
Motivation
In the previous posts about Large Deviations, most of the emphasis has been on the theory. To summarise briefly, we have a natural idea that for a family of measures supported on the same metric space, increasingly concentrated as some index grows, we might expect the probability of seeing values in a set not containing the limit in distribution to grow exponentially. The canonical example is the sample mean of a family of IID random variables, as treated by Cramer’s theorem.
It becomes apparent that it will not be enough to specify the exponent for a given large deviation event just by taking the infimum of the rate function, so we have to define an LDP topologically, with different behaviour on open and closed sets. Now we want to find some LDPs for more complicated measures, but which will have genuinely non-trivial applications. The key idea in all of this is that the infimum present in the definition of an LDP doesn’t just specify the rate function, it also might well give us some information about the configurations or events that lead to the LDP.
The slogan for the LDP as in Frank den Hollander’s excellent book is: “A large deviation event will happen in the least unlikely of all the unlikely ways.” This will be useful when our underlying space is a bit more complicated.
Setup
As a starting point, consider the set-up for Cramer’s theorem, with IID 
Concretely, we consider the rescaled random walk:
![Z_n(t):=\tfrac{1}{n}\sum_{i=1}^{[nt]}X_i,\quad t\in[0,1],](https://s0.wp.com/latex.php?latex=Z_n%28t%29%3A%3D%5Ctfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7B%5Bnt%5D%7DX_i%2C%5Cquad+t%5Cin%5B0%2C1%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
with laws 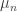
![L_\infty([0,1])](https://s0.wp.com/latex.php?latex=L_%5Cinfty%28%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)
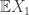
![\sqrt{n}\left(\frac{Z_n(t)-t\mathbb{E}X}{\sqrt{\text{Var}(X_1)}}\right)\quad\stackrel{d}{\rightarrow}\quad B(t),\quad t\in[0,1].](https://s0.wp.com/latex.php?latex=%5Csqrt%7Bn%7D%5Cleft%28%5Cfrac%7BZ_n%28t%29-t%5Cmathbb%7BE%7DX%7D%7B%5Csqrt%7B%5Ctext%7BVar%7D%28X_1%29%7D%7D%5Cright%29%5Cquad%5Cstackrel%7Bd%7D%7B%5Crightarrow%7D%5Cquad+B%28t%29%2C%5Cquad+t%5Cin%5B0%2C1%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
This is what we expect ‘standard’ behaviour to look like:

The deviations from a straight line are on a scale of 

Or this:

Note that these are qualitatively different. In the first case, the first half of the random variables are in general much larger than the second half, which appear to have empirical mean roughly 0. In the second case, a large deviation in overall mean is driven by a single very large value. It is obviously of interest to find out what the probabilities of each of these possibilities are.
We can do this via an LDP for 
We assume that 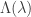

Theorem (Mogulskii): The measures

where AC is the space of absolutely continuous functions on [0,1]. Note that AC is dense in 

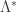
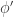
The following picture may be helpful at providing some motivation:

So what is going on is that if we take a path and zoom in on some small interval around a point, note first that behaviour on this interval is independent of behaviour everywhere else. Then the gradient at the point is the local empirical mean of the random variables around this point in time. The probability that this differs from the actual mean is given by Cramer’s rate function applied to the empirical mean, so we obtain the rate function for the whole path by integrating.
More concretely, but still very informally, suppose there is some 


