
This post is aimed at secondary-school students pitched roughly at the level of the British Mathematical Olympiad. It is ostensibly about a certain class of number theory problems, but the main underlying mathematical principle is broader than this. The post is based on an in-person session I have given to students and at teachers’ conferences a few times over the past five years, but I’ve chosen to write it up at this moment because of the connection to Problem 4 on the most recent BMO1 paper, which we discuss later in the post.
Prologue
Alice and Bob make the following statements:
- Alice: all prime numbers are odd.
- Bob: we can’t say anything about whether prime numbers are odd or even.
These are different types of statement, one objective, one more subjective; but both are wrong. Alice is wrong because 2 is a prime, and 2 is of course even. Bob is wrong because while Alice is wrong, and the alternative statement “all prime numbers are even” is even more wrong1, there are plenty of possible statements that are true and useful, including
- Cleo: all prime numbers are odd except 2.
and weaker versions (that may be more relevant in other contexts) like “all primes greater than 
The characters now turn their attention to another family of integers, the square numbers 

- Alice: no square numbers are prime.
- Bob: I agree.
- Alice: most square numbers are not sixth powers.
- Bob: hang on, but infinitely many square numbers are sixth powers?
The difficulty in the second statement is what does most mean in this context? The square of an integer n is a sixth power if and only if n is a cube, and so Alice’s statement is equivalent to the statement “most positive integers are not cubes”, which is intuitively reasonable, but would require more clarification than the analogous statement “most primes are odd”. Is it not relevant, for example, that 1/4 of the first eight positive integers are in fact cubes?
It is not impossible to formalise this notion of most in a reasonable way to permit the two statements above2.
But the bulk of this post will discuss situations that extend the first of these conversations, ie when it’s not true to say “all element of X have property Y”, but where it’s nonetheless possible to make a useful intermediate statement.
Warmup problems
I hope most readers know how to solve an equation such as

and indeed learning how to solve such equations forms a important milestone in mathematical education as the first example of various principles of algebra. When such equations are still novel, teachers would be advised to avoid examples such as

for which the answers are, respectively, ‘no solutions’ and ‘every x satisfies this’. While they are perfectly valid equations, it means something slightly different to solve them, since the answer set has different structure and, more importantly, the method is different since it doesn’t consist of a sequence of a manipulations leading directly to the required conclusion 
However, I mention this in passing to clarify that even in the simplest possible family of equations (probably encountered somewhere between ages 9 and 13) we are mindful that not all equations have unique solutions.
I’ve adapted a problem from the American competition AIME:
Find all integers 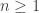

One could start by writing 

which is never a prime, since 
So at a meta-level, comparing with the other problem in this section, this one also begins with reversible algebraic manipulations, but does not end with a direct reduction to ![n = [...]](https://s0.wp.com/latex.php?latex=n+%3D+%5B...%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Finally, we remark that the original version of the AIME problem was
Prove that for all integers 
The same algebraic reduction as (*) resolves the original version without an extra step concerning primes.
To be, or not to be, a perfect square
The rest of this article will focus entirely on problems of the form: find all positive integers n such that […] is a perfect square.
As setup, we’ll always consider a function f(n), and the sequence f(1),f(2),f(3),… and the question, comment on the set of n is f(n) a square? In particular, this is a more open-ended question than for which n is f(n) a square, which requires a more exact answer. We’ll aim for one of the following possible answers:
- f(n) is always a square;
- f(n) is a square for infinitely many n;
- f(n) is a square for only finitely many n;
- f(n) is never a square.
Clearly this is not an exhaustive list of possible descriptions3 of the set under discussion, but it will do for now. The difference between the second and the third bullet point can be thought of as: “are there arbitrarily large values of n for which f(n) is a square?”
As some examples:
is never a square, because the only squares that differ by 1 are {0,1} which aren’t attainable when
is a square for only finitely many n, because the only squares that differ by 3 are {1,4}.
Exercises to try yourself
,
- or, now with p ranging over the set of prime numbers:
.
Some discussion of some of these follows later to avoid spoilers.
BMO1 2023, Problem 4

This problem does not have exactly the same structure as the previous exercise. A solution will follow shortly, but before starting, [spoilers] I want to emphasise that the main part of the solution involves framing this problem exactly as in the exercise above.
- We will establish that there are only finitely many n such that
is a square, using a classical number theory argument.
- In doing so, we will eliminate all integers n that are at least some threshold value K from consideration (which we think of as “n large”, even though in this case it isn’t so large).
- The actual set of solutions comes from check the remaining “small” values of n.
- The point to emphasise is that while this third bullet is definitely an important component of a successful solution (and does feel closest to actually addressing the “find all” aspect of the problem statement), it is not really the key step, since checking a small number of possibilities is fundamentally much more straightforward than an argument to eliminate the other infinitely-many integers.
This overall structure is very common when solving Diophantine equations involving integers, even if the exact statement isn’t “find all n such that […] is a perfect square”.
Anyway, to the solution of this problem. As in many problems of this difficulty in this number theory, it’s really useful to aim to factorise and analyse the factors, remembering that they are integers! In this case, writing 


Here the two factors are (k-1) and (k+1). We know nothing about k, so we know nothing intrinsic about these factors, except that they differ by 2. But now when we consider that their product is 
- (k-1) and (k+1) differ by two, and so have the same parity5. Then
- But more than this, one factor will be a multiple of 4, while the other will not be. So all the powers of 2 within
- The idea is that
is generally much larger than n, and so this will force one of the factors to be much larger than the other factor, which is not permitted. (Recall that the factors differ by 2.)
So formally, we might write that 




and we now have exactly the language to describe the truth of this inequality! It is only true for finitely many positive integers n. There are a number of ways to prove this, but it is important that we do provide a lower bound. One possibility is to check that (*) holds for n=5, and then prove (*) for all 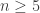
At this point, we have shown that 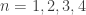

To link this to the background, note that this final procedure of “finding all the solutions” really had nothing in common structure-wise with “solving 
Comments on exercises
is a square for infinitely many n, while
is never a square, for reasons that are often framed in the language of quadratic residues.
is a square only when n=3, which can be seen via a similar argument to the argument above for the BMO problem. Meanwhile
is never a square, which can also be checked using quadratic residues.
is a square for infinitely many n (specifically, when
), while
is only a square for finitely many n, because when n is large, we have
. This style of argument is sometimes called square-sandwiching, although it can of course be deployed in contexts other than squares. Problems that turn on this method have appeared in BMO surprisingly often in the past 15 years. For this particular example, note that one does have to check a handful of values to confirm it is for finitely many but at least one n (rather than for no n).
