In this post, I’m going to discuss some of the literature concerning the question of conditioning a simple random walk to lie above a line with fixed gradient. A special case of this situation is conditioning to stay non-negative. Some notation first. Let  be a random walk with IID increments, with distribution X. Take
be a random walk with IID increments, with distribution X. Take  to be the expectation of these increments, and we’ll assume that the variance
to be the expectation of these increments, and we’ll assume that the variance  is finite, though at times we may need to enforce slightly stronger regularity conditions.
is finite, though at times we may need to enforce slightly stronger regularity conditions.
(Although simple symmetric random walk is a good example for asymptotic heuristics, in general we also assume that if the increments are discrete they don’t have parity-based support, or any other arithmetic property that prevents local limit theorems holding.)
We will investigate the probability that 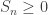 for n=0,1,…,N, particularly for large N. For ease of notation we write
for n=0,1,…,N, particularly for large N. For ease of notation we write 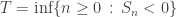 for the hitting time of the negative half-plane. Thus we are interested in
for the hitting time of the negative half-plane. Thus we are interested in  conditioned on T>N, or T=N, mindful that these might not be the same. We will also discuss briefly to what extent we can condition on
conditioned on T>N, or T=N, mindful that these might not be the same. We will also discuss briefly to what extent we can condition on  .
.
In the first paragraph, I said that this is a special case of conditioning SRW to lie above a line with fixed gradient. Fortunately, all the content of the general case is contained in the special case. We can repose the question of conditioned to stay above  until step N by the question of
until step N by the question of  (which, naturally, has drift
(which, naturally, has drift  ) conditioned to stay non-negative until step N, by a direct coupling.
) conditioned to stay non-negative until step N, by a direct coupling.
Applications
Simple random walk is a perfectly interesting object to study in its own right, and this is a perfectly natural question to ask about it. But lots of probabilistic models can be studied via naturally embedded SRWs, and it’s worth pointing out a couple of applications to other probabilistic settings (one of which is the reason I was investigating this literature).
In many circumstances, we can desribe random trees and random graphs by an embedded random walk, such as an exploration process, as described in several posts during my PhD, such as here and here. The exploration process of a Galton-Watson branching tree is a particularly good example, since the exploration process really is simple random walk, unlike in, for example, the Erdos-Renyi random graph G(N,p), where the increments are only approximately IID. In this setting, the increments are given by the offspring distribution minus one, and the hitting time of -1 is the total population size of the branching process. So if the expectation of the offspring distribution is at most 1, then the event that the size of the tree is large is an atypical event, corresponding to delayed extinction. Whereas if the expectation is greater than one, then it is an event with limiting positive probability. Indeed, with positive probability the exploration process never hits -1, corresponding to survival of the branching tree. There are plenty of interesting questions about the structure of a branching process tree conditional on having atypically large size, including the spine decomposition of Kesten [KS], but the methods described in this post can be used to quantify the probability, or at least the scale of the probability of this atypical event.
In my current research, I’m studying a random walk embedded in a construction of the infinite-volume DGFF pinned at zero, as introduced by Biskup and Louidor [BL]. The random walk controls the gross behaviour of the field on annuli with dyadically-growing radii. Anyway, in this setting the random walk has Gaussian increments. (In fact, there is a complication because the increments aren’t exactly IID, but that’s definitely not a problem at this level of exposition.) The overall field is decomposed as a sum of the random walk, plus independent DGFFs with Dirichlet boundary conditions on each of the annuli, plus asymptotically negligible corrections from a ‘binding field’. Conditioning that this pinned field be non-negative up to the Kth annulus corresponds to conditioning the random walk to stay above the magnitude of the minimum of each successive annular DGFF. (These minima are random, but tightly concentrated around their expectations.)
Conditioning on 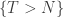
When we condition on 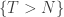 , obviously the resulting distribution (of the process) is a mixture of the distributions we obtain by conditioning on each of
, obviously the resulting distribution (of the process) is a mixture of the distributions we obtain by conditioning on each of  . Shortly, we’ll condition on
. Shortly, we’ll condition on  itself, but first it’s worth establishing how to relate the two options. That is, conditional on , what is the distribution of T?
itself, but first it’s worth establishing how to relate the two options. That is, conditional on , what is the distribution of T?
