I’m back in Rio, this time for the Brazilian Probability School, which this year is being held in parallel with the Brazilian Mathematical Colloquium, so there’s a lot of possible lectures to be attending across a wide range of topics. I’ve been paying particular to a course by Veronique Gayrard concerning the phenomenon of aging, as seen in various spin-glass and trap models. [Lecture notes exist, but haven’t yet been put online.]
I want to write something about the setup for one of these models. It took me quite a long time to settle on a title for this post, and as you can see I’ve hedged. At least in this post, I’m not so interested in the model (and don’t want to try and offer a physical motivation at this point) but rather in talking about the natural model-independent problem it reduces to.
Motivation
Let  be IID random variables which take some fixed value K>0 with probability 1/K, and otherwise take the value zero. The law of large numbers says that for large m, the rescaled partial sum process
be IID random variables which take some fixed value K>0 with probability 1/K, and otherwise take the value zero. The law of large numbers says that for large m, the rescaled partial sum process  . The weak LLN makes this precise in the sense of convergence in distribution, and the strong LLN gives almost sure convergence.
. The weak LLN makes this precise in the sense of convergence in distribution, and the strong LLN gives almost sure convergence.
But the speed of convergence is obviously not uniform over all distributions of the underlying IID random variables. This is particularly clear in the setup I’ve outlined, in the regime where 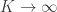 . Certainly if
. Certainly if  , then we have
, then we have 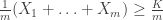 with probability
with probability 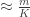 and otherwise
and otherwise  . So if we let K and m diverge together with scaling as given, the only version of a LLN we can write down is
. So if we let K and m diverge together with scaling as given, the only version of a LLN we can write down is

which is obviously different to the original version for fixed K and diverging m.
If we take 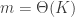 , then the rescaled partial sum process converges in distribution to a scaled Poisson process. Of course, the Poisson process obeys it’s own law of large numbers (or law of large times), but on this scale the first-order behaviour is random.
, then the rescaled partial sum process converges in distribution to a scaled Poisson process. Of course, the Poisson process obeys it’s own law of large numbers (or law of large times), but on this scale the first-order behaviour is random.
At a more general level, what we are doing in the previous examples is looking at a process which converges to equilibrium, but studying it on a faster timescale than the timescale of this convergence. The REM-like trap model, which will be the eventual focus of this post, does exactly this to a continuous-time Markov chain, with the additional factor that the holding rates are random and heavy-tailed.
The mean-field REM-like trap model
This REM-like trap model is defined as follows. We have N sites, and for these sites we sample an IID collection of holding rates  according to some distribution. We then choose a sequence of a IID uniform samples from {1,…,N}, labelled
according to some distribution. We then choose a sequence of a IID uniform samples from {1,…,N}, labelled  . We think of this as recording an itinerary of visits to the sites, where the jth site we visit is
. We think of this as recording an itinerary of visits to the sites, where the jth site we visit is  . (Though notice that under this definition, it’s possible that the jth site we visit and the j+1st site we visit are the same.) We wait at each site for an exponential holding time, with parameter
. (Though notice that under this definition, it’s possible that the jth site we visit and the j+1st site we visit are the same.) We wait at each site for an exponential holding time, with parameter  if we are at site j, and these holding times are independent of the other holding times, and independent of the trajectory, all conditional on .
if we are at site j, and these holding times are independent of the other holding times, and independent of the trajectory, all conditional on .
You can think of this as a continuous-time RW on the complete graph 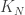 (with self-loops), where the jump chain is uniform, and the holding rates are given by . This explains the notation, and how you’d construct a similar model on a different underlying graph.
(with self-loops), where the jump chain is uniform, and the holding rates are given by . This explains the notation, and how you’d construct a similar model on a different underlying graph.
The general of a trap model is a random walk with very inhomogeneous speed, for example because some holding times have very large expectation. In a setting with more inbuilt geometry, for example on a lattice, we can imagine the RW getting trapped in regions associated with atypically low speeds. We might therefore think of a site with very long holding times as being deep, in the sense that the chain might get stuck there.
