
One of the fundamental objects in classical probability theory is the Galton-Watson branching process. This is defined to be a model for the growth of a population, where each individual in a generation gives birth to some number (possibly zero) of offspring, who form the next generation. Crucially, the numbers of offspring of the individuals are IID, with the same distribution both within generations and between generations.
There are several ways one might generalise this, such as non-IID offspring distributions, or pairs of individuals producing some number of offspring, but here we consider the situation where each individual has some type, and different types have different offspring distributions. Note that if there are K types, say, then the offspring distributions should now be supported on 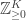

The first question to address is one of survival. Recall that if we want to know whether a standard Galton-Watson process has positive probability of having infinite size, that is never going extinct, we only need to know the expectation of the offspring distribution. If this is less than 1, then the process is subcritical and is almost surely finite. If it is greater than 1, then it is supercritical and survives with positive probability. If the expectation is exactly 1 (and the variance is finite) then the process is critical and although it is still almost surely finite, the overall population size has a power-law tail, and hence (or otherwise) the expected population size is infinite.
We would like a similar result for the multitype process, saying that we do not need to know everything about the distribution to decide what the survival probability should be.
The first thing to address is why we can’t just reduce the multitype change to the monotype setting. It’s easiest to assume that we know the type of the root in the multitype tree. The case where the type of the root is random can be reconstructed later. Anyway, suppose now that we want to know the offspring distribution of a vertex in the m-th generation. To decide this, we need to know the probability that this vertex has a given type, say type j. To calculate this, we need to work out all the type possibilities for the first m generations, and their probabilities, which may well include lots of complicated size-biasing. Certainly it is not easy, and there’s no reason why these offspring distributions should be IID. The best we can say is that they should probably be exchangeable within each generation.
Obviously if the offspring distribution does not depend on the parent’s type, then we have a standard Galton-Watson tree with types assigned in an IID manner to the realisation. If the types are symmetric (for example if M, to be defined, is invariant under permuting the indices) then life gets much easier. In general, however, it will be more complicated than this.
We can however think about how to decide on survival probability. We consider the expected number of offspring, allowing both the type of the parent and the type of the child to vary. So define 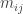

One generalisation is to consider a Galton-Watson forest started from some positive number of roots of various types. Suppose we have a vector 

Let 
So in fact the total number of descendents at generation n grows like 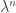
It’s a result (eg. [3]) that the height profile of a depth-first search on a standard Galton-Watson tree converges to Brownian Motion. Another way to phrase this is that a GW tree conditioned to have some size N has the Brownian Continuum Random Tree as a scaling limit as N grows to infinity. Miermont [4] proves that this result holds for the multitype tree as well. In the remainder of this post I want to discuss one idea along the way to the proof, and one application.
I said initially that there wasn’t a trivial reduction of a multitype process to a monotype process. There is however a non-trivial embedding of a monotype process in a multitype process. Consider all the vertices of type 1, and all the paths between such vertices. Then draw a new tree consisting of just the type 1 vertices. Two of these are joined by an edge if there is no other type 1 vertex on the unique path between them in the original tree. If that definition is confusing, think of the most sensible way to construct a tree on the type 1 vertices from the original, and you’ve probably chosen this definition.
There are two important things about this new tree. 1) It is a Galton-Watson tree, and 2) if the original tree is critical, then this reduced tree is also critical. Proving 1) is heavily dependent on exactly what definitions one takes for both the multitype branching mechanism and the standard G-W mechanism. Essentially, at a type 1 vertex, the number of type 1 descendents is not dependent on anything that happened at previous generations, nor in other branches of the original tree. This gives IID offspring distributions once it is formalised. As for criticality, we note that by the matrix argument given before, under the irreducibility condition discussed, the expectation of the total population size is infinite iff the expected number of type 1 vertices is also infinite. Since the proportion of type 1 vertices is given by the first element of the left eigenvector, which is positive, we can make a further argument that the number of type 1 vertices has a power-law tail iff the total population size also has a power-law tail.
I want to end by explaining why I was thinking about this model at all. In many previous posts I’ve discussed the forest fire model, where occasionally all the edges in some large component are deleted, and the component becomes a set of singletons again. We are interested in the local limit. That is, what do the large components look like from the point of view of a single vertex in the component? If we were able to prove that the large components have BCRT as the scaling limit, this would answer this question.
This holds for the original random graph process. There are two sensible ways to motivate this. Firstly, given that a component is a tree (which it is with high probability if its size is O(1) ), its distribution is that of the uniform tree, and it is known that this has BCRT as a scaling limit [1]. Alternatively, we know that the components have a Poisson Galton-Watson process as a local limit by the same argument used to calculate the increments of the exploration process. So we have an alternative description of the BCRT appearing: the scaling limit of G-W trees conditioned on their size.
Regarding the forest fires, if we stop the process at some time T>1, we know that some vertices have been burned several times and some vertices have never received an edge. What is clear though is that if we specify the age of each vertex, that is, how long has elapsed since it was last burned; conditional on this, we have an inhomogeneous random graph. Note that if we have two vertices of ages s and t, then the probability that there is an edge between them is 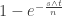
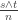
So in conclusion, we have almost all the ingredients towards proving the result we want, that forest fire components have BCRT scaling limit. The only outstanding matter is that the Miermont result deals with a finite number of types, whereas obviously in the setting where we parameterise by age, the set of types is continuous. In other words, I’m working hard!
References
[1] Aldous – The Continuum Random Tree III
[2] Bollobas, Janson, Riordan – The phase transition in inhomogeneous random graphs
[3] Le Gall – Random Trees and Applications
[4] Miermont – Invariance principles for spatial multitype Galton-Watson trees
Related articles
- Graph Theory Basics (explanationsfortime.wordpress.com)
- The Power Method (lucatrevisan.wordpress.com)
- New approach to vertex connectivity could maximize networks’ bandwidth (rdmag.com)
- Intuitive Guide to Principal Component Analysis (georgemdallas.wordpress.com)