Firstly, when  , this event always has positive probability, since
, this event always has positive probability, since  . So as
. So as 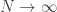 , the distribution of the process conditional on converges to the distribution of the process conditional on survival. So we’ll ignore this for now.
, the distribution of the process conditional on converges to the distribution of the process conditional on survival. So we’ll ignore this for now.
In the case 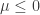 , everything is encapsulated in the tail of the probabilities
, everything is encapsulated in the tail of the probabilities  , and these tails are qualitatively different in the cases
, and these tails are qualitatively different in the cases 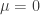 and
and  .
.
When , then decays polynomially in N. In the special case where is simple symmetric random walk (and N has the correct parity), we can check this just by an application of Stirling’s formula to count paths with this property. By contrast, when , even demanding 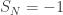 is a large deviations event in the sense of Cramer’s theorem, and so the probability decays exponentially with N. Mogulskii’s theorem gives a large deviation principle for random walks to lie above a line defined on the scale N. The crucial fact here is that the probabilistic cost of staying positive until N has the same exponent as the probabilistic cost of being positive at N. Heuristically, we think of spreading the non-expected behaviour of the increments uniformly through the process, at only polynomial cost once we’ve specified the multiset of values taken by the increments. So, when , we have
is a large deviations event in the sense of Cramer’s theorem, and so the probability decays exponentially with N. Mogulskii’s theorem gives a large deviation principle for random walks to lie above a line defined on the scale N. The crucial fact here is that the probabilistic cost of staying positive until N has the same exponent as the probabilistic cost of being positive at N. Heuristically, we think of spreading the non-expected behaviour of the increments uniformly through the process, at only polynomial cost once we’ve specified the multiset of values taken by the increments. So, when , we have

Therefore, conditioning on  in fact concentrates T on N+o(N). Whereas by contrast, when , conditioning on gives a nontrivial limit in distribution for T/N, supported on
in fact concentrates T on N+o(N). Whereas by contrast, when , conditioning on gives a nontrivial limit in distribution for T/N, supported on  .
.
A related problem is the value taken by 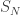 , conditional on {T>N}. It’s a related problem because the event {T>N} depends only on the process up to time N, and so given the value of , even with the conditioning, after time N, the process is just an unconditioned RW. This is a classic application of the Markov property, beloved in several guises by undergraduate probability exam designers.
, conditional on {T>N}. It’s a related problem because the event {T>N} depends only on the process up to time N, and so given the value of , even with the conditioning, after time N, the process is just an unconditioned RW. This is a classic application of the Markov property, beloved in several guises by undergraduate probability exam designers.
Anyway, Iglehart [Ig2] shows an invariance principle for  when , without scaling. That is
when , without scaling. That is  , though the limiting distribution depends on the increment distribution in a sense that is best described through Laplace transforms. If we start a RW with negative drift from height O(1), then it hits zero in time O(1), so in fact this shows that conditonal on , we have T= N +O(1) with high probability. When , we have fluctuations on a scale
, though the limiting distribution depends on the increment distribution in a sense that is best described through Laplace transforms. If we start a RW with negative drift from height O(1), then it hits zero in time O(1), so in fact this shows that conditonal on , we have T= N +O(1) with high probability. When , we have fluctuations on a scale  , as shown earlier by Iglehart [Ig1]. Again, thinking about the central limit theorem, this fits the asymptotic description of T conditioned on T>N.
, as shown earlier by Iglehart [Ig1]. Again, thinking about the central limit theorem, this fits the asymptotic description of T conditioned on T>N.