This will be most interesting if we allow an extreme range of values taken by  , and so the best choice is a distribution in the domain of attraction of an
, and so the best choice is a distribution in the domain of attraction of an  -stable law with parameter
-stable law with parameter 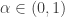 . That is
. That is 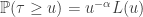 , where L is a slowly-varying function at
, where L is a slowly-varying function at 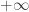 .
.
This distribution has infinite mean, and so we couldn’t apply either LLN to a sequence of copies of  . However, obviously the sequence almost surely does have finite mean, since each entry is finite! So for each N, the trap model will have a LLN on large timescales, but we will investigate at faster timescales.
. However, obviously the sequence almost surely does have finite mean, since each entry is finite! So for each N, the trap model will have a LLN on large timescales, but we will investigate at faster timescales.
The clock process
At least for the purpose of this post, we will focus on the clock process, which records the (continuous) time which elapses before we arrive at the *k*th state of the jump chain.
That is,
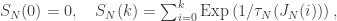
where the exponential random variables are independent except through their parameters. This can be made even more clear if we take advantage of the method to write a general exponential distribution as a multiple of a exponential distribution with parameter 1. Let 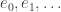 be IID exponential RVs independent of and the jump chain. Then
be IID exponential RVs independent of and the jump chain. Then
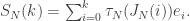
Let’s briefly pause to apply the LLN to 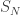 for fixed N. It matters whether we consider the quenched or annealed settings here. As usual, quenched means we fix a realisation of the random environment, and draw all conclusions in terms of that environment (think of conditional expectations). And annealed means that we also include the randomness of the environment. This is notationally annoying, so as a shorthand we write
for fixed N. It matters whether we consider the quenched or annealed settings here. As usual, quenched means we fix a realisation of the random environment, and draw all conclusions in terms of that environment (think of conditional expectations). And annealed means that we also include the randomness of the environment. This is notationally annoying, so as a shorthand we write  for quenched expectations
for quenched expectations ![\mathbb{E}[\cdot \,|\, \tau_N(1),\ldots,\tau_N(N)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ccdot+%5C%2C%7C%5C%2C+%5Ctau_N%281%29%2C%5Cldots%2C%5Ctau_N%28N%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and
, and  for an expectation over all randomness.
for an expectation over all randomness.
Then the quenched rate of growth of is given by
![\mathbb{E}_{\tau_N}\left[ \frac{S_N(k)}{k}\right] = \frac{\tau_N(1)+\ldots +\tau_N(N)}{N},](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Ctau_N%7D%5Cleft%5B+%5Cfrac%7BS_N%28k%29%7D%7Bk%7D%5Cright%5D+%3D+%5Cfrac%7B%5Ctau_N%281%29%2B%5Cldots+%2B%5Ctau_N%28N%29%7D%7BN%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
and so the annealed rate
![\mathbb{E}\left[\frac{S_N(k)}{k}\right] = \infty,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7BS_N%28k%29%7D%7Bk%7D%5Cright%5D+%3D+%5Cinfty%2C&bg=ffffff&fg=333333&s=0&c=20201002)
since ![\mathbb{E}[\tau_N(1)]=\infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctau_N%281%29%5D%3D%5Cinfty&bg=ffffff&fg=333333&s=0&c=20201002) . But as in the introduction, these rates are only relevant to laws of large numbers when k grows on a large enough timescale, and we will consider smaller scales of k.
. But as in the introduction, these rates are only relevant to laws of large numbers when k grows on a large enough timescale, and we will consider smaller scales of k.
Timescales of the clock process
We’re going to look for scaling limits of the clock process. The increments are ‘sort of IID’ and ‘sort of heavy-tailed’ (we’ll clarify these sort ofs when we need to) so it wouldn’t be surprising if the scaling limits are Levy processes. The clock process is increasing, so in fact the scaling limits should be subordinators, and it wouldn’t be surprising if under some circumstances they turned out to be stable subordinators.