Footnotes
- of course, writing even more wrong is in itself making a nuanced comment about the parity of the prime numbers. ↩︎
- given a set
, a natural formalisation of the notion that ‘most integers are not in A’ would be that
In other words, the proportion of elements of A amongst the first n integers vanishes as
. This is certainly true when A is the set of cubes.
There are many sets for which this limit does not exist, including quite natural sets like the integers whose decimal representation starts with a 1, and so a full treatment of this notion of asymptotic density would require more than a footnote. ↩︎ - in particular, we might wish to draw a distinction between f(n) is a square for infinitely many n and the stronger statement f(n) is a square for all-but-finitely many n, and in some applications that difference is crucial. ↩︎
- A common error is to make some reasonable-sounding assumption about how the factors of
are split between (k-1) and (k+1), for example by assuming that
and
because this is visually a natural way to pair them up. ↩︎
- parity refers to whether a number is odd or even. ↩︎


 in terms of
in terms of  ) and noticing that it can be converted into a recursion for the increments
) and noticing that it can be converted into a recursion for the increments  in terms of
in terms of  . What makes this clever is that it works nicely but differently in the two cases. Note that because the conclusion involves ‘consecutive integers’ (ie where the increment is equal to 1), this is a clue that this is a good line of attack.
. What makes this clever is that it works nicely but differently in the two cases. Note that because the conclusion involves ‘consecutive integers’ (ie where the increment is equal to 1), this is a clue that this is a good line of attack. or
or  .
. or to the fact that the sequence is integer-valued, but now one can bring that back into focus. If
or to the fact that the sequence is integer-valued, but now one can bring that back into focus. If  , this means that
, this means that  for some
for some  . But
. But 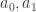 are integers, and so the only option is
are integers, and so the only option is  .
.
 or
or  if there’s a clear geometrical meaning to those quantities.
if there’s a clear geometrical meaning to those quantities. . This, combined with ABX being isosceles, shows that ABXZ is a kite, and so BZ is perpendicular to AX, which is the same line as AC. (*)
. This, combined with ABX being isosceles, shows that ABXZ is a kite, and so BZ is perpendicular to AX, which is the same line as AC. (*)
 , since both are ‘180 minus red minus green’. Observe that because we’ve already handled a reduction to the problem at (*), this diagram didn’t actually need to have line BZ included, even though it’s part of the original conclusion!
, since both are ‘180 minus red minus green’. Observe that because we’ve already handled a reduction to the problem at (*), this diagram didn’t actually need to have line BZ included, even though it’s part of the original conclusion!
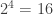 possibilities, that each group of four indexes at least one fault, which proves that the minimum is 250 as required.
possibilities, that each group of four indexes at least one fault, which proves that the minimum is 250 as required.

 is small enough, the 2k-gon is convex, and that the obtuse angle in the triangle is greater than the total obtuse angle at the vertices of the k-gon without formally justifying this with algebra.
is small enough, the 2k-gon is convex, and that the obtuse angle in the triangle is greater than the total obtuse angle at the vertices of the k-gon without formally justifying this with algebra. are Borel-measurable.
are Borel-measurable. for some general measure space
for some general measure space  .
.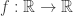 , where the integral
, where the integral  has to be defined as a limit of integrals over finite ranges.
has to be defined as a limit of integrals over finite ranges. , where
, where 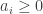 are non-negative coefficients, and
are non-negative coefficients, and  are measurable sets. Note that the sum is finite.
are measurable sets. Note that the sum is finite. is defined to be
is defined to be  . This matches our intuition if we are thinking of functions
. This matches our intuition if we are thinking of functions ![f=\sum_{n\ge 1} \mathbf{1}_{[-n,n]}](https://s0.wp.com/latex.php?latex=f%3D%5Csum_%7Bn%5Cge+1%7D+%5Cmathbf%7B1%7D_%7B%5B-n%2Cn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) which is infinite everywhere [1]. This will be a recurring theme of this post: an optimal definition only takes a limit when it’s certain that the limit exists.
which is infinite everywhere [1]. This will be a recurring theme of this post: an optimal definition only takes a limit when it’s certain that the limit exists. ) and various other unsurprising-but-important results.
) and various other unsurprising-but-important results. taking only non-negative values via a limit of simple functions. Specifically
taking only non-negative values via a limit of simple functions. Specifically (*)
(*) as the limit of the integrals of a specific sequence of simple functions
as the limit of the integrals of a specific sequence of simple functions 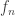 approximating
approximating 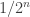 ), the more abstract definition (*) turns out to be more useful in proofs [2].
), the more abstract definition (*) turns out to be more useful in proofs [2]. a.e., then
a.e., then ![\int_E f_n\,d\mu\uparrow \int_E f\,d\mu \in[0,\infty]](https://s0.wp.com/latex.php?latex=%5Cint_E+f_n%5C%2Cd%5Cmu%5Cuparrow+%5Cint_E+f%5C%2Cd%5Cmu+%5Cin%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) . As a bonus, we immediately recover that the limit of the integrals of the ’rounding-down approximations’ in the previous paragraph is the limit of the original function.
. As a bonus, we immediately recover that the limit of the integrals of the ’rounding-down approximations’ in the previous paragraph is the limit of the original function. of
of  , provided that at least one of the RHS integrals is finite. The point is that it’s well-defined to write
, provided that at least one of the RHS integrals is finite. The point is that it’s well-defined to write  or
or  , but it’s not well-defined to study
, but it’s not well-defined to study 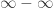 .
. are then not integrable over
are then not integrable over  case, but the issues mostly generalise).
case, but the issues mostly generalise). as a limit of intervals over finite range. Leaving aside the question of whether this is possible for more general spaces (see [3]), we already have issues with this approach over
as a limit of intervals over finite range. Leaving aside the question of whether this is possible for more general spaces (see [3]), we already have issues with this approach over  , we have truncated results like
, we have truncated results like
![\mathbb{R}=\bigcup_{n} [-n,n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%3D%5Cbigcup_%7Bn%7D+%5B-n%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) would ‘define’ the integral of f over
would ‘define’ the integral of f over ![\mathbb{R}=\bigcup_{n} [-n,2n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%3D%5Cbigcup_%7Bn%7D+%5B-n%2C2n%5D&bg=ffffff&fg=333333&s=0&c=20201002) would give a different answer. So this certainly wouldn’t work as a general definition.
would give a different answer. So this certainly wouldn’t work as a general definition. , with the same restriction on taking
, with the same restriction on taking 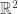 , there is no easy analogue to this split.