Conditioning on 
In the case , conditioning on T=N gives
![\left[\frac{1}{\sqrt{N}}S(\lfloor Nt\rfloor ) ,t\in[0,1] \right] \Rightarrow W^+(t),](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7B1%7D%7B%5Csqrt%7BN%7D%7DS%28%5Clfloor+Nt%5Crfloor+%29+%2Ct%5Cin%5B0%2C1%5D+%5Cright%5D+%5CRightarrow+W%5E%2B%28t%29%2C&bg=ffffff&fg=333333&s=0&c=20201002) (*)
(*)
where  is a standard Brownian excursion on [0,1]. This is shown roughly simultaneously in [Ka] and [DIM]. This is similar to Donsker’s theorem for the unconditioned random walk, which converges after rescaling to Brownian motion in this sense, or Brownian bridge if you condition on
is a standard Brownian excursion on [0,1]. This is shown roughly simultaneously in [Ka] and [DIM]. This is similar to Donsker’s theorem for the unconditioned random walk, which converges after rescaling to Brownian motion in this sense, or Brownian bridge if you condition on 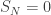 . Skorohod’s proof for Brownian bridge [Sk] approximates the event
. Skorohod’s proof for Brownian bridge [Sk] approximates the event  by
by ![\{S_N\in[-\epsilon \sqrt{N},+\epsilon \sqrt{N}]\}](https://s0.wp.com/latex.php?latex=%5C%7BS_N%5Cin%5B-%5Cepsilon+%5Csqrt%7BN%7D%2C%2B%5Cepsilon+%5Csqrt%7BN%7D%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) , since the probability of this event is bounded away from zero. Similarly, but with more technicalities, a proof of convergence conditional on T=N can approximate by
, since the probability of this event is bounded away from zero. Similarly, but with more technicalities, a proof of convergence conditional on T=N can approximate by ![\{S_m\ge 0, m\in[\delta N,(1-\delta)N], S_N\in [-\epsilon \sqrt{N},+\epsilon\sqrt{N}]\}](https://s0.wp.com/latex.php?latex=%5C%7BS_m%5Cge+0%2C+m%5Cin%5B%5Cdelta+N%2C%281-%5Cdelta%29N%5D%2C+S_N%5Cin+%5B-%5Cepsilon+%5Csqrt%7BN%7D%2C%2B%5Cepsilon%5Csqrt%7BN%7D%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The technicalities here emerge since T, the first return time to zero, is not continuous as a function of continuous functions. (Imagine a sequence of processes
. The technicalities here emerge since T, the first return time to zero, is not continuous as a function of continuous functions. (Imagine a sequence of processes  for which
for which 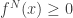 on [0,1] and
on [0,1] and  .)
.)
Once you condition on , the mean doesn’t really matter for this scaling limit. That is, so long as variance is finite, for any 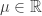 , the same result (*) holds, although a different proof is in general necessary. See [BD] and references for details. However, this is particularly clear in the case where the increments are Gaussian. In this setting, we don’t actually need to take a scaling limit. The distribution of Gaussian *random walk bridge* doesn’t depend on the mean of the increments. This is related to the fact that a linear transformation of a Gaussian is Gaussian, and can be seen by examining the joint density function directly.
, the same result (*) holds, although a different proof is in general necessary. See [BD] and references for details. However, this is particularly clear in the case where the increments are Gaussian. In this setting, we don’t actually need to take a scaling limit. The distribution of Gaussian *random walk bridge* doesn’t depend on the mean of the increments. This is related to the fact that a linear transformation of a Gaussian is Gaussian, and can be seen by examining the joint density function directly.
Conditioning on
When , the event  occurs with positive probability, so it is well-defined to condition on it. When , this is not the case, and so we have to be more careful.
occurs with positive probability, so it is well-defined to condition on it. When , this is not the case, and so we have to be more careful.
First, an observation. Just for clarity, let’s take , and condition on , and look at the distribution of  , where
, where  is small. This is approximately given by
is small. This is approximately given by
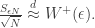
Now take  and consider the RHS. If instead of the Brownian excursion , we instead had Brownian motion, we could specify the distribution exactly. But in fact, we can construct Brownian excursion as the solution to an SDE:
and consider the RHS. If instead of the Brownian excursion , we instead had Brownian motion, we could specify the distribution exactly. But in fact, we can construct Brownian excursion as the solution to an SDE:
![\mathrm{d}W^+(t) = \left[\frac{1}{W^+(t)} - \frac{W^+(t)}{1-t}\right] \mathrm{d}t + \mathrm{d}B(t),\quad t\in(0,1)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bd%7DW%5E%2B%28t%29+%3D+%5Cleft%5B%5Cfrac%7B1%7D%7BW%5E%2B%28t%29%7D+-+%5Cfrac%7BW%5E%2B%28t%29%7D%7B1-t%7D%5Cright%5D+%5Cmathrm%7Bd%7Dt+%2B+%5Cmathrm%7Bd%7DB%28t%29%2C%5Cquad+t%5Cin%280%2C1%29&bg=ffffff&fg=333333&s=0&c=20201002) (**)
(**)
for B a standard Brownian motion. I might return in the next post to why this is valid. For now, note that the first drift term pushes the excursion away from zero, while the second term brings it back to zero as 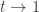 .