There is flexibility about how to do the rescaling. From now on, we are working in a 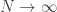 regime. Let’s assume we look at
regime. Let’s assume we look at  steps of the jump chain, where
steps of the jump chain, where  is some divergent sequence. A property of large sums of IID stable distributions with parameter is that the scaling of the value of the sum is comparable to the scale of the largest summand. That is, the partial sum is dominated by its largest summands. Compare with the standard case for non-negative RVs, where for k summands, the sum is
is some divergent sequence. A property of large sums of IID stable distributions with parameter is that the scaling of the value of the sum is comparable to the scale of the largest summand. That is, the partial sum is dominated by its largest summands. Compare with the standard case for non-negative RVs, where for k summands, the sum is  , while the largest summand is
, while the largest summand is 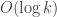 .
.
So to identify the scale of the clock process after  steps of the jump chain, it’s sufficient to identify the scale of its expected largest holding time. All of this is vague at the level of constants, so we choose a divergent sequence
steps of the jump chain, it’s sufficient to identify the scale of its expected largest holding time. All of this is vague at the level of constants, so we choose a divergent sequence  for which
for which
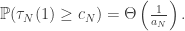
Note 1: this means that the number of holding times among the first which are at least 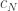 is binomial with
is binomial with 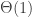 expectation. The fact that is well-approximated by a Poisson distribution will be relevant shortly.
expectation. The fact that is well-approximated by a Poisson distribution will be relevant shortly.
Note 2: because we already insisted that 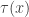 had a slowly-varying tail, this gives control of the
had a slowly-varying tail, this gives control of the  etc as well.
etc as well.
We expect that  , and so we consider scaling limits of the process
, and so we consider scaling limits of the process
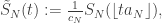
as usual. [Note I am using the opposite convention to VG’s notes, where ~ denotes the unrescaled clock process.]
Scaling limits
We identify two types of scaling limit, depending on whether  or
or  . The former is called an intermediate timescale, while the latter is an extreme timescale. After this long motivation and notational preliminary section, my goal is to explain (partly to myself) why these scaling limits are different.
. The former is called an intermediate timescale, while the latter is an extreme timescale. After this long motivation and notational preliminary section, my goal is to explain (partly to myself) why these scaling limits are different.
First, we state the result for intermediate timescales. Let 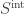 be the stable subordinator with parameter , that is with Levy measure
be the stable subordinator with parameter , that is with Levy measure  . Then
. Then  , in the Skorohod topology. We need to be clear about the sense of convergence, and the role of the random environment. It turns out that if in addition
, in the Skorohod topology. We need to be clear about the sense of convergence, and the role of the random environment. It turns out that if in addition 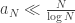 , then this convergence holds for almost all realisations of the random environment. That is, the laws of the processes (with respect to the randomness of the jump chain / holding times etc) converge. When is only
, then this convergence holds for almost all realisations of the random environment. That is, the laws of the processes (with respect to the randomness of the jump chain / holding times etc) converge. When is only 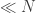 , then the convergence holds in probability with respect to the environment. It took me a while to parse what this means. It means that for large N, the probability that the random environment induces a law of
, then the convergence holds in probability with respect to the environment. It took me a while to parse what this means. It means that for large N, the probability that the random environment induces a law of 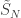 which is far from the law of tends to zero.
which is far from the law of tends to zero.