, there is no easy analogue to this split. ) then it just can’t be bounded below by a function which only takes finitely many values.
) then it just can’t be bounded below by a function which only takes finitely many values. , this is even worse than the situation discussed in footnote [1] already. At this point we would already have simple functions for which the integral isn’t defined, such as taking
, this is even worse than the situation discussed in footnote [1] already. At this point we would already have simple functions for which the integral isn’t defined, such as taking 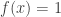 for
for  and
and  for
for 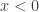 . It’s not going to work very well to study the supremum of a set, some of whose values are not defined!
. It’s not going to work very well to study the supremum of a set, some of whose values are not defined! , and
, and  a.e. That is,
a.e. That is, 
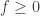 and an infimum over the range where
and an infimum over the range where 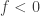 , then you are actually back to the original definition of the general Lebesgue integral!
, then you are actually back to the original definition of the general Lebesgue integral! , notwithstanding some of the issues we mentioned earlier about committing to an specific approximating sequence.
, notwithstanding some of the issues we mentioned earlier about committing to an specific approximating sequence. are not monotone in n, there is no guarantee that this limit exists. And, indeed, we can construct examples of
are not monotone in n, there is no guarantee that this limit exists. And, indeed, we can construct examples of  , and the function
, and the function  . So then the approximation
. So then the approximation  , and thus
, and thus  , which is 1 when n is odd, and 0 when n is even.
, which is 1 when n is odd, and 0 when n is even. is undefined, which might seem equally disappointing, but in reality is more clear than ending up in a situation where you get different limits depending on whether you round down to the nearest multiple of
is undefined, which might seem equally disappointing, but in reality is more clear than ending up in a situation where you get different limits depending on whether you round down to the nearest multiple of  versus rounding down to the nearest multiple of
versus rounding down to the nearest multiple of  .
. for
for  , then we immediately run into problems when trying to prove that
, then we immediately run into problems when trying to prove that  , as the rounding down operation doesn’t commute with addition.
, as the rounding down operation doesn’t commute with addition.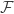 provides a set of events
provides a set of events  for which it is meaningful and consistent to define a probability measure. This is extremely uncontroversial in the setting where the set of outcomes
for which it is meaningful and consistent to define a probability measure. This is extremely uncontroversial in the setting where the set of outcomes  is finite, but thornier in the setting where
is finite, but thornier in the setting where 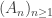 is a sequence of events in
is a sequence of events in  .
.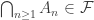 also. It is uncontroversial to note that
also. It is uncontroversial to note that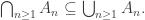
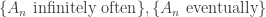 are that they lie between the intersection and the union in terms of containment.
are that they lie between the intersection and the union in terms of containment. must hold for every n, and so the event
must hold for every n, and so the event  .
.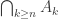 holds, so the event
holds, so the event  .
.
 holds for all except finitely many n, then it holds for infinitely many n. The right-most says that if it holds infinitely often, then it holds at least once. For the left-most containment, note that
holds for all except finitely many n, then it holds for infinitely many n. The right-most says that if it holds infinitely often, then it holds at least once. For the left-most containment, note that 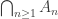 is literally the same as the n=1 case of
is literally the same as the n=1 case of 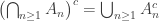 and
and  . Versions of these apply to eventually/i.o. also. In particular
. Versions of these apply to eventually/i.o. also. In particular
 .
. is this is more convenient. As we will see, it makes sense to focus on whichever of
is this is more convenient. As we will see, it makes sense to focus on whichever of  has vanishing probabilities as
has vanishing probabilities as 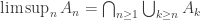 , and
, and 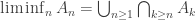 . I am happy to admit I get these confused with non-vanishing probability, and prefer to stick to eventually/i.o. or the full union/intersection statements for safety!
. I am happy to admit I get these confused with non-vanishing probability, and prefer to stick to eventually/i.o. or the full union/intersection statements for safety! almost surely holds, or almost surely doesn’t hold. We’ll state them now:
almost surely holds, or almost surely doesn’t hold. We’ll state them now: , then
, then 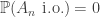 .
. and the events
and the events 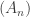 are independent, then
are independent, then 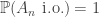 .
. for every $n$, we have
for every $n$, we have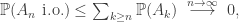
 .
. which counts how many events
which counts how many events 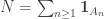 . Then
. Then 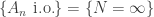 , and the given condition is equivalent to
, and the given condition is equivalent to ![\mathbb{E}[N]<\infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BN%5D%3C%5Cinfty&bg=ffffff&fg=333333&s=0&c=20201002) , which certainly implies
, which certainly implies 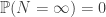 . Indeed, it’s reasonable to think of BC1 as a first-moment result, with BC2 as (sort of) a second-moment result, and this is reflected in the comparative complexity of the two proofs.
. Indeed, it’s reasonable to think of BC1 as a first-moment result, with BC2 as (sort of) a second-moment result, and this is reflected in the comparative complexity of the two proofs. . To do this, we study the intersections of the complements, whose probabilities are tractable using independence:
. To do this, we study the intersections of the complements, whose probabilities are tractable using independence:
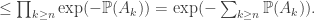
 for each n, and so we obtain
for each n, and so we obtain
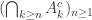 is an increasing sequence of events, so taking a union over n is particularly natural. Precisely, by continuity of measure, we have
is an increasing sequence of events, so taking a union over n is particularly natural. Precisely, by continuity of measure, we have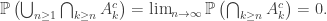
 . For example, with
. For example, with ![U\sim \mathrm{Unif}[0,1]](https://s0.wp.com/latex.php?latex=U%5Csim+%5Cmathrm%7BUnif%7D%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , consider
, consider 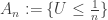 , for which
, for which  , whose sum diverges, while clearly
, whose sum diverges, while clearly  .
. where
where  is a permutation of
is a permutation of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . We construct these iteratively as follows:
. We construct these iteratively as follows: 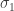 is the identity (ie the only permutation of one element!); then for each
is the identity (ie the only permutation of one element!); then for each  , define
, define 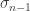 by inserting element
by inserting element  at a uniformly-chosen position in
at a uniformly-chosen position in 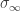 on
on  . A necessary condition for this is that the first element
. A necessary condition for this is that the first element  is eventually constant. But in fact the events
is eventually constant. But in fact the events 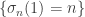 are independent, and each occurs with probability
are independent, and each occurs with probability  , and so
, and so
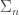 , permutations of
, permutations of 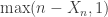 where
where 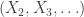 are IID
are IID 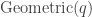 random variables. (The truncation is just to prevent pathologies like trying to add the new entry in ‘place -6’.) Then
random variables. (The truncation is just to prevent pathologies like trying to add the new entry in ‘place -6’.) Then
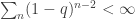 , BC1 shows that the first element
, BC1 shows that the first element  changes only finitely often. A similar argument applies for the second element, and the third element, and so on. Consequently, almost surely we have a well-defined pointwise limit permutation
changes only finitely often. A similar argument applies for the second element, and the third element, and so on. Consequently, almost surely we have a well-defined pointwise limit permutation  are close if
are close if 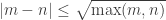 .
