
This term, I’m giving tutorials on a course that’s new to me, the apparently notorious ‘Linear Algebra II’ for first year undergraduates. I can appreciate how it might have ended up with this reputation, but as always, every challenge is also an opportunity, So I’m going to (try to) write a short series of blog posts about what we’ve discussed in the tutorials.
The first problem sheet-and-a-half concerned determinants of matrices. There are three things worth addressing here:
- What are abstract definitions, and which is most useful in each setting?
- How to actually calculate them?
- What’s the overall point?
The answers are obviously not completely unrelated, but we’ll probably defer the third question to a second post.
The determinant is a map from the set of matrices 

- Multilinear in the columns of the matrix.
- Equal to zero if two columns are equal.
- Equal to one if the matrix is the identity.
One then checks that there is a unique such map, and so from now on it’s reasonable to call it the determinant of the matrix. It will follow from pretty much any consequence that we can replace ‘columns’ with ‘rows’ throughout and get the same map.
Other definitions
We have a closed form expression for the determinant given via permutations of n
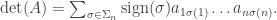
We’ll come back to a discussion of when this particular definition is useful. It can be derived by carefully transforming the identity matrix into A, using the operations which are mentioned in the original definition of the determinant, in particular, keeping track of the number of transpositions of columns.
It’s clear from any definition that the determinant is a polynomial of degree n in the entries of the matrix, but this definition will be useful if you want to make some more precise comment on the nature of this polynomial. For example, if entries of the matrix are polynomials in x of various degree (think of the eigenvalue equation for example) this allows you to control (or at least bound) the overall degree of the determinant as a polynomial in x.
The determinant is also the volume of the n-dimensional parallelopiped formed by the column vectors of the matrix. This is easy to check in two dimensions, for the matrix 
 To calculate the area of the central parallelogram, we have to subtract the area of two small rectangles and four small triangles from the outer rectangle, obtaining
To calculate the area of the central parallelogram, we have to subtract the area of two small rectangles and four small triangles from the outer rectangle, obtaining

as we expect. This calculation is harder to execute in higher dimensions, and certainly harder to visualise.
Maybe, though, we don’t have to, so long as we can reassure ourselves that this volume satisfies the implicit definition of the determinant map at the start. Multilinearity in the columns is not that hard to see. If we multiply the jth column by some constant, we are stretching the parallelopiped by the same constant factor in one direction, and so the volume grows appropriately. The additivity property can similarly be thought of as joining together two parallelopipeds at their common face (which is common since the other column vectors have to be constant in this construction). If two column vectors are equal, then clearly this volume actually has dimension at most n-1, and thus volume zero, so the final two conditions are genuinely easy to check.
The challenge here is that there is a direction involved. Determinants can be negative, but in our classical viewpoint, areas generally are not. In 2D, we can think of this as saying that the area is positive if the vector (b,d) lies anti-clockwise from (a,c) in the parallelogram, while is it negative otherwise. Again, this is harder to visualise in higher dimensions, but it is at least plausible that one could develop a similar decomposition. Ultimately, we are happy with the notion of directed lengths (ie vectors on the real line), and these are easy to add up without having to separate into cases, and the case holds for areas and higher-dimensional volumes.
Evaluating determinants
If we actually want to compute the determinant of a given matrix, the sum over permutations is intractable since it doesn’t have any natural splits into stages. The implicit definitions and this area consideration are clearly useless for all but the most special of examples.
The Laplace expansion is the usual algorithm to calculate the determinant of an n x n matrix. You pick a row (or a column), and evaluate the determinants of the (n-1) x (n-1) minor matrices given by deleting this row (or column), and each column (or row) in turn. This leaves us with n determinants of smaller matrices, which we pre-multiply by the entries in the original deleted row (or column), and add up in an alternating way (*). This is highly computationally intensive for large matrices, but for 3×3 and 4×4 can be done by hand with probability of an error bounded away from 1.
There is the flexibility to choose the reference row or column. Since the entries of these affect the sum through small products, it is highly convenient to choose a row or column with a lot of zeros. In particular, if there’s a row or column with exactly one non-zero entry, this is an ideal candidate.
The sum over permutations also works well when a lot of the entries are zero, because then a lot of the permutations give a summand which is zero. Upper-triangular matrices are a good example: only one permutation (the identity permutation) avoids all the zero elements underneath the diagonal.
One can also observe from the multilinearity property of the determinant map that there are lots of operations we can apply to the matrix which leave the determinant fixed. These are often called elementary row operations, though obviously we can apply them to the columns as well. To summarise, if we interchange two rows, the sign of the determinant is reversed. And if we add some multiple of one row to any other row, the determinant stays the same.
When matrices are not square, it’s quite important to be specific about exactly what form you can reduce a general matrix to via such row operations, but in this context, it’s not hugely important. Reduced echelon form (without the condition that leading coefficients will be one) is achievable, but this is a special case of an upper triangular matrix, for which the determinant is given by the product of the diagonal entries, ie is easy.
Whether this is substantially easier than Laplace expansion depends on the matrix itself and taste, both to do manually, and to code.
(*) I’m not a fan personally of this alternating definition. It seems to me much more natural to define the minor as
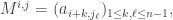
with indices taken modulo n. Then you don’t have any 
Using determinants in abstract problems
So the determinant gives directly the area of the image (under A) of the unit hypercube. By linearity (of A), it is easy to see that it also gives the scale factor of the area change (under A) of any hyper-cuboid, parallel to the conventional axes, anywhere in the space. Then, eg by approximating any sensible n-dimensional shape (*) as a union of such hyper-cuboids, we can show that in fact the area of any sensible shape increases by a factor (det A) under application of A.
This is a good thing to remember, because it is an excellent heuristic for seeing why the determinant of a linear map is basis-independent. It also gives a much easier proof of the key result

than that given by fixing B and viewing det(AB) as a map from matrices to the field, just like the original definition of determinant.
Some of the theory in the course is proved using elementary row operations. But these invite complicated notation, so are best used only in simple arguments, or when things are fairly explicit to begin with. Given an abstract problem about determinants of matrices, it is often tempting to induct on the size of the matrix in some way. I think it’s worth saying that even though the Laplace expansion is explicitly set up in this way, the notation involved is also likely to be annoying here, while permutations are easy to describe inductively: eg let 
![\{2,3,\ldots,n\}\rightarrow [n]\backslash \{k\}](https://s0.wp.com/latex.php?latex=%5C%7B2%2C3%2C%5Cldots%2Cn%5C%7D%5Crightarrow+%5Bn%5D%5Cbackslash+%5C%7Bk%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Shortly, we’ll have a second post answering the final question: what’s the point of working with determinants? We’ve already seen half an answer, in that they describe the change-of-volume factor of a matrix (or linear map), but this can be substantially developed.