 . These offspring then perform one move according to transition matrix P. Note that if you want the system to carry the appearance of having no death, then taking the support of the offspring distribution to be {1,2,3,…} achieves precisely this. The properties we consider will not be very interesting unless G is infinite, so assume that from now on.
. These offspring then perform one move according to transition matrix P. Note that if you want the system to carry the appearance of having no death, then taking the support of the offspring distribution to be {1,2,3,…} achieves precisely this. The properties we consider will not be very interesting unless G is infinite, so assume that from now on.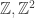 , but these are about as ‘small’ as an infinite graph can be. An idea might be that if the number of sites some distance away from where we start grows rapidly as the distance grows, then there isn’t enough ‘pull’ back to visit the sites near where we start infinitely often. Extending this argument, it is easier for a BRW to be recurrent, as we have the option to make the branching rate large, which means that there are lots of particles at large times, hence more possibility for visiting everywhere. Note that if the offspring distribution is subcritical, we don’t stand a chance of having interesting properties. If we ignore the random walk part, we just have a subcritical Galton-Watson process, which dies out almost surely.
, but these are about as ‘small’ as an infinite graph can be. An idea might be that if the number of sites some distance away from where we start grows rapidly as the distance grows, then there isn’t enough ‘pull’ back to visit the sites near where we start infinitely often. Extending this argument, it is easier for a BRW to be recurrent, as we have the option to make the branching rate large, which means that there are lots of particles at large times, hence more possibility for visiting everywhere. Note that if the offspring distribution is subcritical, we don’t stand a chance of having interesting properties. If we ignore the random walk part, we just have a subcritical Galton-Watson process, which dies out almost surely.

