k/n+1, and they start a new table with probability 1/n+1.
(Aside: I’m not exactly sure how this relates to a Chinese restaurant? It seems more reminiscent of a university dining hall during freshers’ week, but I guess that would be a less catchy name for a model.)
Anyway, the interest in this description lies not in organising seating arrangements. Consider choosing uniformly at random from the set of permutations on [n+1]. Suppose x maps to n+1 and n+1 maps to y. Consider taking the permutation of [n] formed by instead mapping x to y and ignoring n+1. This has the uniform distribution on the set of permutations of [n]. By reversing this procedure, we can construct a uniform permutation of [n+1] from a uniform permutation of [n]. When you do this as a process for n growing, observe that the orbits correspond exactly to tables in the Chinese Restaurant Process. If we wanted the CRP to give all the information about the permutation, we could specify the ordering round each table, by saying that with probability 1/n+1 the new diner sits to the left of any given existing diner.
As a starting point for why this is a useful description of the uniform permutation distribution, observe that the size of the component containing the element 1 evolves as a Polya Urn with initial vector (1,1). The second 1 in the initial vector corresponds to the possibility of starting a new table, which is maintained at every stage. This tells us immediately that as n grows to infinity, the proportion of elements in the same cycle as 1 in the uniform permutation converges in distribution to U[0,1]. The construction also allows for an easy proof that the expected number of cycles is roughly log n for large n, since on each pass of the process, the probability that there is a new cycle formed is 1/k.
In this case, the partition induced on [n] by the process is clearly exchangeable given our permutation description. However, this will turn out to hold in greater generality. Note also,, that conditional on the size of the cycle containing 1, the sizes of the remaining cycles are given by a uniform permutation on a smaller number of elements. So the limiting result holds jointly in the first k cycle sizes for all k. More precisely, if 
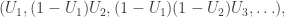
where the Us are independent U[0,1] RVs. This is known as a stick-breaking procedure, where at each step we break off some proportion of the stick according to a fixed distribution, and assemble the pieces into a partition.
We generalise this process to get a two-parameter version. The standard notation for the parameters is 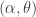


First we examine which parameters are possible. If 



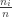
Obviously 
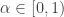

It turns out that the partitions induced by this process are exchangeable also. We also have a stick-breaking construction, although now the broken proportions are not IID, but distributed as
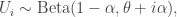
with the same notation otherwise. It turns out that under mild assumptions, these are all the infinite exchangeable random partitions with this stick-breaking property.
My initial struggle with this process was to understand what roles
3.2.2. Let an urn initially contain two balls of different colours. Draw 1 is a simple draw from the urn with replacement. Thereafter, balls are drawn from the urn, with replacement of the ball drawn, and addition of two more balls as follows. If the ball drawn is of a colour never drawn before, it is replaced together with two additional balls of two distinct new colours, different to the colours of balls already in the urn. Whereas if the ball drawn is of a colour that has been drawn before, it is replaced together with two balls of its own colour.
Let 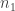

The other question I was puzzled by initially is where does the dust come from in the limit? Recall that in an infinite exchangeable partition, the sum of the frequencies does not need to be 1. The difference between this sum and 1 gives the probability that an element is in a block by itself. Obviously, when the number of tables is bounded (as when
Generalising Polya’s Urn in another direction, if I have time, I might write something about a model which I recently read about on arXiv where the classes are vertices of a graph, and there is dependence between them based on the presence of edges. This might also be a good moment to explain some other generalisations and stochastic approximation methods used to treat them.
REFERENCES
This post is almost entirely a paraphrase of Sections 3.1 and 3.2 from Pitman’s Combinatorial Stochastic Processes, available online here.
Related articles
- The Poisson-Dirichlet process, and large prime factors of a random number (terrytao.wordpress.com)

 is
is 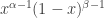 . If these are natural numbers, we have a quick proof by induction using integration by parts, otherwise a slightly longer but still elementary argument gives the normalising constant as
. If these are natural numbers, we have a quick proof by induction using integration by parts, otherwise a slightly longer but still elementary argument gives the normalising constant as
 and is clear how we might generalise this.
and is clear how we might generalise this.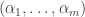 is a random variable supported on the subset of
is a random variable supported on the subset of 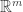 with
with 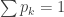 with density
with density 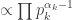 . For similar reasons, the correct normalising constant in the general case is
. For similar reasons, the correct normalising constant in the general case is
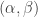 has density:
has density: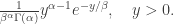
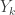 as gamma distributions with parameters
as gamma distributions with parameters 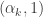 , then we can specify
, then we can specify 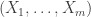 as the Dirichlet distribution with these parameters by:
as the Dirichlet distribution with these parameters by: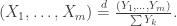
 for some fixed
for some fixed  .
.
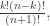

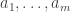 balls of each of m colours. Obviously, this is going to turn into a proof by suggestive notation. In fact, the model doesn’t really rely on the
balls of each of m colours. Obviously, this is going to turn into a proof by suggestive notation. In fact, the model doesn’t really rely on the 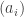 being positive integers. Everything carries through with
being positive integers. Everything carries through with  if we view the vector as the initial distribution.
if we view the vector as the initial distribution.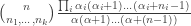
 . Then for large n, assuming for now that the
. Then for large n, assuming for now that the  we have
we have![\frac{\alpha(\alpha+1)\ldots(\alpha+n-1)}{n!}=\frac{[\alpha_i+(n_i-1)]!}{n_i! (\alpha_i-1)!}\approx \frac{n_i^{\alpha_i-1}}{(\alpha_i-1)!}.](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Calpha%28%5Calpha%2B1%29%5Cldots%28%5Calpha%2Bn-1%29%7D%7Bn%21%7D%3D%5Cfrac%7B%5B%5Calpha_i%2B%28n_i-1%29%5D%21%7D%7Bn_i%21+%28%5Calpha_i-1%29%21%7D%5Capprox+%5Cfrac%7Bn_i%5E%7B%5Calpha_i-1%7D%7D%7B%28%5Calpha_i-1%29%21%7D.&bg=ffffff&fg=333333&s=0&c=20201002)

 as telegraphed by our choice of notation. With some suitable martingale machinery, you can also prove that this convergence happens almost surely, for a suitable limit RV defined on the tail sigma algebra.
as telegraphed by our choice of notation. With some suitable martingale machinery, you can also prove that this convergence happens almost surely, for a suitable limit RV defined on the tail sigma algebra.