.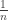 . Then, whenever we have two integers
. Then, whenever we have two integers 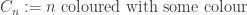 . Using BC2, we know that almost surely, infinitely many are coloured with some colour, and it seems implausible that many would be close. However, the events
. Using BC2, we know that almost surely, infinitely many are coloured with some colour, and it seems implausible that many would be close. However, the events 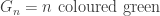 are not independent, so one cannot apply BC2 directly to these. However, we can study instead
are not independent, so one cannot apply BC2 directly to these. However, we can study instead 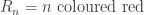 . We can bound these probabilities as
. We can bound these probabilities as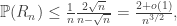
 . Then, since
. Then, since 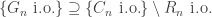 , we obtain
, we obtain  , as required.
, as required.

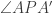 . So I considering intersecting L with the lines
. So I considering intersecting L with the lines 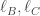 given in the question, since this would create two cyclic quadrilaterals, denoted
given in the question, since this would create two cyclic quadrilaterals, denoted 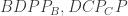 in the figure.
in the figure. . This cyclic quadrilateral gives us two equal angles in many different ways. But a particularly nice pair is the one shown, because ACPB is also cyclic, which confirms that the angle measure is
. This cyclic quadrilateral gives us two equal angles in many different ways. But a particularly nice pair is the one shown, because ACPB is also cyclic, which confirms that the angle measure is  . In particular, by extending
. In particular, by extending 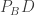 to E on AC, we get a third cyclic quadrilateral
to E on AC, we get a third cyclic quadrilateral  , and hence find out that
, and hence find out that 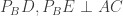 .
.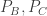 to the opposite sides of the triangle.
to the opposite sides of the triangle.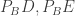 being perpendicular to AC, and the same for
being perpendicular to AC, and the same for  and AB, which are to be deduced,
and AB, which are to be deduced,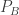 as we did above, and assert that the corresponding result also held for
as we did above, and assert that the corresponding result also held for 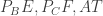 meet, and ask to prove that the meeting point lies on BC. I preferred the one I chose. Reflecting on the difficulty of the problem:
meet, and ask to prove that the meeting point lies on BC. I preferred the one I chose. Reflecting on the difficulty of the problem: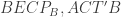 cyclic gives
cyclic gives 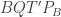 cyclic (in an exact reversal of the argument in the prelude earlier). What we don’t know is that
cyclic (in an exact reversal of the argument in the prelude earlier). What we don’t know is that 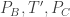 are collinear, but this follows since now we derive
are collinear, but this follows since now we derive  from this new cyclic quad. Consequently T’=T.
from this new cyclic quad. Consequently T’=T.
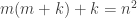


 be a polynomial with integer coefficients, and we consider whether the image
be a polynomial with integer coefficients, and we consider whether the image 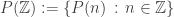 contains infinitely many squares.
contains infinitely many squares.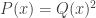 for Q another polynomial with integer coefficients, then this holds. Square sandwiching establishes that the answer is no when P(x) is a monic quadratic (meaning that the coefficient of
for Q another polynomial with integer coefficients, then this holds. Square sandwiching establishes that the answer is no when P(x) is a monic quadratic (meaning that the coefficient of 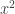 is one) unless P(x) is the square of a linear polynomial. The same holds if the leading coefficient is a square. Note that the general case where P(x) is negative except on a finite range (eg if P has even degree and negative leading coefficient) is also immediate.
is one) unless P(x) is the square of a linear polynomial. The same holds if the leading coefficient is a square. Note that the general case where P(x) is negative except on a finite range (eg if P has even degree and negative leading coefficient) is also immediate.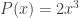 , we have P(n) a square whenever
, we have P(n) a square whenever 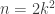 .
. has this property too!
has this property too! works when n is not a square because of the theory of
works when n is not a square because of the theory of 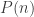 is always a square, does this imply
is always a square, does this imply 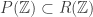 does this imply that
does this imply that 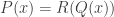 for some choice Q?
for some choice Q?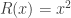 is classical, due to Polya, and is a good problem for any students reading this. The case
is classical, due to Polya, and is a good problem for any students reading this. The case 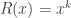 is handled by Polya and Szego. The case of general R is more challenging, and though it can be treated without heavier concepts, is probably best left until one knows some undergraduate algebra. Readers looking for a paper may consult Davenport, Lewis and Schinzel
is handled by Polya and Szego. The case of general R is more challenging, and though it can be treated without heavier concepts, is probably best left until one knows some undergraduate algebra. Readers looking for a paper may consult Davenport, Lewis and Schinzel 
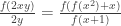
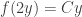 , ie f is linear on the even integers.
, ie f is linear on the even integers. is already known, leading to an expression for f(x+1), ie some control over the odd integers.
is already known, leading to an expression for f(x+1), ie some control over the odd integers.
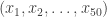 with the 49-dimensional vector
with the 49-dimensional vector  . We now have a large number of 49-dimensional integer vectors with entries bounded by [-2022,2022] with sum equal to the zero vector. Our task is to show that we can partition into two smaller sums with sum zero. (*)
. We now have a large number of 49-dimensional integer vectors with entries bounded by [-2022,2022] with sum equal to the zero vector. Our task is to show that we can partition into two smaller sums with sum zero. (*) denote the collection of vectors, and
denote the collection of vectors, and 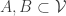 some subsets, inducing sums
some subsets, inducing sums 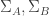 respectively. Clearly
respectively. Clearly 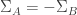 if
if 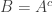 , and we might expect to be able to find
, and we might expect to be able to find 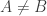 such that
such that  . I was hoping one could then move some vectors around (eg from
. I was hoping one could then move some vectors around (eg from 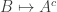 ) to produce disjoint sets A,B for which
) to produce disjoint sets A,B for which 
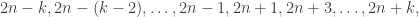
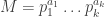 then its factors can be described as the set:
then its factors can be described as the set:
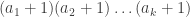 , independently of the choice of the primes. This gives a recipe for constructing all integers M<100 with at least twelve factors. We could take
, independently of the choice of the primes. This gives a recipe for constructing all integers M<100 with at least twelve factors. We could take 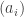 to be some permutation of (11), or (5,1), or (3,2), or (2,1,1), which give the following valid M:
to be some permutation of (11), or (5,1), or (3,2), or (2,1,1), which give the following valid M: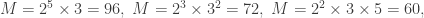



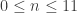 could be replaced by
could be replaced by 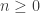 , since we are forced to include zero pieces of weight
, since we are forced to include zero pieces of weight 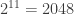 , and would similarly be forced to include zero pieces of weight
, and would similarly be forced to include zero pieces of weight 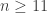 . (%)
. (%) to make total weight n satisfies the relations:
to make total weight n satisfies the relations: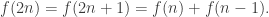 (*)
(*)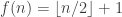 . (That is,
. (That is,  when n is even, and
when n is even, and 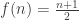 when n is odd.)