The exact Levy triple of the limit process is not the important message here, and if that’s unfamiliar, then it isn’t a problem. The point is that you would also get this limiting Levy process if you took the sum process of genuinely IID random variables with the same -tail. And this is not surprising. Since recall that in the intermediate timescale , so during the first  steps of the jump chain, we do not typically visit many sites more than once. Indeed, if
steps of the jump chain, we do not typically visit many sites more than once. Indeed, if 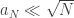 , then this is the birthday problem, and we typically visit no site more than once. However, even in the weaker setting , look at the deepest 1000 sites we visit during the first
, then this is the birthday problem, and we typically visit no site more than once. However, even in the weaker setting , look at the deepest 1000 sites we visit during the first  steps. We can compute that, in expectation, we visit essentially zero of these more than once. But these 1000 sites dominate the clock process at . So from the point of view of the clock process, since we hardly ever visit relevant sites twice, the depths
steps. We can compute that, in expectation, we visit essentially zero of these more than once. But these 1000 sites dominate the clock process at . So from the point of view of the clock process, since we hardly ever visit relevant sites twice, the depths  are essentially independent, and so it’s unsurprising that we get the scaling limit corresponding to IID partial sums.
are essentially independent, and so it’s unsurprising that we get the scaling limit corresponding to IID partial sums.
For extreme timescales, by contrast, this fails. If we take 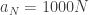 , we expect to visit each site roughly 1000 times, indeed the number of visits to a given site will be approximately
, we expect to visit each site roughly 1000 times, indeed the number of visits to a given site will be approximately  . But it’s still the case that the scaling limit will be dominated by the deepest sites. In particular, at some point on this timescale we will visit the deepest site, and indeed we will visit it multiple times if we look at for large t. So the jumps of any scaling limit are not independent any more unless we condition on all the depths .
. But it’s still the case that the scaling limit will be dominated by the deepest sites. In particular, at some point on this timescale we will visit the deepest site, and indeed we will visit it multiple times if we look at for large t. So the jumps of any scaling limit are not independent any more unless we condition on all the depths .
However, all is not lost, since we can show that the point process of rescaled depths 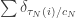 converges to a Poisson random measure on
converges to a Poisson random measure on 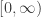 . The candidate for the scaling limit of the clock process is then the subordinator whose Levy measure is this Poisson random measure. This isn’t itself a Levy process, but it is a mixture of Levy processes, reflecting that on extreme timescales the quenched and annealed viewpoints are different since there is enough time to visit the whole landscape.
. The candidate for the scaling limit of the clock process is then the subordinator whose Levy measure is this Poisson random measure. This isn’t itself a Levy process, but it is a mixture of Levy processes, reflecting that on extreme timescales the quenched and annealed viewpoints are different since there is enough time to visit the whole landscape.
Heuristically, the extreme timescale is the entry point for convergence to equilibrium. Indeed, taking 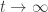 , the number of visits to each of the 1000 top sites converge to their expectation, corresponding to convergence of the clock process to equilibrium, since these holding times continue to dominate the sum. The clock process therefore starts to feel the finiteness of the state space, which introduces dependence between the most relevant holding times, which was not the close on intermediate timescales.
, the number of visits to each of the 1000 top sites converge to their expectation, corresponding to convergence of the clock process to equilibrium, since these holding times continue to dominate the sum. The clock process therefore starts to feel the finiteness of the state space, which introduces dependence between the most relevant holding times, which was not the close on intermediate timescales.
In the next post, I’m going to try and summarise VG’s descriptions of taking this model beyond the mean-field setting, where the range of possibilities becomes much much richer. I’m also going to try and say something and glassy dynamics and ageing, and why the physical motivation justifies considering these particular models and scalings.

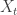 is a subordinator if:
is a subordinator if: , where the hitting time of infinity represents ‘killing’ the subordinator in some sense. If this hitting time is almost surely infinite, we say it is a strict subordinator. There is little to be gained right now from considering anything other than strict subordinators.
, where the hitting time of infinity represents ‘killing’ the subordinator in some sense. If this hitting time is almost surely infinite, we say it is a strict subordinator. There is little to be gained right now from considering anything other than strict subordinators.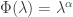 , for some
, for some 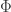 very soon.) Note that checking that the sample paths are increasing requires only that
very soon.) Note that checking that the sample paths are increasing requires only that  almost surely.
almost surely.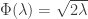 .)