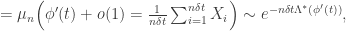
by Cramer. Now we can use independence:
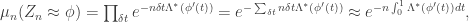
as in fact is given by Mogulskii.
Remarks
1) The absolutely continuous requirement is useful. We really wouldn’t want to be examining carefully the tail of the underlying distribution to see whether it is possible on an exponential scale that o(n) consecutive RVs would have sum O(n).
2) In general
3) The proof as given in Dembo and Zeitouni is quite involved. There are a few stages, the first and simplest of which is to show that it doesn’t matter on an exponential scale whether we interpolate linearly or step-wise. Later in the proof we will switch back and forth at will. The next step is to show the LDP for the finite-dimensional problem given by evaluating the path at finitely many points in [0,1]. A careful argument via the Dawson-Gartner theorem allows lifting of the finite-dimensional projections back to the space of general functions with the topology of pointwise convergence. It remains to prove that the rate function is indeed the supremum of the rate functions achieved on projections. Convexity of
In conclusion, it is fairly tricky to prove even this most straightforward case, so unsurprisingly it is hard to extend to the natural case where the distributions of the underlying RVs (X) change continuously in time, as we will want for the analysis of more combinatorial objects. Next time I will consider why it is hard but potentially interesting to consider with adaptations of these techniques an LDP for the size of the largest component in a sparse random graph near criticality.
Related articles
- Large Deviations 1 – Motivation and Cramer’s Theorem
- Large Deviations 2 – LDPs, Rate Functions and Lower Semi-Continuity
- Large Deviations 3 – Gartner-Ellis Theorem
- Large Deviations 4 – Sanov’s Theorem
- properties of heuristics and A* (alikhuram.wordpress.com)
- Measures Are Better (rjlipton.wordpress.com)
- Lebesgue Differentiation (landonkavlie.wordpress.com)
- Applying Green’s Theorem on Hurricane Project (harveyjohnson.wordpress.com)
- input something every day! (toutsurladance.wordpress.com)
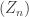 on
on 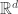 with laws
with laws  converge as required. For analogy with Cramer, take
converge as required. For analogy with Cramer, take 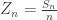 . The Gartner-Ellis theorem gives conditions for the existence of a suitable lower bound and, in particular, when this is the same as the upper bound.
. The Gartner-Ellis theorem gives conditions for the existence of a suitable lower bound and, in particular, when this is the same as the upper bound.
![\Lambda(\lambda)=\lim_{n\rightarrow\infty}\frac{1}{n}\Lambda_n(n\lambda)\in[-\infty,\infty],](https://s0.wp.com/latex.php?latex=%5CLambda%28%5Clambda%29%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5Cfrac%7B1%7D%7Bn%7D%5CLambda_n%28n%5Clambda%29%5Cin%5B-%5Cinfty%2C%5Cinfty%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
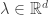 . We also assume that
. We also assume that  , where
, where 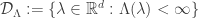 . We also define the Fenchel-Legendre transform as before:
. We also define the Fenchel-Legendre transform as before:![\Lambda^*(x)=\sup_{\lambda\in\mathbb{R}^d}\left[\langle x,\lambda\rangle - \Lambda(\lambda)\right],\quad x\in\mathbb{R}^d.](https://s0.wp.com/latex.php?latex=%5CLambda%5E%2A%28x%29%3D%5Csup_%7B%5Clambda%5Cin%5Cmathbb%7BR%7D%5Ed%7D%5Cleft%5B%5Clangle+x%2C%5Clambda%5Crangle+-+%5CLambda%28%5Clambda%29%5Cright%5D%2C%5Cquad+x%5Cin%5Cmathbb%7BR%7D%5Ed.&bg=ffffff&fg=333333&s=0&c=20201002)
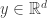 is an exposed point of
is an exposed point of  ,
,
 has a global minimum or maximum at y, where
has a global minimum or maximum at y, where 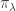 is the projection into
is the projection into 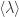 . Roughly speaking, this vector is what we will to take the Cramer transform for the lower bound at x. Recall that the Cramer transform is an exponential reweighting of the probability density, which makes a previously unlikely event into a normal one. We may now state the theorem.
. Roughly speaking, this vector is what we will to take the Cramer transform for the lower bound at x. Recall that the Cramer transform is an exponential reweighting of the probability density, which makes a previously unlikely event into a normal one. We may now state the theorem. ,
,  closed.
closed. ,
,  open, where E is the set of exposed points of
open, where E is the set of exposed points of  .
. is also lower semi-continuous, and is differentiable on
is also lower semi-continuous, and is differentiable on  ,
, 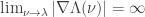 , then we may replace
, then we may replace 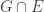 by G in the second statement. Then
by G in the second statement. Then 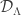 if we are to have a chance of getting any useful information out of the transform. By convexity, this is equivalent to the exposing hyperplane being in
if we are to have a chance of getting any useful information out of the transform. By convexity, this is equivalent to the exposing hyperplane being in 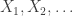 i.i.d. real-valued random variables with finite expectation, and
i.i.d. real-valued random variables with finite expectation, and 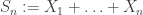 , the Weak Law of Large Numbers asserts that the empirical mean
, the Weak Law of Large Numbers asserts that the empirical mean  converges in distribution to
converges in distribution to 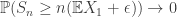 . In fact, if
. In fact, if  , we have the Central Limit Theorem, and a consequence is that
, we have the Central Limit Theorem, and a consequence is that 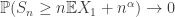 whenever
whenever 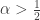 .
. tends to zero. So the probability that at least
tends to zero. So the probability that at least 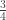 of the results are heads tends to zero. But how fast? Consider first four tosses, then eight. A quick addition of the relevant terms in the binomial distribution gives:
of the results are heads tends to zero. But how fast? Consider first four tosses, then eight. A quick addition of the relevant terms in the binomial distribution gives: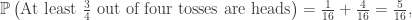

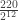 is substantially larger than the rest of the sum. So by far the most likely way for at least
is substantially larger than the rest of the sum. So by far the most likely way for at least 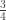 out of twelve tosses to be heads is if exactly
out of twelve tosses to be heads is if exactly 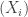 be i.i.d. real-valued random variables which satisfy
be i.i.d. real-valued random variables which satisfy 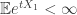 for every
for every 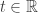 . Then for any
. Then for any 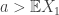 ,
,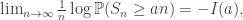
![\text{where}\quad I(z):=\sup_{t\in\mathbb{R}}\left[zt-\log\mathbb{E}e^{tX_1}\right].](https://s0.wp.com/latex.php?latex=%5Ctext%7Bwhere%7D%5Cquad+I%28z%29%3A%3D%5Csup_%7Bt%5Cin%5Cmathbb%7BR%7D%7D%5Cleft%5Bzt-%5Clog%5Cmathbb%7BE%7De%5E%7BtX_1%7D%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
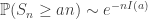 .
.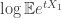 .
.![I(z)\in[0,\infty]](https://s0.wp.com/latex.php?latex=I%28z%29%5Cin%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. to be supported on
to be supported on 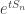 , then optimising over the choice of t. This idea is referred to by various sources as the exponential Chebyshev inequality or a Chernoff bound. The lower bound is more challenging. We reweight the distribution function F(x) of
, then optimising over the choice of t. This idea is referred to by various sources as the exponential Chebyshev inequality or a Chernoff bound. The lower bound is more challenging. We reweight the distribution function F(x) of  by a factor
by a factor 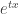 , then choose t so that the large deviation event is in fact now within the treatment of the CLT, from which suitable bounds are obtained.
, then choose t so that the large deviation event is in fact now within the treatment of the CLT, from which suitable bounds are obtained.