when n is odd.) , and trying to show that it is equal to
, and trying to show that it is equal to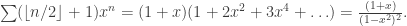 (*)
(*)
 . Equality is the best thing to aim for. Try and demonstrate and notate equal angles wherever possible.
. Equality is the best thing to aim for. Try and demonstrate and notate equal angles wherever possible.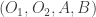 is equal, and all the angles are 60 or 120.
is equal, and all the angles are 60 or 120.
 with the following figure.
with the following figure.
 . It suffices to show that the blue angles are equal, which is equivalent to demonstrating that
. It suffices to show that the blue angles are equal, which is equivalent to demonstrating that 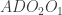 is cyclic.
is cyclic.
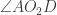 is equal to the red angle we’ve already discussed, and this follows by chasing round, using that
is equal to the red angle we’ve already discussed, and this follows by chasing round, using that 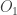 is the centre of triangle ABC, and then the fact that
is the centre of triangle ABC, and then the fact that  is the external angle opposite
is the external angle opposite 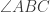 in cyclic quadrilateral
in cyclic quadrilateral  . Indeed, note that this use of an equal external angle rather than ‘opposite angle is 180 – […]’ is the textbook example of clear angle chasing, where focusing on equality rather than arithmetic massively cleans up many diagrams.
. Indeed, note that this use of an equal external angle rather than ‘opposite angle is 180 – […]’ is the textbook example of clear angle chasing, where focusing on equality rather than arithmetic massively cleans up many diagrams.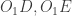 are angle bisectors, we have two pairs of equal angles as shown.
are angle bisectors, we have two pairs of equal angles as shown.
 is the external angle bisector of
is the external angle bisector of 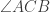 . And this is true, since
. And this is true, since  is the arc-midpoint of AB on
is the arc-midpoint of AB on 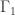 !
!
 . One could proceed by setting up inequalities involving the means of
. One could proceed by setting up inequalities involving the means of  and
and 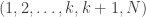 to establish a relationship between k and N.
to establish a relationship between k and N.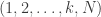 . If it is less than k, then removing k gives a smaller mean. If it is greater than k+1, then adding k+1 gives a smaller mean. So since the mean is an integer, it must be equal to k or k+1. That is, we have
. If it is less than k, then removing k gives a smaller mean. If it is greater than k+1, then adding k+1 gives a smaller mean. So since the mean is an integer, it must be equal to k or k+1. That is, we have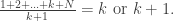
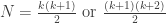 .
.
 , it holds that
, it holds that 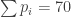 , and that each string of
, and that each string of  Ps introduces a factor of
Ps introduces a factor of  , leading to
, leading to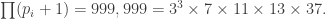
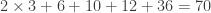 , so there exists a choice of the
, so there exists a choice of the  ?
?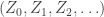 for a Galton-Watson process, where typically
for a Galton-Watson process, where typically 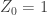 , and
, and 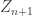 is the sum of
is the sum of 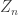 IID copies of the offspring distribution. Then we have
IID copies of the offspring distribution. Then we have
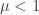 , we certainly have
, we certainly have ![\mathbb{P}(Z_k>0)\le \mathbb{E}[Z_k]=\mu^k](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28Z_k%3E0%29%5Cle+%5Cmathbb%7BE%7D%5BZ_k%5D%3D%5Cmu%5Ek&bg=ffffff&fg=333333&s=0&c=20201002) .
.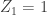 with probability
with probability  it is possible that the height is infinite with probability one.
it is possible that the height is infinite with probability one.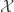 of these distributions? How do we determine which distribution in
of these distributions? How do we determine which distribution in 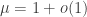 and the height k has a particular scaling. Also, as far as I understand, the approach outlined in this post didn’t provide strong enough bounds in this particular context. Happily, Serte has recently tied up all the corners of this project concerning the supercritical Galton-Watson forest, and interested readers can find her preprint
and the height k has a particular scaling. Also, as far as I understand, the approach outlined in this post didn’t provide strong enough bounds in this particular context. Happily, Serte has recently tied up all the corners of this project concerning the supercritical Galton-Watson forest, and interested readers can find her preprint  (which recall means that the means are the same but X is more concentrated) then a number of distributions associated to the Galton-Watson trees for X and Y also satisfy convex ordering relations.
(which recall means that the means are the same but X is more concentrated) then a number of distributions associated to the Galton-Watson trees for X and Y also satisfy convex ordering relations.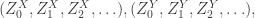
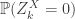 and
and 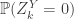 . If we write
. If we write  for the function defined on the non-negative integers such that
for the function defined on the non-negative integers such that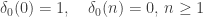 ,
, , then
, then ![\mathbb{E}[\delta_0(X)]\le \mathbb{E}[\delta_0(Y)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdelta_0%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5B%5Cdelta_0%28Y%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , which exactly says that
, which exactly says that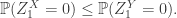
 by induction on
by induction on 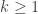 . Note that
. Note that  is a convex function of n, regardless of the value of this probability, and so we have
is a convex function of n, regardless of the value of this probability, and so we have![\mathbb{P}(Z^X_{k+1}=0) = \mathbb{E}\left[ (\mathbb{P}(Z^X_k=0))^X\right] \le \mathbb{E}\left[(\mathbb{P}(Z^X_k=0))^Y\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%28Z%5EX_%7Bk%2B1%7D%3D0%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%28%5Cmathbb%7BP%7D%28Z%5EX_k%3D0%29%29%5EX%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%28%5Cmathbb%7BP%7D%28Z%5EX_k%3D0%29%29%5EY%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[(\mathbb{P}(Z^Y_k=0))^Y\right] = \mathbb{P}(Z^Y_{k+1}=0)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%28%5Cmathbb%7BP%7D%28Z%5EY_k%3D0%29%29%5EY%5Cright%5D+%3D+%5Cmathbb%7BP%7D%28Z%5EY_%7Bk%2B1%7D%3D0%29&bg=ffffff&fg=333333&s=0&c=20201002) .