.
From this, the second drift term is essentially negligible if we care about scaling  as
as 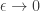 , and we can say that
, and we can say that 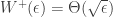 .
.
So, returning to the random walk, we have

At a heuristic level, it’s tempting to try ‘taking while fixing 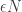 ‘, to conclude that there is a well-defined scaling limit for the RW conditioned to stay positive forever. But we came up with this estimate by taking and then in that order. So while the heuristic might be convincing, this is not the outline of a valid argument in any way. However, the SDE representation of in the regime is useful. If we drop the second drift term in (**), we define the three-dimensional Bessel process, which (again, possibly the subject of a new post) is the correct scaling limit we should be aiming for.
‘, to conclude that there is a well-defined scaling limit for the RW conditioned to stay positive forever. But we came up with this estimate by taking and then in that order. So while the heuristic might be convincing, this is not the outline of a valid argument in any way. However, the SDE representation of in the regime is useful. If we drop the second drift term in (**), we define the three-dimensional Bessel process, which (again, possibly the subject of a new post) is the correct scaling limit we should be aiming for.
Finally, it’s worth observing that the limit 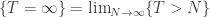 is a monotone limit, and so further tools are available. In particular, if we know that the trajectories of the random walk satisfy the FKG property, then we can define this limit directly. It feels intuitively clear that random walks should satisfy the FKG inequality (in the sense that if a RW is large somewhere, it’s more likely to be large somewhere else). You can do a covariance calculation easily, but a standard way to show the FKG inequality applies is by verifying the FKG lattice condition, and unless I’m missing something, this is clear (though a bit annoying to check) when the increments are Gaussian, but not in general. Even so, defining this monotone limit does not tell you that it is non-degenerate (ie almost-surely finite), for which some separate estimates would be required.
is a monotone limit, and so further tools are available. In particular, if we know that the trajectories of the random walk satisfy the FKG property, then we can define this limit directly. It feels intuitively clear that random walks should satisfy the FKG inequality (in the sense that if a RW is large somewhere, it’s more likely to be large somewhere else). You can do a covariance calculation easily, but a standard way to show the FKG inequality applies is by verifying the FKG lattice condition, and unless I’m missing something, this is clear (though a bit annoying to check) when the increments are Gaussian, but not in general. Even so, defining this monotone limit does not tell you that it is non-degenerate (ie almost-surely finite), for which some separate estimates would be required.
A final remark: in a recent post, I talked about the Skorohod embedding, as a way to construct any centered random walk where the increments have finite variance as a stopped Brownian motion. One approach to conditioning a random walk to lie above some discrete function is to condition the corresponding Brownian motion to lie above some continuous extension of that function. This is a slightly stronger conditioning, and so any approach of this kind must quantify how much stronger. In Section 4 of [BL], the authors do this for the random walk associated with the DGFF conditioned to lie above a polylogarithmic curve.
References
[BD] – Bertoin, Doney – 1994 – On conditioning a random walk to stay nonnegative
[BL] – Biskup, Louidor – 2016 – Full extremal process, cluster law and freezing for two-dimensional discrete Gaussian free field
[DIM] – Durrett, Iglehart, Miller – 1977 – Weak convergence to Brownian meander and Brownian excursion
[Ig1] – Iglehart – 1974 – Functional central limit theorems for random walks conditioned to stay positive
[Ig2] – Iglehart – 1974 – Random walks with negative drift conditioned to stay positive
[Ka] – Kaigh – 1976 – An invariance principle for random walk conditioned by a late return to zero
[KS] – Kesten, Stigum – 1966 – A limit theorem for multidimensional Galton-Watson processes
[Sk] – Skorohod – 1955 – Limit theorems for stochastic processes with independent increments

