
In previous posts here and here, I’ve talked about attempts to describe a cycle deleting process. We amend the dynamics of the standard random graph process by demanding that whenever a cycle is formed in the graph we delete all the edges that lie on the cycle. The aim of this is to prevent the system growing giant components, and perhaps give a system that displays the characteristics of self-organised criticality. In the posts linked to, we discuss the difficulties caused by the fact that the tree structure of components in such a process is not necessarily uniform.
Today we look in the opposite direction. It gives a perfectly reasonable model to take a multiplicative coalescent with quadratic fragmentation (this corresponds to cycle deletion, since there are 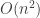
First, we count the number of unicyclic graphs on n labelled vertices. If we know that the vertices on the cycle are 

If we know that the tree coming off the cycle from vertex v_i has size m, say, then each of the possible rooted labelled trees with size m is equally likely. So taking 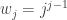

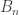

Consider now a related object, the so-called random mapping digraph. What follows is taken from Chapter 9 of Combinatorial Stochastic Processes. We can view any mapping ![M_n:[n]\rightarrow[n]](https://s0.wp.com/latex.php?latex=M_n%3A%5Bn%5D%5Crightarrow%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

In an identical manner to the unicyclic graph, the sizes of these directed trees in the digraph decomposition of a uniform random mapping is distributed as 

At least we know from the initial definition of a random mapping, that 
The time for a fuller discussion of this sort of phenomenon is in the context of Poisson-Dirichlet distributions, as the above exchangeable partition turns out to be PD(1/2,1/2). However, for now we remark that the jumps of a subordinator give a partition after rescaling. The case of a stable subordinator is particularly convenient, as calculations are made easier by the Levy-Khintchine formula.
A notable example is the stable-1/2 subordinator, which can be realised as the inverse of the local time process at zero of a Brownian motion. The jumps of this process are then the excursion lengths of the original Brownian motion. A calculation involving the tail of the w_j’s indicates that 1/2 is the correct parameter for a subordinator to describe the random mappings. Note that the number of blocks in the partition corresponds to the local time at zero of the Brownian motion. (This is certainly not obvious, but it should at least be intuitively clear why a larger local time roughly indicates more excursions which indicates more blocks.)
So it turns out, after checking some of the technicalities, that it will suffice to show that the rescaled number of blocks in the random mapping partition 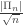
After that very approximate description, we conclude by showing that the distribution of the number of blocks does indeed converge as we require. Recall Cayley’s formula 
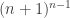

This odd way of writing it is well-motivated. The form of the LHS is reminiscent of a generating function, and the additional k suggests taking a derivative. Indeed, the LHS is the derivative

evaluated at 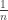
That said, having established that the random mapping partition is essentially the same, it is computationally more convenient to consider that instead. By the digraph analogy, we again need to count forests with k roots on n vertices, and multiply by the number of permutations of the roots. This gives:

Now we can consider the limit. Being a bit casual with notation, we get:

Since the Raleigh distribution has density 
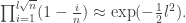
We take logs, so the LHS becomes:
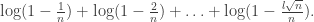
If we view this as a function of l and differentiate, we get
![d(LHS)=\sqrt{n}dl \log (1-\frac{l}{\sqrt{n}})\approx \sqrt{n}dl \left[-\frac{l}{\sqrt{n}}-\frac{l^2}{2n}\right]\approx -ldl.](https://s0.wp.com/latex.php?latex=d%28LHS%29%3D%5Csqrt%7Bn%7Ddl+%5Clog+%281-%5Cfrac%7Bl%7D%7B%5Csqrt%7Bn%7D%7D%29%5Capprox+%5Csqrt%7Bn%7Ddl+%5Cleft%5B-%5Cfrac%7Bl%7D%7B%5Csqrt%7Bn%7D%7D-%5Cfrac%7Bl%5E2%7D%7B2n%7D%5Cright%5D%5Capprox+-ldl.&bg=ffffff&fg=333333&s=0&c=20201002)
When l is zero, the LHS should be zero, so we can obtain the desired result (*) by integrating then taking an exponential.
Related articles
- Cyclic quadrilaterals & Brahmagupta’s formula (mathtuition88.com)
- Stochastic Processes, Indistinguishability and Modifications (nucaltiado.wordpress.com)
- Brouwer’s Topological Degree (III): First Applications (chiasme.wordpress.com)
- From Proofs to Prime Numbers: Math Blogs on WordPress.com (nerdlypainter.wordpress.com)