.)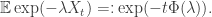
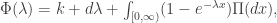
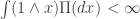 .
.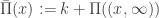 for the tail of the Levy measure is often more useful in this setting.
for the tail of the Levy measure is often more useful in this setting. . As we said above, we do not want to consider the case that X is a step process, so either d>0 or
. As we said above, we do not want to consider the case that X is a step process, so either d>0 or 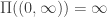 is enough to ensure this.
is enough to ensure this.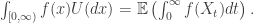
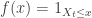 in the above.
in the above.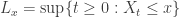 so
so 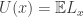 is continuous.
is continuous.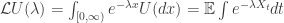
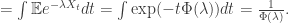
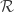 . Formally, given s, we do not always have
. Formally, given s, we do not always have 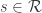 (as the process might jump over s), but we can define
(as the process might jump over s), but we can define  . Then
. Then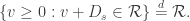
 is some kind of dual to X, since it is increasing, and the regenerative property induces some Markovian properties.
is some kind of dual to X, since it is increasing, and the regenerative property induces some Markovian properties. , in the case of a stable subordinator with
, in the case of a stable subordinator with  is thus independent of t. In this situation, we can derive the generalised arcsine rule for the distribution of
is thus independent of t. In this situation, we can derive the generalised arcsine rule for the distribution of  :
: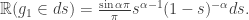
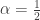 . Then
. Then 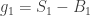 , in the usual notation for the supremum process. Furthermore, we have equality in distribution of the processes (see
, in the usual notation for the supremum process. Furthermore, we have equality in distribution of the processes (see 
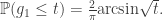
 . For a general Levy process, we have
. For a general Levy process, we have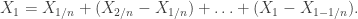

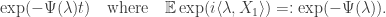
 is called the characteristic exponent. The argument resembles that used for Cauchy’s functional equations, by dealing first with the rationals using stationarity of increments, then lifting to the reals by the (right-)continuity of
is called the characteristic exponent. The argument resembles that used for Cauchy’s functional equations, by dealing first with the rationals using stationarity of increments, then lifting to the reals by the (right-)continuity of
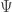 is that it be the characteristic function of an infinitely divisible distribution. This condition is given explicitly by the Levy-Khintchine formula.
is that it be the characteristic function of an infinitely divisible distribution. This condition is given explicitly by the Levy-Khintchine formula.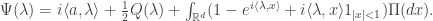
 , Q a quadratic form on
, Q a quadratic form on 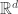 , and
, and 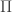 a so-called Levy measure satisfying
a so-called Levy measure satisfying  .
. comes from a drift of
comes from a drift of 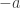 . Note that a deterministic linear function is a (not especially interesting) Levy process.
. Note that a deterministic linear function is a (not especially interesting) Levy process. comes from a Brownian part
comes from a Brownian part  .
. . The restriction on the Levy measure near 0 ensures that the sum of the squares all jumps up some finite time converges absolutely.
. The restriction on the Levy measure near 0 ensures that the sum of the squares all jumps up some finite time converges absolutely. gives the intensity of a standard compound Poisson process. The jumps are well-spaced, and so it is a relatively simple calculation to see that the characteristic function is
gives the intensity of a standard compound Poisson process. The jumps are well-spaced, and so it is a relatively simple calculation to see that the characteristic function is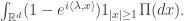
 gives infinitely many hits in finite time, so if the expectation of this measure is not 0, we explode immediately. We compensate by drifting away from this at rate
gives infinitely many hits in finite time, so if the expectation of this measure is not 0, we explode immediately. We compensate by drifting away from this at rate
 then take a limit, but this at least explains where all the terms come from. Linearity allows us to interchange integrals and inner products, to get the term
then take a limit, but this at least explains where all the terms come from. Linearity allows us to interchange integrals and inner products, to get the term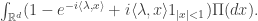
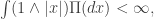
 , so can be incorporated with the drift term at the beginning of the Levy-Khintchine expression. If not, then there are some
, so can be incorporated with the drift term at the beginning of the Levy-Khintchine expression. If not, then there are some 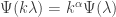 , which induces the rescaling-invariance property:
, which induces the rescaling-invariance property:  . The distribution of each
. The distribution of each  after a natural rescaling is distributed as N(0,1). As a starting point for investigating similar results for a more general class of underlying distributions, it is worth considering what properties we might require of a distribution if it is to appear as a limit in distribution of sums of IID RVs, rescaled if necessary.