.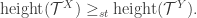
 and a subclass
and a subclass  such that for all
such that for all 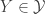 , there exists
, there exists  such that
such that 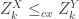 ?
? also satisfy
also satisfy 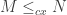 . Then
. Then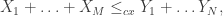
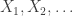 are IID copies of X and, independently,
are IID copies of X and, independently, 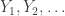 are IID copies of Y.
are IID copies of Y. and
and 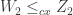 , and the four random variables are independent. Then
, and the four random variables are independent. Then  .
.![\mathbb{E}\left[f(Z+x)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bf%28Z%2Bx%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) is a convex function of x.
is a convex function of x.![\mathbb{E}\left[ f(W_1+W_2)\right]=\mathbb{E}\left[\, \mathbb{E}[f(W_1+W_2) \mid W_2 ] \,\right] \le \mathbb{E}\left[\, \mathbb{E}[f(W_1+Z_2)\mid Z_2 ] \, \right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28W_1%2BW_2%29%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5Bf%28W_1%2BW_2%29+%5Cmid+W_2+%5D+%5C%2C%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5Bf%28W_1%2BZ_2%29%5Cmid+Z_2+%5D+%5C%2C+%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
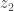 , we know
, we know 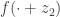 is convex, so
is convex, so ![\mathbb{E}[f(W_1+z_2)]\le \mathbb{E}[f(Z_1+z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28W_1%2Bz_2%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Z_1%2Bz_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and it follows that
, and it follows that![\mathbb{E}\left[ f(W_1+W_2)\right]\le \mathbb{E} \left[ f(Z_1+Z_2)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28W_1%2BW_2%29%5Cright%5D%5Cle+%5Cmathbb%7BE%7D+%5Cleft%5B+f%28Z_1%2BZ_2%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
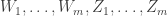 are independent, and satisfy
are independent, and satisfy  , then we have
, then we have 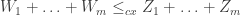 .
.![\mathbb{E}\left[ f(X_1+\ldots+X_M)\mid M=n\right] \le \mathbb{E}\left[ f(Y_1+\ldots+Y_N)\mid N=n\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+f%28X_1%2B%5Cldots%2BX_M%29%5Cmid+M%3Dn%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y_1%2B%5Cldots%2BY_N%29%5Cmid+N%3Dn%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[f(Y_1+\ldots+Y_n)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bf%28Y_1%2B%5Cldots%2BY_n%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) (*) is a convex function of n?
(*) is a convex function of n?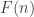 . To check convexity of a function defined on the integers, it suffices to verify that
. To check convexity of a function defined on the integers, it suffices to verify that  .
. , but it will be convenient to adjust the coupling, and write:
, but it will be convenient to adjust the coupling, and write:![F(n+1)-F(n)= \mathbb{E}\left[ f(Y_1+\ldots+Y_n + Y^*) - f(Y_1+\ldots+Y_n)\right],](https://s0.wp.com/latex.php?latex=F%28n%2B1%29-F%28n%29%3D+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y_1%2B%5Cldots%2BY_n+%2B+Y%5E%2A%29+-+f%28Y_1%2B%5Cldots%2BY_n%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![F(n)-F(n-1)=\mathbb{E}\left[f(Y_1+\ldots+Y_{n-1}+Y^*) - f(Y_1+\ldots+Y_{n-1})\right],](https://s0.wp.com/latex.php?latex=F%28n%29-F%28n-1%29%3D%5Cmathbb%7BE%7D%5Cleft%5Bf%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%2BY%5E%2A%29+-+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
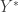 is a further independent copy of
is a further independent copy of  . But note that for any choice
. But note that for any choice 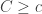 and
and  ,
,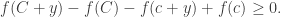 (*)
(*)![[c,C+y]](https://s0.wp.com/latex.php?latex=%5Bc%2CC%2By%5D&bg=ffffff&fg=333333&s=0&c=20201002) lies above the chord on interval
lies above the chord on interval ![[C,c+y]](https://s0.wp.com/latex.php?latex=%5BC%2Cc%2By%5D&bg=ffffff&fg=333333&s=0&c=20201002) or
or ![[c+y,C]](https://s0.wp.com/latex.php?latex=%5Bc%2By%2CC%5D&bg=ffffff&fg=333333&s=0&c=20201002) , which some people choose to call Karamata’s inequality, but I think is more helpful to think of as part of the visual definition of convexity.)
, which some people choose to call Karamata’s inequality, but I think is more helpful to think of as part of the visual definition of convexity.)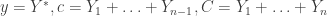 and taking expectations, we obtain
and taking expectations, we obtain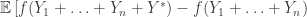
![\left.- f(Y_1+\ldots+Y_{n-1}+Y^*) + f(Y_1+\ldots+Y_{n-1})\right]\ge 0,](https://s0.wp.com/latex.php?latex=%5Cleft.-+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%2BY%5E%2A%29+%2B+f%28Y_1%2B%5Cldots%2BY_%7Bn-1%7D%29%5Cright%5D%5Cge+0%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[ X_1+\ldots+X_M\right] = \mathbb{E}\left[ \,\mathbb{E}[X_1+\ldots+X_M\mid M]\,\right] \le \mathbb{E}\left[\, \mathbb{E}[Y_1+\ldots+Y_M\mid M]\,\right] = \mathbb{E}[f(M)]\le \mathbb{E}[f(N)] = \mathbb{E}[Y_1+\ldots+Y_N],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+X_1%2B%5Cldots%2BX_M%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5C%2C%5Cmathbb%7BE%7D%5BX_1%2B%5Cldots%2BX_M%5Cmid+M%5D%5C%2C%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B%5C%2C+%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_M%5Cmid+M%5D%5C%2C%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Bf%28M%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28N%29%5D+%3D+%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_N%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[X]=\mathbb{E}[Y]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D%3D%5Cmathbb%7BE%7D%5BY%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002) with
with 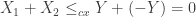 . So for total population size, since
. So for total population size, since 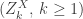 are not independent, an alternative approach would be required.
are not independent, an alternative approach would be required. with equal probability so
with equal probability so  . But then, taking both X and Y to be simple random walk on
. But then, taking both X and Y to be simple random walk on  , we do not have
, we do not have 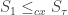 .
