
We have just finished discussing chapters 11 and 12 of Markov Chains and Mixing Times, the end of the ‘core material’. I thought that, rather than addressing some of the more interesting but technical spectral methods that have just arisen, it would be a good subject for a quick post to collate some of the information about Cesaro mixing, which is spread throughout this first section.
Idea
A main result in the introductory theory of Markov chains is that for an irreducible aperiodic chain X, the distribution of 
But this isn’t the only result about convergence in distribution of functionals of Markov chains. Perhaps more intuitive is the ergodic theorem which asserts that the proportion of time spent in a particular state also converges to the equilibrium probability as time advances. We might write:

Note that if the state space 

and the mixing time for this sequence of measures is defined as for the conventional mixing time, and is called the Cesaro mixing time, at least in the Levin / Peres / Wilmer text.
Advantages
There are some obvious advantages to considering Cesaro mixing. Principally, a main drawback of conventional mixing is that we are unable to consider periodic chains. This property was the main content of the previous post, but to summarise, if a chain switches between various classes in a partition of the state space in a deterministic periodic way, then the distribution does not necessarily converge to equilibrium. The previous post discusses several ways of resolving this problem in specific cases. Note that this problem does not affect Cesaro mixing as the ergodic theorem continues to hold in the periodic case. Indeed the form of the distribution (which we might call an occupation measure in some contexts) confirms the intuition about viewing global mixing as a sort of sum over mixing modulo k in time.
Other advantages include the fact that the dependence on the initial state is weaker. For instance, consider the occupation measures for a chain started at x which moves first to y, versus a chain which starts at y then proceeds as the original. It requires very little thought to see that for O(1) values of t, this difference in occupation measures between these chains becomes small.
Another bonus is that we can use so-called stationary times to control Cesaro mixing. A stationary time is a stopping time such that 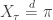


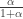


Why does this fail to work for normal mixing? The key to the above argument was that by taking an average over time up to some 



Disadvantages
So why do we not consider Cesaro mixing rather than the conventional variety? Well, mainly because of how we actually use mixing times. The Metropolis algorithm gives a way to generate chains with a particular equilibrium distribution, including ones for which it is hard to sample directly. Mixing time theory then gives a quantitative answer to the question of how long it is necessary to run such a chain for before it gives a good estimate to the equilibrium distribution. In many cases, such a random walk on a large unknown network, the main aim when applying such Monte Carlo procedures is to minimise the difficulty of calculation. For Cesaro mixing, you have to store all the information about path states, while for conventional mixing you only care about your current location.
The other phenomenon that is lacking in Cesaro mixing is cutoff. This is where the total variation distance
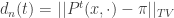
converges to 0 suddenly. More formally, there is some timescale f(n) such that

so in the n-limit, the graph of d looks like a step-function. Several of the shuffling chains exhibit this property, leading to the statements like “7 shuffles are required to mix a standard pack of cards”. Cesaro mixing smooths out this effect on an f(n) timescale.
A Further Example
Perhaps the best example where Cesaro mixing happens faster than normal mixing is in the case of a lazy biased random walk on 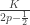
On the other hand, the distribution of X at time Kn is still fairly concentrated. If we assume we are instead performing the random walk on 
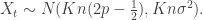
That is, the standard deviation is 