 . Note that by considering the sum of such terms, if simple random walk on G is recurrent, then
. Note that by considering the sum of such terms, if simple random walk on G is recurrent, then  , but the converse does not hold. (Consider SRW on
, but the converse does not hold. (Consider SRW on 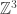 for example.)
for example.) is a class property. In particular, for a connected graph, the value of
is a class property. In particular, for a connected graph, the value of 
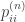 decays like
decays like 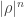 where
where  , then if
, then if 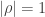 , we must have
, we must have 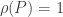 . We can extend this property to say that a graph is amenable if SRW on it is amenable.
. We can extend this property to say that a graph is amenable if SRW on it is amenable.
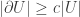 . (Note that finiteness of U is important – we would not expect results like this to hold for very large subsets.)
. (Note that finiteness of U is important – we would not expect results like this to hold for very large subsets.) is amenable in our original sense. This technical and important result links the two definitions.
is amenable in our original sense. This technical and important result links the two definitions. . So the probability that there is a particle back at the origin at this time is (crudely transferring from expectation to probability)
. So the probability that there is a particle back at the origin at this time is (crudely transferring from expectation to probability)  . We can conclude that the chain is recurrent if
. We can conclude that the chain is recurrent if 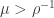 and transient if
and transient if  . This result is due to Benjamini and Peres.
. This result is due to Benjamini and Peres.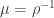 is called, unsurprisingly, critical BRW. It was proved in ’06 by Gantert and Muller that, in fact, all critical BRWs are transient too. This must exclude the amenable case, as we could think of SRW on
is called, unsurprisingly, critical BRW. It was proved in ’06 by Gantert and Muller that, in fact, all critical BRWs are transient too. This must exclude the amenable case, as we could think of SRW on  as a critical BRW by taking the branching distribution to be identically one, as the spectral radius is also 1.
as a critical BRW by taking the branching distribution to be identically one, as the spectral radius is also 1.
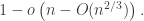
![O\left([n-O(n^{2/3})]^{2/3}\right)=O(n^{2/3})](https://s0.wp.com/latex.php?latex=O%5Cleft%28%5Bn-O%28n%5E%7B2%2F3%7D%29%5D%5E%7B2%2F3%7D%5Cright%29%3DO%28n%5E%7B2%2F3%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) .
. so we should look at the exploration process at time
so we should look at the exploration process at time 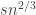 . The drift of the exploration process is given by the expectation of a binomial random variable minus one (since we remove the current vertex from the stack as we finish exploring it). This is given by
. The drift of the exploration process is given by the expectation of a binomial random variable minus one (since we remove the current vertex from the stack as we finish exploring it). This is given by![\mathbb{E}=\left[n-sn^{2/3}\right]\cdot \frac{1}{n}-1=-sn^{-1/3}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%3D%5Cleft%5Bn-sn%5E%7B2%2F3%7D%5Cright%5D%5Ccdot+%5Cfrac%7B1%7D%7Bn%7D-1%3D-sn%5E%7B-1%2F3%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
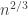 time-steps will accordingly by
time-steps will accordingly by  . So, if we rescale time by
. So, if we rescale time by 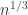 , we should get a nice stochastic process. Specifically, if Z is the exploration process, then we obtain:
, we should get a nice stochastic process. Specifically, if Z is the exploration process, then we obtain:
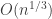 at all times, and so in particular will always be an order of magnitude smaller than the number of vertices already considered. Therefore, they won’t affect this drift term, though this must be accounted for in any formal proof of convergence. On the subject of which, the mode of convergence is, unsurprisingly, weak convergence uniformly on compact sets. That is, for any fixed S, the convergence holds weakly on the random functions up to time
at all times, and so in particular will always be an order of magnitude smaller than the number of vertices already considered. Therefore, they won’t affect this drift term, though this must be accounted for in any formal proof of convergence. On the subject of which, the mode of convergence is, unsurprisingly, weak convergence uniformly on compact sets. That is, for any fixed S, the convergence holds weakly on the random functions up to time  , for any
, for any 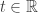 , the same argument holds. Now the drift at time s is t-s, though everything else still holds.
, the same argument holds. Now the drift at time s is t-s, though everything else still holds.








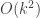 possible edges between k vertices forming a component, and adding any of precisely these will create a cycle.
possible edges between k vertices forming a component, and adding any of precisely these will create a cycle.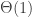 there is a component of size
there is a component of size 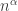 for some
for some  . Then such a component makes a contribution to the expected change in the number of isolated vertices of
. Then such a component makes a contribution to the expected change in the number of isolated vertices of (*)
(*)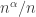 . Note that this is under a slightly odd definition of an edge, that allows loops. Basically, I don’t want to have lots of correction terms involving
. Note that this is under a slightly odd definition of an edge, that allows loops. Basically, I don’t want to have lots of correction terms involving  floating around. However, it would make no difference to the orders of magnitude if we to do it with these.
floating around. However, it would make no difference to the orders of magnitude if we to do it with these. new components. It is possible to argue via isolated vertices here too, but the estimates are harder, or at least less present in the literature.
new components. It is possible to argue via isolated vertices here too, but the estimates are harder, or at least less present in the literature.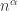 .
. such components for any
such components for any  .
. , and over a large enough time these make a greater contribution to the average gain in isolated vertices.
, and over a large enough time these make a greater contribution to the average gain in isolated vertices.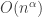 .
. as the same. This is a problem, as when I say the expectation is
as the same. This is a problem, as when I say the expectation is  . This means it could be
. This means it could be  or
or  . Of course, there is a massive difference between these, since a branching process grows expectationally!
. Of course, there is a massive difference between these, since a branching process grows expectationally!