.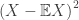 leads to Chebyshev’s inequality, while even stronger bounds can sometimes be obtained using
leads to Chebyshev’s inequality, while even stronger bounds can sometimes be obtained using 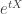 , for some appropriate value of
, for some appropriate value of 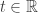 . Sometimes this final method, which relies on the finiteness of
. Sometimes this final method, which relies on the finiteness of ![\mathbb{E}[e^{tX}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Be%5E%7BtX%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) is referred to as a Chernoff bound, especially when an attempt is made to choose the optimal value of t for the estimate under consideration.
is referred to as a Chernoff bound, especially when an attempt is made to choose the optimal value of t for the estimate under consideration. in the Chernoff bound for each increment.
in the Chernoff bound for each increment.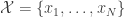 , and will study a sequence of m elements
, and will study a sequence of m elements 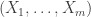 from this set with replacement (ie chosen in an IID fashion), and a sequence of m elements
from this set with replacement (ie chosen in an IID fashion), and a sequence of m elements 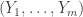 chosen from this set without replacement.
chosen from this set without replacement.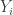 s are still chosen uniformly which can be interpreted as
s are still chosen uniformly which can be interpreted as
 is equally likely to appear as
is equally likely to appear as  ;
;![\mathbb{E}[X_1+\ldots+X_m]=\mathbb{E}[Y_1+\ldots+Y_m]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%2B%5Cldots%2BX_m%5D%3D%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_m%5D&bg=ffffff&fg=333333&s=0&c=20201002) , so concentration around this common mean is the next question of interest.
, so concentration around this common mean is the next question of interest. , we wouldn’t expect there to be much difference between sampling with or without replacement.
, we wouldn’t expect there to be much difference between sampling with or without replacement.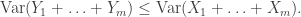
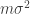 , where
, where 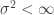 is the variance of a single uniform sample from
is the variance of a single uniform sample from ![\mathbb{E}\left[ (Y_1+\ldots+Y_m)^2\right] \le \mathbb{E}\left[ (X_1+\ldots+X_m)^2\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%28Y_1%2B%5Cldots%2BY_m%29%5E2%5Cright%5D+%5Cle+%5Cmathbb%7BE%7D%5Cleft%5B+%28X_1%2B%5Cldots%2BX_m%29%5E2%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
![n\mathbb{E}[Y_1^2] + n(n-1)\mathbb{E}[Y_1Y_2] \le n\mathbb{E}[X_1^2] + n(n-1)\mathbb{E}[X_1X_2].](https://s0.wp.com/latex.php?latex=n%5Cmathbb%7BE%7D%5BY_1%5E2%5D+%2B+n%28n-1%29%5Cmathbb%7BE%7D%5BY_1Y_2%5D+%5Cle+n%5Cmathbb%7BE%7D%5BX_1%5E2%5D+%2B+n%28n-1%29%5Cmathbb%7BE%7D%5BX_1X_2%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
 , it remains to handle the cross term, which involves showing that
, it remains to handle the cross term, which involves showing that
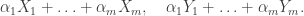
![\mathbb{E}\left[ (\alpha_1Y_1+\ldots+\alpha_n Y_n)^2\right] = \left(\alpha_1^2+\ldots+\alpha_n^2\right) \mathbb{E}[Y_1^2] + \left(\sum_{i\ne j} \alpha_i\alpha_j \right)\mathbb{E}\left[Y_1Y_2\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%28%5Calpha_1Y_1%2B%5Cldots%2B%5Calpha_n+Y_n%29%5E2%5Cright%5D+%3D+%5Cleft%28%5Calpha_1%5E2%2B%5Cldots%2B%5Calpha_n%5E2%5Cright%29+%5Cmathbb%7BE%7D%5BY_1%5E2%5D+%2B+%5Cleft%28%5Csum_%7Bi%5Cne+j%7D+%5Calpha_i%5Calpha_j+%5Cright%29%5Cmathbb%7BE%7D%5Cleft%5BY_1Y_2%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
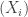 , from which the variance comparison inequality follows as before.
, from which the variance comparison inequality follows as before.![X\le_{st}Y \;\iff\;\mathbb{E}[f(X)] \le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bst%7DY+%5C%3B%5Ciff%5C%3B%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 direction which is harder to prove, though often the
direction which is harder to prove, though often the 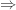 direction is the most useful in applications.
direction is the most useful in applications.![X\le_{cx} Y\;\iff \; \mathbb{E}[f(X)]\le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bcx%7D+Y%5C%3B%5Ciff+%5C%3B+%5Cmathbb%7BE%7D%5Bf%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 . Otherwise, consider the functions
. Otherwise, consider the functions 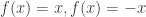 , both of which are convex.
, both of which are convex.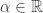 such that
such that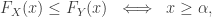
 is the usual distribution function of X. That is, the distribution functions ‘cross exactly once’. Note that in general
is the usual distribution function of X. That is, the distribution functions ‘cross exactly once’. Note that in general  .
.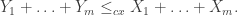
 ‘ has an unambiguous meaning.
‘ has an unambiguous meaning. as follows. Let
as follows. Let 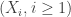 be IID uniform samples from
be IID uniform samples from 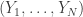 by removing any repetitions from
by removing any repetitions from  .
.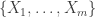 definitely includes
definitely includes 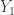 at least once, but otherwise includes each
at least once, but otherwise includes each  , since it is based on uniform sampling. In particular, if we condition instead on the set
, since it is based on uniform sampling. In particular, if we condition instead on the set  , we find that
, we find that![\mathbb{E}\left[X_1+\ldots+X_m\,\big|\, \{Y_1,\ldots,Y_m\}\right] = Y_1+\ldots+Y_m,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BX_1%2B%5Cldots%2BX_m%5C%2C%5Cbig%7C%5C%2C+%5C%7BY_1%2C%5Cldots%2CY_m%5C%7D%5Cright%5D+%3D+Y_1%2B%5Cldots%2BY_m%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[X_1+\ldots+X_m\,\big|\, Y_1+\ldots+Y_m\right] = Y_1+\ldots+Y_m.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BX_1%2B%5Cldots%2BX_m%5C%2C%5Cbig%7C%5C%2C+Y_1%2B%5Cldots%2BY_m%5Cright%5D+%3D+Y_1%2B%5Cldots%2BY_m.&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[X|Y]=Y](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%7CY%5D%3DY&bg=ffffff&fg=333333&s=0&c=20201002) as saying “X is generated by Y plus additional randomness”, which is consistent with the notion that Y is more concentrated than X. In any case, it meshes well with Jensen’s inequality, since if f is convex, we obtain
as saying “X is generated by Y plus additional randomness”, which is consistent with the notion that Y is more concentrated than X. In any case, it meshes well with Jensen’s inequality, since if f is convex, we obtain![\mathbb{E}[f(X)] = \mathbb{E}\left[ \mathbb{E}[f(X)|Y] \right] \ge \mathbb{E}\left[f\left(\mathbb{E}[X|Y] \right)\right] = \mathbb{E}\left[ f(Y)\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cmathbb%7BE%7D%5Bf%28X%29%7CY%5D+%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5Bf%5Cleft%28%5Cmathbb%7BE%7D%5BX%7CY%5D+%5Cright%29%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y%29%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}\left[\alpha_1X_1+\ldots+\alpha_nX_n\,\big|\,\{Y_1,\ldots,Y_m\}\right]=(\alpha_1+\ldots+\alpha_m)(Y_1+\ldots+Y_m),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Calpha_1X_1%2B%5Cldots%2B%5Calpha_nX_n%5C%2C%5Cbig%7C%5C%2C%5C%7BY_1%2C%5Cldots%2CY_m%5C%7D%5Cright%5D%3D%28%5Calpha_1%2B%5Cldots%2B%5Calpha_m%29%28Y_1%2B%5Cldots%2BY_m%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 .