Related articles
- Mixing Times 4 – Avoiding Periodicity (eventuallyalmosteverywhere.wordpress.com)
- Mixing Times 2 – Metropolis Chains (eventuallyalmosteverywhere.wordpress.com)
- A randomized algorithm that fails with near certainty (win-vector.com)
 such that conditional on
such that conditional on  , we have
, we have  , where the indices of the Vs are taken modulo k. Such a chain is called periodic with period k. In most cases, we would want to define the period to be the maximal such k.
, where the indices of the Vs are taken modulo k. Such a chain is called periodic with period k. In most cases, we would want to define the period to be the maximal such k.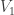 as defined above, then the distribution at time t will be entirely supported on
as defined above, then the distribution at time t will be entirely supported on  , where
, where 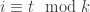 . In particular, this cannot converge to some equilibrium.
. In particular, this cannot converge to some equilibrium. for
for 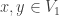 is an irreducible (aperiodic if k is maximal) transition matrix on
is an irreducible (aperiodic if k is maximal) transition matrix on  or similar. An initial distribution mixed between classes gives a mix of such equilibria. Alternatively, we could think about large-time ergodic properties. By taking an average over all distributions up to some large t, the periodic problems get smoothed out. So, for mixing on a periodic chain, it might be possible to make headway with Cesaro mixing, which looks at the speed of convergence of the ergodic average distribution.
or similar. An initial distribution mixed between classes gives a mix of such equilibria. Alternatively, we could think about large-time ergodic properties. By taking an average over all distributions up to some large t, the periodic problems get smoothed out. So, for mixing on a periodic chain, it might be possible to make headway with Cesaro mixing, which looks at the speed of convergence of the ergodic average distribution. . This says that at every time t, we toss an independent fair coin, and with probability 1/2 make the transition suggested by P, and with probability 1/2 we stay where we are. Note that if a chain is irreducible, and some P(x,x)>0, then it is definitely aperiodic, as x cannot be in more than one class as per the definition of periodicity.
. This says that at every time t, we toss an independent fair coin, and with probability 1/2 make the transition suggested by P, and with probability 1/2 we stay where we are. Note that if a chain is irreducible, and some P(x,x)>0, then it is definitely aperiodic, as x cannot be in more than one class as per the definition of periodicity.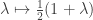 .
. and rescale the rest of the row appropriately. Also, in some cases, a different constant gives a more natural interpretation of the underlying mechanism. For example, one model worth considering is the Random Transposition Random Walk on the symmetric group, where at time t we multiply (ie compose) with a transposition chosen uniformly at random. This model is interesting partly because the orbits of an element resemble, at least initially, the component size process of a Erdos-Renyi random graph, on the grounds that when the number of transpositions is small, they don’t interact too much, so can be viewed as independent edges. Anyway, some form of laziness is needed in RTRW, otherwise the chain will alternative between odd and even permutations. In this case, 1/2 is not the most natural choice. The most sensible way to sample random transpositions is to select the two elements of [n] to be transposed uniformly and independently at random. Thus each transposition is selected with probability
and rescale the rest of the row appropriately. Also, in some cases, a different constant gives a more natural interpretation of the underlying mechanism. For example, one model worth considering is the Random Transposition Random Walk on the symmetric group, where at time t we multiply (ie compose) with a transposition chosen uniformly at random. This model is interesting partly because the orbits of an element resemble, at least initially, the component size process of a Erdos-Renyi random graph, on the grounds that when the number of transpositions is small, they don’t interact too much, so can be viewed as independent edges. Anyway, some form of laziness is needed in RTRW, otherwise the chain will alternative between odd and even permutations. In this case, 1/2 is not the most natural choice. The most sensible way to sample random transpositions is to select the two elements of [n] to be transposed uniformly and independently at random. Thus each transposition is selected with probability  , while the identity, which corresponds to ‘lazily’ staying at the current state in the random walk, is selected with probability 1/n.
, while the identity, which corresponds to ‘lazily’ staying at the current state in the random walk, is selected with probability 1/n.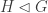 to be the normal subgroup, and gH to be the relevant coset, then
to be the normal subgroup, and gH to be the relevant coset, then  is supported entirely on
is supported entirely on  , so is periodic with period equal to the order of gH in the quotient group G/H. Note that if the coset is the normal subgroup itself, then it might well include support on the identity, which immediately makes the chain aperiodic. However, there will be then be no transitions between cosets, so the chain is not irreducible on G.
, so is periodic with period equal to the order of gH in the quotient group G/H. Note that if the coset is the normal subgroup itself, then it might well include support on the identity, which immediately makes the chain aperiodic. However, there will be then be no transitions between cosets, so the chain is not irreducible on G.
 . These elements have order three and two respectively, and so by a similar argument to the general one above, this random walk is aperiodic.
. These elements have order three and two respectively, and so by a similar argument to the general one above, this random walk is aperiodic.