after a natural rescaling is distributed as N(0,1). As a starting point for investigating similar results for a more general class of underlying distributions, it is worth considering what properties we might require of a distribution if it is to appear as a limit in distribution of sums of IID RVs, rescaled if necessary. , with the initial sums
, with the initial sums 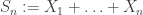 . Then we say
. Then we say  is stable in the broad sense if
is stable in the broad sense if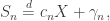
 for every n. If in fact
for every n. If in fact  then we say
then we say 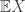 exists and is 0, then so are all the
exists and is 0, then so are all the 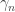 s.
s. for some
for some  .
.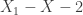 (independent copies naturally!). The behaviour of
(independent copies naturally!). The behaviour of  is also preserved. Now we can work with an underlying distribution that is symmetric about 0, rather than merely centred. The deduction that
is also preserved. Now we can work with an underlying distribution that is symmetric about 0, rather than merely centred. The deduction that 
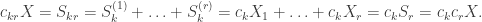
 , and express
, and express
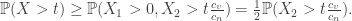 (*)
(*) in the above, and using that X is symmetric, we can obtain an upper bound
in the above, and using that X is symmetric, we can obtain an upper bound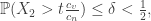
 if we take
if we take  large enough. But since
large enough. But since
 ), this implies that
), this implies that  cannot be very close to 0. In other words,
cannot be very close to 0. In other words,  is bounded above. This is in fact regularity enough to deduce that
is bounded above. This is in fact regularity enough to deduce that  . Note that this equality case
. Note that this equality case 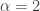 corresponds exactly to the
corresponds exactly to the 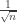 scaling we saw for the normal distribution, in the context of the CLT. This motivates the proof. If
scaling we saw for the normal distribution, in the context of the CLT. This motivates the proof. If  , we will show that the variance of X is finite, so CLT applies. This gives some control over
, we will show that the variance of X is finite, so CLT applies. This gives some control over  limit, which is plenty to ensure a contradiction.
limit, which is plenty to ensure a contradiction.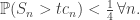
 s is
s is  and that the sum of the rest is non-negative. This has, by independence, exactly half the probability of the event demanding just that the maximum be bounded below, and furthermore is contained within the event with probability
and that the sum of the rest is non-negative. This has, by independence, exactly half the probability of the event demanding just that the maximum be bounded below, and furthermore is contained within the event with probability  shown above. So if we set
shown above. So if we set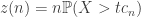
![\frac14>\mathbb{P}(S_n>tc_n)\geq\frac12\mathbb{P}(\max X_i>tc_n)=\frac12[1-(1-\frac{z}{n})^n]](https://s0.wp.com/latex.php?latex=%5Cfrac14%3E%5Cmathbb%7BP%7D%28S_n%3Etc_n%29%5Cgeq%5Cfrac12%5Cmathbb%7BP%7D%28%5Cmax+X_i%3Etc_n%29%3D%5Cfrac12%5B1-%281-%5Cfrac%7Bz%7D%7Bn%7D%29%5En%5D&bg=ffffff&fg=333333&s=0&c=20201002)

 is bounded as
is bounded as  varies. Rescaling suitably, this gives that
varies. Rescaling suitably, this gives that
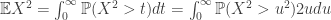


 is not hugely important, as a broadly stable distribution is in the domain of attraction of the corresponding strictly stable distribution.
is not hugely important, as a broadly stable distribution is in the domain of attraction of the corresponding strictly stable distribution.