.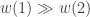 . So it is much more likely that
. So it is much more likely that 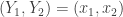 than
than 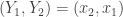 .
.![\mathbb{E}[Y_1+\ldots+Y_m]=\mathbb{E}[X_1+\ldots+X_m],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_1%2B%5Cldots%2BY_m%5D%3D%5Cmathbb%7BE%7D%5BX_1%2B%5Cldots%2BX_m%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[Y_1+Y_2]=x_1+x_2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_1%2BY_2%5D%3Dx_1%2Bx_2&bg=ffffff&fg=333333&s=0&c=20201002) while
while ![\mathbb{E}[X_1+X_2]\approx 2x_1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%2BX_2%5D%5Capprox+2x_1&bg=ffffff&fg=333333&s=0&c=20201002) .
.![X\le_{icx} Y\;\iff\; \mathbb{E}[f(X)]\le \mathbb{E}[f(Y)],](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bicx%7D+Y%5C%3B%5Ciff%5C%3B+%5Cmathbb%7BE%7D%5Bf%28X%29%5D%5Cle+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![X\le_{icx}Y\;\iff\; \mathbb{E}[\max(X-t,0)]\le \mathbb{E}[\max(Y-t,0)]\,\forall t\in\mathbb{R}.](https://s0.wp.com/latex.php?latex=X%5Cle_%7Bicx%7DY%5C%3B%5Ciff%5C%3B+%5Cmathbb%7BE%7D%5B%5Cmax%28X-t%2C0%29%5D%5Cle+%5Cmathbb%7BE%7D%5B%5Cmax%28Y-t%2C0%29%5D%5C%2C%5Cforall+t%5Cin%5Cmathbb%7BR%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
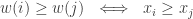 , of which size-biased sampling is a special case. With this setup, the heuristic is that ‘large values are more likely to appear earlier’ in the sample without replacement, and making this notion precise underpins all the work.
, of which size-biased sampling is a special case. With this setup, the heuristic is that ‘large values are more likely to appear earlier’ in the sample without replacement, and making this notion precise underpins all the work.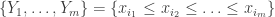 , one has
, one has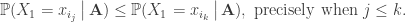
 exchanged. See [BPS18] for this short calculation – a link to the Arxiv version is in the references. So to calculate
exchanged. See [BPS18] for this short calculation – a link to the Arxiv version is in the references. So to calculate ![\mathbb{E}[X_1\,\big|\, \mathbf{A}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%5C%2C%5Cbig%7C%5C%2C+%5Cmathbf%7BA%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) , we have the setup for the rearrangement inequality / Chebyshev again, as
, we have the setup for the rearrangement inequality / Chebyshev again, as![\mathbb{E}[X_1\,\big|\, \mathbf{A}] = \sum_{j=1}^m x_{i_j}\mathbb{P}(X_1=x_{i_j}) \le \frac{1}{n}\left(\sum_{j=1}^m x_{i_j}\right)\left(\sum \mathbb{P}\right) = \frac{\left(Y_1+\ldots+Y_m\,\big|\,\mathbf{A}\right)}{m}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%5C%2C%5Cbig%7C%5C%2C+%5Cmathbf%7BA%7D%5D+%3D+%5Csum_%7Bj%3D1%7D%5Em+x_%7Bi_j%7D%5Cmathbb%7BP%7D%28X_1%3Dx_%7Bi_j%7D%29+%5Cle+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28%5Csum_%7Bj%3D1%7D%5Em+x_%7Bi_j%7D%5Cright%29%5Cleft%28%5Csum+%5Cmathbb%7BP%7D%5Cright%29+%3D+%5Cfrac%7B%5Cleft%28Y_1%2B%5Cldots%2BY_m%5C%2C%5Cbig%7C%5C%2C%5Cmathbf%7BA%7D%5Cright%29%7D%7Bm%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
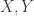 be the sums of the samples with and without replacement, respectively, we have
be the sums of the samples with and without replacement, respectively, we have ![\mathbb{E}[X\,\big|\, Y] \ge Y](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5C%2C%5Cbig%7C%5C%2C+Y%5D+%5Cge+Y&bg=ffffff&fg=333333&s=0&c=20201002) , which the authors term a submartingale coupling. In particular, the argument
, which the authors term a submartingale coupling. In particular, the argument![\mathbb{E}[f(X)] = \mathbb{E}\left[ \mathbb{E}[f(X)|Y] \right] \ge \mathbb{E}\left[f\left(\mathbb{E}[X|Y] \right)\right] \ge \mathbb{E}\left[ f(Y)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cmathbb%7BE%7D%5Bf%28X%29%7CY%5D+%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5Bf%5Cleft%28%5Cmathbb%7BE%7D%5BX%7CY%5D+%5Cright%29%5Cright%5D+%5Cge+%5Cmathbb%7BE%7D%5Cleft%5B+f%28Y%29%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 satisfies the relation:
satisfies the relation: (*)
(*) ?
?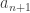 , with coefficients involving
, with coefficients involving  (**)
(**)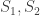 are tangent at P. A common tangent, not through P, touches
are tangent at P. A common tangent, not through P, touches 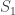 at A, and
at A, and  at B. Points C and D, on
at B. Points C and D, on 

