
This post continues the discussion of the Oxford first-year course Linear Algebra II. We’ve moved on from determinants, and are now considering eigenvalues and eigenvectors of matrices and linear maps.
A good question to ask is: what’s the point of knowing about eigenvectors? I can think of a quick answer and a longer answer. The quick answer is that whenever we have a mapping of any kind, it is natural to ask about its fixed points. And since we are thinking about vector spaces and linear maps, if we can’t find any fixed points, we might nonetheless be able to find the best thing, some vectors whose direction is fixed by the map. In general, knowing about fixed points of a mapping might tell us other more qualitative properties, including the behaviour seen when you apply the map iteratively a large number of times. (Indeed a recent post discusses this exact problem for positive matrices in a context relevant to a chapter of my thesis…)
A more specific answer concerns bases. Recall that a linear map is defined independently of any basis: it’s just a map from the vector space to itself. We can express the linear map via a matrix with respect to some basis, but how to choose the basis? We could always choose the canonical basis in 
But once we know something about the linear map, we might want to choose a basis of vectors on which the behaviour of the map is particularly easy to describe. And eigenvectors fulfil precisely this role. If we are able to choose a basis of eigenvectors, describing the map’s action, either abstractly, or via a (diagonal) matrix, is very straightforward. If we are given a matrix to begin with, we know how to do a change of basis, and changing to the basis of eigenvectors is precisely what’s going when we write 
So the case where we have a basis of eigenvectors is particularly useful, and in this case, we say the matrix or the map is diagonalisable. Remember how we find eigenvalues. If there exists a non-zero vector x satisfying 
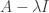

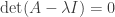
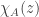
If we agree to work over the complex field, then this is good, because it means we always have eigenvalues, and so it becomes sensible to talk about exactly how many eigenvalues and eigenvectors we have. Observe that if we restrict to real vector spaces, this might not be the case. In the plane, the rotation by 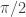
Multiplicities of eigenvalues
We call the algebraic multiplicity 
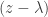
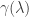
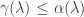
The more obvious, but more frequently forgotten result is that
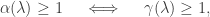
which is simply a consequence of the property discussed a few paragraphs previously concerning the kernel of
In particular, we might make the heuristic observation that ‘most’ polynomials of degree n have n distinct roots. This is certainly true for quadratics: there is only one value that the discriminant can take such that we see a repeated root. Alternatively, imagine shifting the quadratic up and down (in a complex way if necessary); again there is only one moment at which it might have a repeated root. This observation can be generalised easily to higher degree polynomials in a number of ways.
So if we lift this observation across to matrices, we see that most matrices have n distinct eigenvalues, and thus have n linearly independent eigenvectors which form a basis, hence the matrix is diagonalisable. I think it’s really worth reflecting on this, since much of a first exploration into linear algebra ends up treating exactly the case where the matrix is not diagonalisable.
The principal example of a non-diagonalisable matrix is 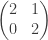
It probably is worth saying now though, that this example gives a good sanity check for whether a method is actually using diagonalisability correctly. For example, it is easily seen that elementary row operations to not preserve diagonalisability by starting from 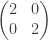
Cayley-Hamilton theorem
Anyway, among other results, we also saw the Cayley-Hamilton theorem, which states that a matrix A satisfies its own characteristic equation. That is 

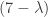
Fortunately, we can argue convincingly in the case where A is a diagonalisable matrix. Remember that 
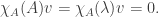
This only worked when v was an eigenvector, but fortunately there is a basis of eigenvectors if A is diagonalisable, and so 
But 
Even without the integrality of the coefficients, this says that, under any reasonable definition of continuity of matrices (which could be induced from any topology on 
It’s worth ending with the brief comment that Cayley-Hamilton is useful, among other reasons because it enables us to write the inverse of A as a polynomial of degree at most n-1 in terms of A. In many settings this is a lot easier to work with in terms of calculations than an argument with minors.
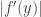 .
.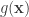 . If we have a similar transformation of the base variable
. If we have a similar transformation of the base variable 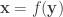 , we differentiate to get
, we differentiate to get
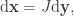
![[0,\mathrm{d}x_1]\times\ldots\times [0,\mathrm{d}x_n]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cmathrm%7Bd%7Dx_1%5D%5Ctimes%5Cldots%5Ctimes+%5B0%2C%5Cmathrm%7Bd%7Dx_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) to the volume
to the volume ![[0,\mathrm{d}y_1]\times \ldots\times [0,\mathrm{d}y_n]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cmathrm%7Bd%7Dy_1%5D%5Ctimes+%5Cldots%5Ctimes+%5B0%2C%5Cmathrm%7Bd%7Dy_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) . It’s simply the determinant of the Jacobean J. So if we want to integrate with respect to
. It’s simply the determinant of the Jacobean J. So if we want to integrate with respect to 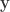 , it only remains to pre-multiply the integrand by
, it only remains to pre-multiply the integrand by  and proceed otherwise as in the one-dimensional case.
and proceed otherwise as in the one-dimensional case.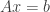 . The main idea is that generally we can solve this equation uniquely. Almost all of the theory developed in such a first linear algebra course deals with the case when this fails to hold. In particular, there are many ways to characterise this case, and we list some of them now:
. The main idea is that generally we can solve this equation uniquely. Almost all of the theory developed in such a first linear algebra course deals with the case when this fails to hold. In particular, there are many ways to characterise this case, and we list some of them now:
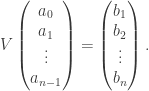
 , and the argument is given by
, and the argument is given by  .
. and
and 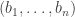 , we are asking whether we can find a polynomial P with degree at most n-1 such that
, we are asking whether we can find a polynomial P with degree at most n-1 such that  for
for 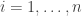 . Lagrange interpolation gives an argument where we just directly write down the relevant polynomial, but we can also deploy our linear algebraic arguments too.
. Lagrange interpolation gives an argument where we just directly write down the relevant polynomial, but we can also deploy our linear algebraic arguments too.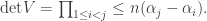
 are distinct, and so this determinant is non-zero, and we’ve shown that n points determine a degree (n-1) polynomial uniquely.
are distinct, and so this determinant is non-zero, and we’ve shown that n points determine a degree (n-1) polynomial uniquely.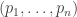 . Then we have
. Then we have![(p_1,\ldots,p_n) V = (1,\mathbb{E}X, \mathbb{E}[X^2],\ldots, \mathbb{E}[X^{n-1}]).](https://s0.wp.com/latex.php?latex=%28p_1%2C%5Cldots%2Cp_n%29+V+%3D+%281%2C%5Cmathbb%7BE%7DX%2C+%5Cmathbb%7BE%7D%5BX%5E2%5D%2C%5Cldots%2C+%5Cmathbb%7BE%7D%5BX%5E%7Bn-1%7D%5D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
 to the base field (hereafter assumed to be
to the base field (hereafter assumed to be  ). The Oxford course defines it through its properties:
). The Oxford course defines it through its properties: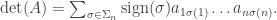
 :
:

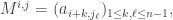
 s in the Laplace expansion.
s in the Laplace expansion.
 , then view the remainder of the permutation as a bijection
, then view the remainder of the permutation as a bijection ![\{2,3,\ldots,n\}\rightarrow [n]\backslash \{k\}](https://s0.wp.com/latex.php?latex=%5C%7B2%2C3%2C%5Cldots%2Cn%5C%7D%5Crightarrow+%5Bn%5D%5Cbackslash+%5C%7Bk%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
.